$textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
2405.17258
0
0

Abstract
Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
Create account to get full access
Overview
- This paper introduces Trans-LoRA, a novel technique for parameter-efficient fine-tuning of large language models (LLMs) that can transfer to new tasks without requiring additional training data.
- Trans-LoRA builds on the existing LoRA technique, which uses low-rank adaptation to fine-tune LLMs with a small number of trainable parameters.
- The key innovation in Trans-LoRA is the ability to transfer the LoRA parameters to new tasks, enabling efficient fine-tuning without the need for task-specific training data.
Plain English Explanation
Trans-LoRA is a new way to fine-tune large language models (LLMs) like GPT-3 or BERT for specific tasks. Fine-tuning is the process of adjusting an LLM's parameters to perform well on a particular task, like answering questions or generating text.
Typically, fine-tuning requires a lot of task-specific training data, which can be expensive and time-consuming to obtain. Trans-LoRA solves this problem by using a technique called "low-rank adaptation" (LoRA) to fine-tune the LLM with only a small number of additional parameters.
The key advantage of Trans-LoRA is that the LoRA parameters learned for one task can be transferred to a new task, without needing any additional training data. This makes it much easier and more efficient to adapt LLMs to different applications, such as customer support chatbots, language translation, or text summarization.
Technical Explanation
The Trans-LoRA technique builds on the existing LoRA method, which uses low-rank adaptation to fine-tune LLMs with a small number of trainable parameters. In LoRA, the model's weights are decomposed into a base set of parameters and a low-rank adaptation matrix, which is learned during fine-tuning.
The key innovation in Trans-LoRA is the ability to transfer these LoRA parameters to new tasks, enabling efficient fine-tuning without the need for task-specific training data. This is achieved by learning a "transformation matrix" that maps the LoRA parameters from one task to another, which can be efficiently applied to the base LLM.
The authors demonstrate the effectiveness of Trans-LoRA through extensive experiments on a variety of language tasks, including text classification, question answering, and natural language inference. They show that Trans-LoRA can achieve comparable performance to full fine-tuning while using orders of magnitude fewer trainable parameters.
Critical Analysis
The Trans-LoRA paper presents a promising approach for efficient and transferable fine-tuning of LLMs. The ability to reuse LoRA parameters across tasks can significantly reduce the data and compute requirements for adapting LLMs to new applications, which is an important practical challenge.
However, the paper does not fully address the potential limitations and caveats of the Trans-LoRA approach. For example, it is unclear how well the technique will scale to a wide range of diverse tasks, or how sensitive it is to the specific pre-trained LLM being used. Additionally, the paper does not explore the potential for negative transfer, where the transferred LoRA parameters actually degrade performance on the target task.
Further research is needed to understand the broader applicability and limitations of Trans-LoRA, as well as to explore potential improvements or alternatives that could address these issues. Nonetheless, the core idea of enabling data-free, parameter-efficient fine-tuning through transfer learning is a significant contribution to the field of efficient LLM adaptation.
Conclusion
The Trans-LoRA paper introduces an innovative technique for fine-tuning large language models that can transfer to new tasks without requiring additional training data. By building on the LoRA method for parameter-efficient fine-tuning, Trans-LoRA enables efficient adaptation of LLMs to a wide range of applications, with the potential to significantly reduce the cost and effort required for deploying these powerful models in real-world scenarios.
While the paper presents promising results, further research is needed to fully understand the limits and potential of the Trans-LoRA approach. Nonetheless, this work represents an important step towards more efficient and accessible LLM fine-tuning, which could have significant implications for the broader field of natural language processing and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
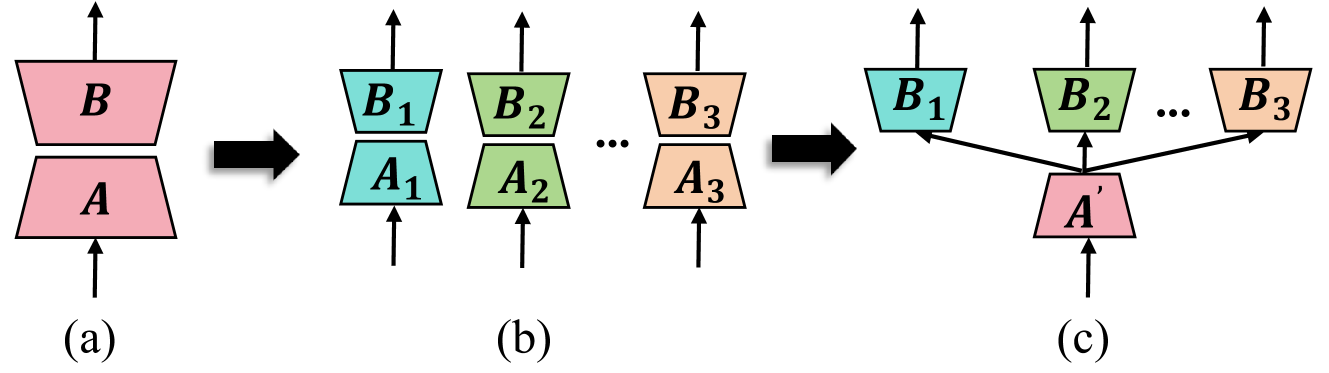
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, Chengzhong Xu
0
0
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases.
5/24/2024
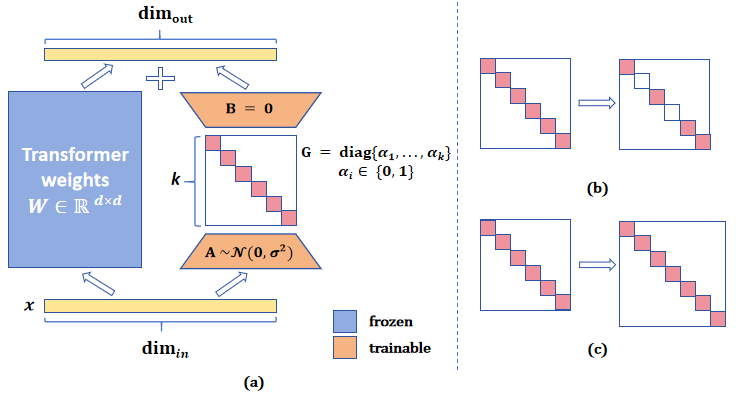
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
🐍
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
Yang Li, Shaobo Han, Shihao Ji
0
0
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a divide-and-share paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
5/29/2024