VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
2405.15179
0
0
🐍
Abstract
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a divide-and-share paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
Create account to get full access
Overview
- The provided paper presents a detailed analysis of hyperparameter settings and computing resources used for natural language understanding experiments on the GLUE benchmark.
- It covers topics such as training time, GPU memory usage, and other important factors that influence the performance of language models.
- The paper aims to provide a comprehensive reference for researchers working on similar natural language processing tasks.
Plain English Explanation
This research paper looks at the different settings and resources used when training language models on a widely used benchmark called GLUE. GLUE is a collection of natural language understanding tasks that researchers use to evaluate the performance of their models.
The key things the paper examines are:
- How long it takes to train the models
- How much computer memory (GPU memory) is required
- Other important hyperparameters and settings that affect the models' performance
By understanding these details, researchers can better plan and design their experiments when working on natural language processing projects. This information can help them choose the right hardware, set appropriate training times, and fine-tune their models more effectively. [The insights from this paper could be particularly useful for researchers working on LORA, HydraLORA, MORA, or other parameter-efficient fine-tuning techniques for large language models.]
Technical Explanation
The paper provides a detailed table of hyperparameter settings and computing resources used for natural language understanding experiments on the GLUE benchmark. The table includes information on:
- Training time (reported as "query and value only" / "all linear modules")
- GPU memory usage (also reported as "query and value only" / "all linear modules")
- Other hyperparameters such as batch size, sequence length, and the number of training steps
The authors collected this data by running a variety of language models, including large transformer-based models, on the GLUE tasks. By reporting these technical details, the paper aims to serve as a reference for other researchers working on similar natural language processing problems.
[The information in this paper could be particularly useful for researchers exploring techniques like LORA, HydraLORA, MORA, and other parameter-efficient fine-tuning methods, as it provides insights into the computational resources required for training large language models.]
Critical Analysis
The paper provides a valuable resource for researchers working on natural language understanding, but it does not address certain limitations or potential issues with the reported findings.
For example, the paper does not discuss how the choice of hyperparameters and computing resources may have impacted the final performance of the language models on the GLUE benchmark. It would be helpful to understand if certain hyperparameter settings or hardware configurations led to better or worse results, and how this might inform the design of future experiments.
Additionally, the paper does not explore the potential trade-offs between training time, GPU memory usage, and model performance. Researchers may be interested in understanding if there are ways to optimize the resource consumption without significantly sacrificing model quality.
[While the insights from this paper could be useful for researchers working on parameter-efficient fine-tuning techniques, it would be important to consider how the reported findings relate to the specific characteristics and requirements of these methods.]
Conclusion
This research paper provides a comprehensive reference for the hyperparameter settings and computing resources used in natural language understanding experiments on the GLUE benchmark. By reporting these technical details, the authors aim to help researchers better plan and design their own experiments in this domain.
The information in this paper could be particularly useful for researchers working on a variety of natural language processing tasks, as it offers insights into the computational requirements and tradeoffs involved in training large language models. However, the paper does not address certain limitations, such as the impact of hyperparameter choices on model performance, which could be an area for further exploration.
Overall, this paper serves as a valuable resource for the natural language processing community, and its findings could help advance the state of the art in language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
LoRA-XS: Low-Rank Adaptation with Extremely Small Number of Parameters
Klaudia Ba{l}azy, Mohammadreza Banaei, Karl Aberer, Jacek Tabor
0
0
The recent trend in scaling language models has led to a growing demand for parameter-efficient tuning (PEFT) methods such as LoRA (Low-Rank Adaptation). LoRA consistently matches or surpasses the full fine-tuning baseline with fewer parameters. However, handling numerous task-specific or user-specific LoRA modules on top of a base model still presents significant storage challenges. To address this, we introduce LoRA-XS (Low-Rank Adaptation with eXtremely Small number of parameters), a novel approach leveraging Singular Value Decomposition (SVD) for parameter-efficient fine-tuning. LoRA-XS introduces a small r x r weight matrix between frozen LoRA matrices, which are constructed by SVD of the original weight matrix. Training only r x r weight matrices ensures independence from model dimensions, enabling more parameter-efficient fine-tuning, especially for larger models. LoRA-XS achieves a remarkable reduction of trainable parameters by over 100x in 7B models compared to LoRA. Our benchmarking across various scales, including GLUE, GSM8k, and MATH benchmarks, shows that our approach outperforms LoRA and recent state-of-the-art approaches like VeRA in terms of parameter efficiency while maintaining competitive performance.
5/29/2024
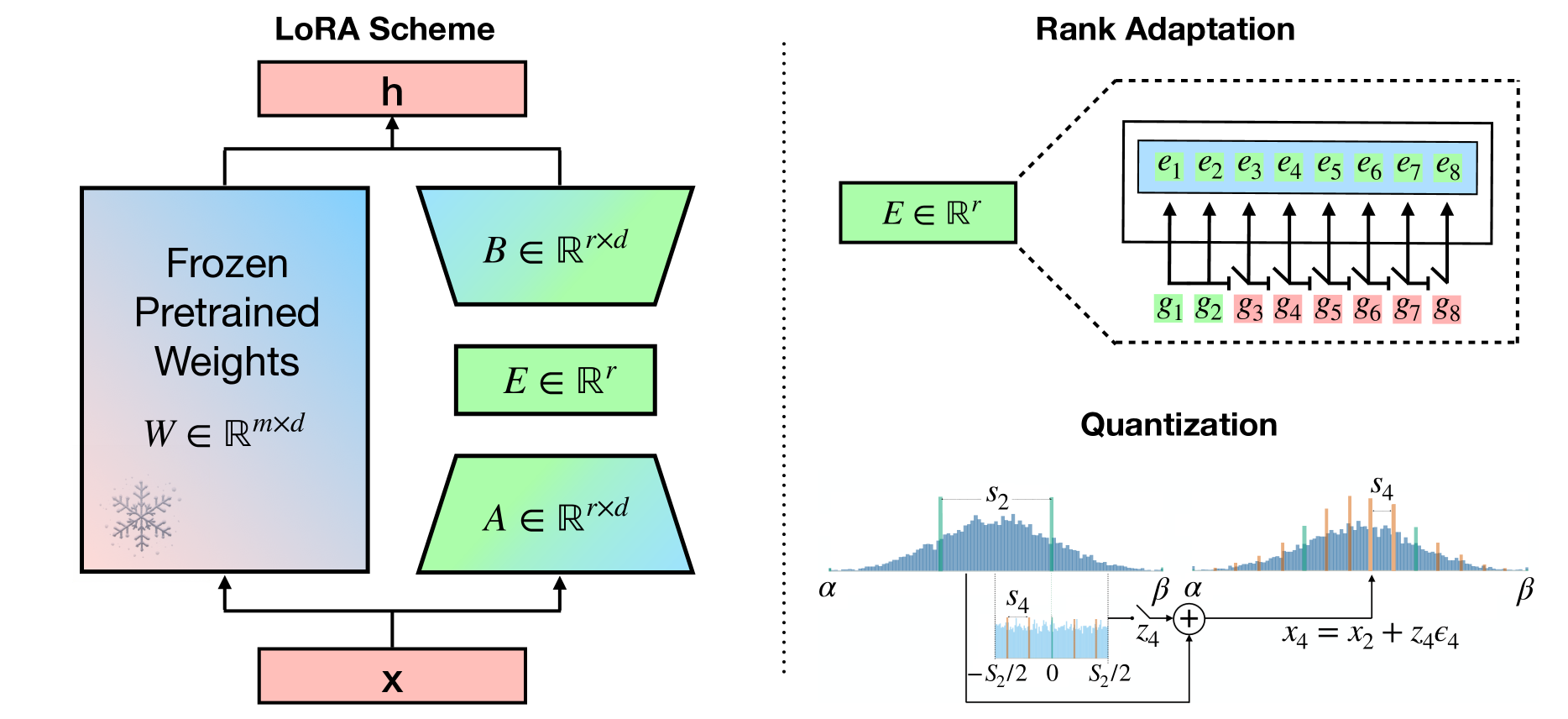
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Cristian Meo, Ksenia Sycheva, Anirudh Goyal, Justin Dauwels
0
0
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.
6/21/2024

$textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
Runqian Wang, Soumya Ghosh, David Cox, Diego Antognini, Aude Oliva, Rogerio Feris, Leonid Karlinsky
0
0
Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.
5/28/2024
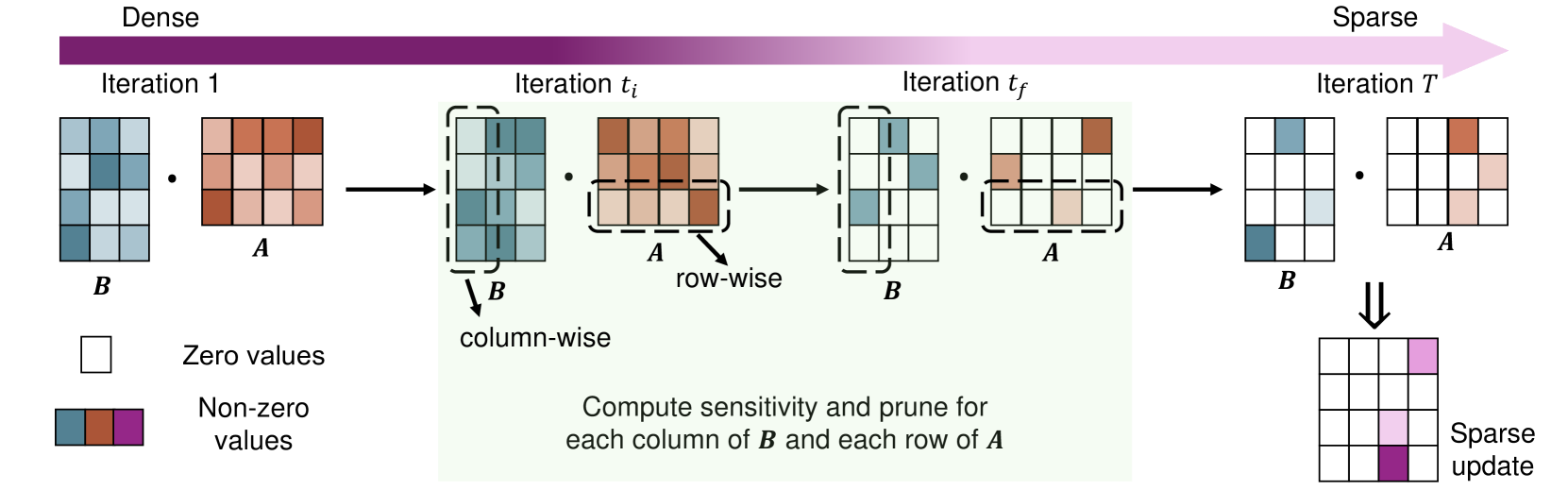
RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning
Haoyu Wang, Tianci Liu, Tuo Zhao, Jing Gao
0
0
Pre-trained language models, trained on large-scale corpora, demonstrate strong generalizability across various NLP tasks. Fine-tuning these models for specific tasks typically involves updating all parameters, which is resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as the popular LoRA family, introduce low-rank matrices to learn only a few parameters efficiently. However, during inference, the product of these matrices updates all pre-trained parameters, complicating tasks like knowledge editing that require selective updates. We propose a novel PEFT method, which conducts textbf{r}ow and ctextbf{o}lumn-wise spartextbf{se} textbf{lo}w-textbf{r}ank textbf{a}daptation (RoseLoRA), to address this challenge. RoseLoRA identifies and updates only the most important parameters for a specific task, maintaining efficiency while preserving other model knowledge. By adding a sparsity constraint on the product of low-rank matrices and converting it to row and column-wise sparsity, we ensure efficient and precise model updates. Our theoretical analysis guarantees the lower bound of the sparsity with respective to the matrix product. Extensive experiments on five benchmarks across twenty datasets demonstrate that RoseLoRA outperforms baselines in both general fine-tuning and knowledge editing tasks.
6/18/2024