Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
2405.11067
0
0
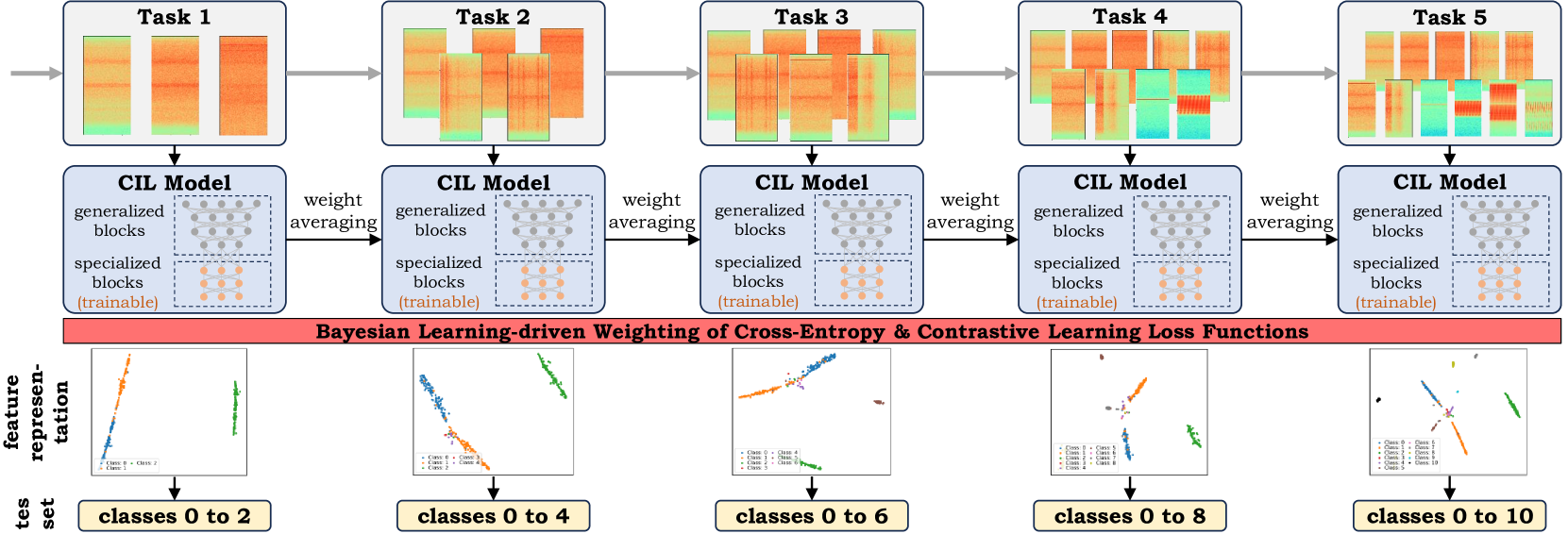
Abstract
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Create account to get full access
Overview
This research paper proposes a novel Bayesian Learning-driven Prototypical Contrastive Loss (BPCL) approach for class-incremental learning. Class-incremental learning is the challenge of training a model to learn new classes of data over time without forgetting previously learned classes. The key ideas behind BPCL are:
- Using Bayesian learning to capture class relationships and uncertainty
- Applying a prototypical contrastive loss to learn class representations that are distinct yet cohesive
- Combining these techniques to enable efficient and robust class-incremental learning
Plain English Explanation
The core problem this paper addresses is how to continuously train an AI model to recognize new categories of objects or concepts over time, without forgetting what it has learned before. This is a common challenge in real-world applications where the data and requirements for a model may evolve over time.
The researchers developed a new technique called Bayesian Learning-driven Prototypical Contrastive Loss (BPCL). The key ideas are:
-
Bayesian Learning: The model uses "Bayesian learning" to understand the relationships and uncertainty between different classes of data. This helps the model learn new classes without catastrophically forgetting old ones.
-
Prototypical Contrastive Loss: The model also uses a "prototypical contrastive loss" to learn distinct yet cohesive representations for each class. This ensures the model can clearly differentiate between classes, even as new ones are added.
By combining these Bayesian and contrastive techniques, the BPCL approach is able to efficiently and robustly handle the challenge of class-incremental learning - continuously expanding the model's capabilities without degrading its previous knowledge. This has important real-world applications in areas like computer vision and multi-label classification.
Technical Explanation
The BPCL approach combines two key innovations to address class-incremental learning:
-
Bayesian Learning-driven Prototypical Embeddings: The model uses Bayesian learning to capture class relationships and uncertainty. This is done by learning a set of prototypical embeddings, one for each class, along with a Gaussian distribution around each prototype. This allows the model to reason about similarities and differences between classes in a probabilistic manner.
-
Prototypical Contrastive Loss: To ensure the prototypical embeddings are distinct yet cohesive, the researchers apply a prototypical contrastive loss. This loss function encourages the model to push embeddings of the same class closer together, while pulling embeddings of different classes further apart. This helps the model maintain robust class representations as new classes are introduced.
The paper evaluates BPCL on standard class-incremental learning benchmarks, comparing it to a range of existing techniques like feature expansion, probabilistic contrastive learning, and continual learning with distillation. The results demonstrate that BPCL achieves state-of-the-art performance, validating the effectiveness of its Bayesian and contrastive learning approach.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the BPCL approach, exploring its performance across a range of class-incremental learning benchmarks. However, the authors acknowledge some limitations:
- The current BPCL implementation is computationally more expensive than some simpler baselines, due to the overhead of Bayesian learning and prototype maintenance.
- The paper focuses on image classification tasks, and it's unclear how well BPCL would generalize to other domains like natural language processing or multi-label classification.
Additionally, while the paper makes a strong case for the effectiveness of BPCL, there may be other promising directions for class-incremental learning that were not explored, such as meta-learning or adversarial training techniques. Further research in this area could lead to even more efficient and robust solutions.
Conclusion
Overall, this paper presents an innovative Bayesian Learning-driven Prototypical Contrastive Loss approach that significantly advances the state-of-the-art in class-incremental learning. By leveraging Bayesian reasoning and contrastive representation learning, BPCL is able to continuously expand a model's capabilities while maintaining its previous knowledge. This has important implications for a wide range of real-world AI applications that require flexible and adaptive learning. While the current implementation has some limitations, the core ideas behind BPCL are a valuable contribution to the field of continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
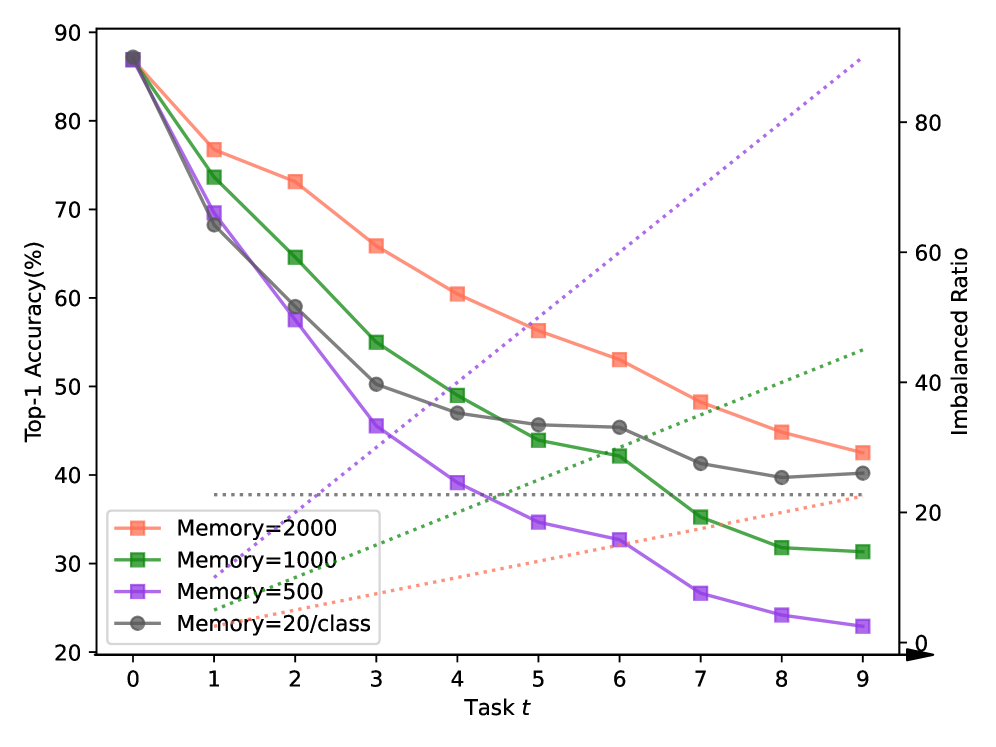
Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective
Leyuan Wang, Liuyu Xiang, Yunlong Wang, Huijia Wu, Zhaofeng He
0
0
Deep neural networks suffer from catastrophic forgetting when continually learning new concepts. In this paper, we analyze this problem from a data imbalance point of view. We argue that the imbalance between old task and new task data contributes to forgetting of the old tasks. Moreover, the increasing imbalance ratio during incremental learning further aggravates the problem. To address the dynamic imbalance issue, we propose Uniform Prototype Contrastive Learning (UPCL), where uniform and compact features are learned. Specifically, we generate a set of non-learnable uniform prototypes before each task starts. Then we assign these uniform prototypes to each class and guide the feature learning through prototype contrastive learning. We also dynamically adjust the relative margin between old and new classes so that the feature distribution will be maintained balanced and compact. Finally, we demonstrate through extensive experiments that the proposed method achieves state-of-the-art performance on several benchmark datasets including CIFAR100, ImageNet100 and TinyImageNet.
5/27/2024

Provable Contrastive Continual Learning
Yichen Wen, Zhiquan Tan, Kaipeng Zheng, Chuanlong Xie, Weiran Huang
0
0
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
5/30/2024
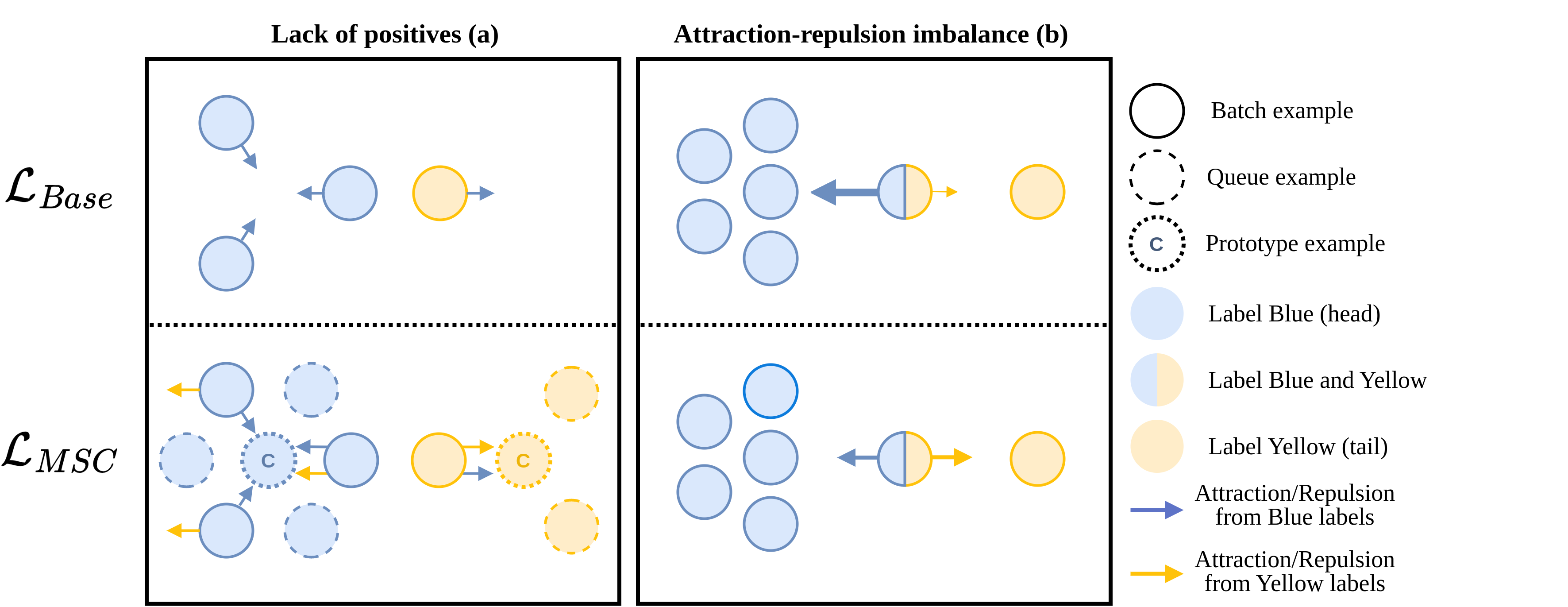
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
0
0
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
4/16/2024

Simple-Sampling and Hard-Mixup with Prototypes to Rebalance Contrastive Learning for Text Classification
Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Xiaoyue Feng, Renchu Guan
0
0
Text classification is a crucial and fundamental task in natural language processing. Compared with the previous learning paradigm of pre-training and fine-tuning by cross entropy loss, the recently proposed supervised contrastive learning approach has received tremendous attention due to its powerful feature learning capability and robustness. Although several studies have incorporated this technique for text classification, some limitations remain. First, many text datasets are imbalanced, and the learning mechanism of supervised contrastive learning is sensitive to data imbalance, which may harm the model performance. Moreover, these models leverage separate classification branch with cross entropy and supervised contrastive learning branch without explicit mutual guidance. To this end, we propose a novel model named SharpReCL for imbalanced text classification tasks. First, we obtain the prototype vector of each class in the balanced classification branch to act as a representation of each class. Then, by further explicitly leveraging the prototype vectors, we construct a proper and sufficient target sample set with the same size for each class to perform the supervised contrastive learning procedure. The empirical results show the effectiveness of our model, which even outperforms popular large language models across several datasets.
5/21/2024