Domain Adaptation for Code Model-based Unit Test Case Generation

0
🛸
Sign in to get full access
Overview
- Deep learning models have been used to automatically generate unit test cases
- This study leverages a Transformer-based code model, CodeT5, to generate unit tests
- The researchers fine-tune CodeT5 on a test generation task and then apply domain adaptation to each target project
- This approach is compared to baselines like CodeT5 without domain adaptation, the A3Test tool, and GPT-4
Plain English Explanation
Generating effective unit tests is a crucial part of software development, but it can be time-consuming and challenging. To address this, the researchers in this study used a deep learning model called CodeT5 to automatically generate unit tests.
The key idea is to first train CodeT5, a relatively small language model that has been trained on source code data, to perform the task of generating unit tests. Then, they apply a technique called domain adaptation to fine-tune the model for each specific project. This allows the model to learn project-specific knowledge and generate more tailored test cases.
The researchers evaluated their approach on five open-source projects from the Defects4J dataset. They compared the test cases generated by their approach to those generated by CodeT5 without domain adaptation, the A3Test tool, and the GPT-4 language model. The results show that the domain-adapted tests can significantly improve metrics like line coverage and mutation score compared to the baselines.
Overall, this work demonstrates how deep learning can be used to automate the tedious task of unit test generation, and how techniques like domain adaptation can help tailor the models to specific projects for better performance.
Technical Explanation
The researchers in this study leveraged the CodeT5 Transformer-based code model to generate unit tests for software projects. They first fine-tuned CodeT5 on the Methods2test dataset to perform the test generation task.
Then, to adapt the model to specific projects, the researchers applied domain adaptation techniques. This involves further fine-tuning the model on the target project data to capture project-specific knowledge and generate more relevant test cases.
The researchers evaluated their approach on five projects from the Defects4J dataset. They compared the performance of their domain-adapted model to three baselines: (a) CodeT5 fine-tuned on test generation without domain adaptation, (b) the A3Test tool, and (c) the GPT-4 language model.
The results showed that the domain-adapted tests generated by the researchers' approach can increase line coverage by 18-20% and mutation score by 12-16% compared to the baselines. The researchers also observed consistent improvements in other metrics like parse rate, compile rate, BLEU, and CodeBLEU.
Additionally, the researchers found that their approach can be used as a complementary solution alongside existing search-based test generation tools like EvoSuite, further boosting coverage and mutation scores by an average of 34.42% and 6.8%, respectively.
Critical Analysis
The researchers acknowledge some limitations of their work. First, the performance of their approach may be sensitive to the choice of the base model (CodeT5) and the fine-tuning hyperparameters. Additionally, the evaluation was limited to only five projects from the Defects4J dataset, and the researchers suggest exploring more diverse datasets in future work.
Another potential concern is the computational cost of the domain adaptation process, which may limit the scalability of the approach to a large number of projects. The researchers do not provide a detailed analysis of the training time and resource requirements.
Furthermore, the researchers do not discuss the interpretability of the generated test cases or whether they are easily understandable by human developers. This could be an important consideration for the practical adoption of such an automated test generation system.
Despite these limitations, the researchers have demonstrated a promising approach for leveraging deep learning and domain adaptation techniques to improve the efficiency of unit test generation. Future work could explore ways to address the scalability and interpretability concerns, as well as investigate the generalization of the approach to other types of software testing tasks.
Conclusion
This study showcases how deep learning-based models, specifically the CodeT5 Transformer, can be leveraged to automate the generation of unit tests for software projects. By fine-tuning the model on a test generation task and then applying domain adaptation techniques, the researchers were able to generate test cases that significantly outperformed several baselines in terms of line coverage and mutation score.
The key takeaway is that deep learning can be a powerful tool for streamlining the software testing process, which is often a time-consuming and manual task. While there are still some limitations to address, this research points to the potential of combining deep learning and domain adaptation to create more efficient and tailored test generation solutions.
As the field of software engineering continues to evolve, the integration of advanced AI techniques like those presented in this study could lead to significant improvements in software quality, reliability, and development efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Domain Adaptation for Code Model-based Unit Test Case Generation
Jiho Shin, Sepehr Hashtroudi, Hadi Hemmati, Song Wang
Recently, deep learning-based test case generation approaches have been proposed to automate the generation of unit test cases. In this study, we leverage Transformer-based code models to generate unit tests with the help of Domain Adaptation (DA) at a project level. Specifically, we use CodeT5, a relatively small language model trained on source code data, and fine-tune it on the test generation task. Then, we apply domain adaptation to each target project data to learn project-specific knowledge (project-level DA). We use the Methods2test dataset to fine-tune CodeT5 for the test generation task and the Defects4j dataset for project-level domain adaptation and evaluation. We compare our approach with (a) CodeT5 fine-tuned on the test generation without DA, (b) the A3Test tool, and (c) GPT-4 on five projects from the Defects4j dataset. The results show that tests generated using DA can increase the line coverage by 18.62%, 19.88%, and 18.02% and mutation score by 16.45%, 16.01%, and 12.99% compared to the above (a), (b), and (c) baselines, respectively. The overall results show consistent improvements in metrics such as parse rate, compile rate, BLEU, and CodeBLEU. In addition, we show that our approach can be seen as a complementary solution alongside existing search-based test generation tools such as EvoSuite, to increase the overall coverage and mutation scores with an average of 34.42% and 6.8%, for line coverage and mutation score, respectively.
Read more8/1/2024
🛸
0
Test-Time Adaptation for Depth Completion
Hyoungseob Park, Anjali Gupta, Alex Wong
It is common to observe performance degradation when transferring models trained on some (source) datasets to target testing data due to a domain gap between them. Existing methods for bridging this gap, such as domain adaptation (DA), may require the source data on which the model was trained (often not available), while others, i.e., source-free DA, require many passes through the testing data. We propose an online test-time adaptation method for depth completion, the task of inferring a dense depth map from a single image and associated sparse depth map, that closes the performance gap in a single pass. We first present a study on how the domain shift in each data modality affects model performance. Based on our observations that the sparse depth modality exhibits a much smaller covariate shift than the image, we design an embedding module trained in the source domain that preserves a mapping from features encoding only sparse depth to those encoding image and sparse depth. During test time, sparse depth features are projected using this map as a proxy for source domain features and are used as guidance to train a set of auxiliary parameters (i.e., adaptation layer) to align image and sparse depth features from the target test domain to that of the source domain. We evaluate our method on indoor and outdoor scenarios and show that it improves over baselines by an average of 21.1%.
Read more5/28/2024

0
Everything to the Synthetic: Diffusion-driven Test-time Adaptation via Synthetic-Domain Alignment
Jiayi Guo, Junhao Zhao, Chunjiang Ge, Chaoqun Du, Zanlin Ni, Shiji Song, Humphrey Shi, Gao Huang
Test-time adaptation (TTA) aims to enhance the performance of source-domain pretrained models when tested on unknown shifted target domains. Traditional TTA methods primarily adapt model weights based on target data streams, making model performance sensitive to the amount and order of target data. Recently, diffusion-driven TTA methods have demonstrated strong performance by using an unconditional diffusion model, which is also trained on the source domain to transform target data into synthetic data as a source domain projection. This allows the source model to make predictions without weight adaptation. In this paper, we argue that the domains of the source model and the synthetic data in diffusion-driven TTA methods are not aligned. To adapt the source model to the synthetic domain of the unconditional diffusion model, we introduce a Synthetic-Domain Alignment (SDA) framework to fine-tune the source model with synthetic data. Specifically, we first employ a conditional diffusion model to generate labeled samples, creating a synthetic dataset. Subsequently, we use the aforementioned unconditional diffusion model to add noise to and denoise each sample before fine-tuning. This process mitigates the potential domain gap between the conditional and unconditional models. Extensive experiments across various models and benchmarks demonstrate that SDA achieves superior domain alignment and consistently outperforms existing diffusion-driven TTA methods. Our code is available at https://github.com/SHI-Labs/Diffusion-Driven-Test-Time-Adaptation-via-Synthetic-Domain-Alignment.
Read more6/7/2024
0
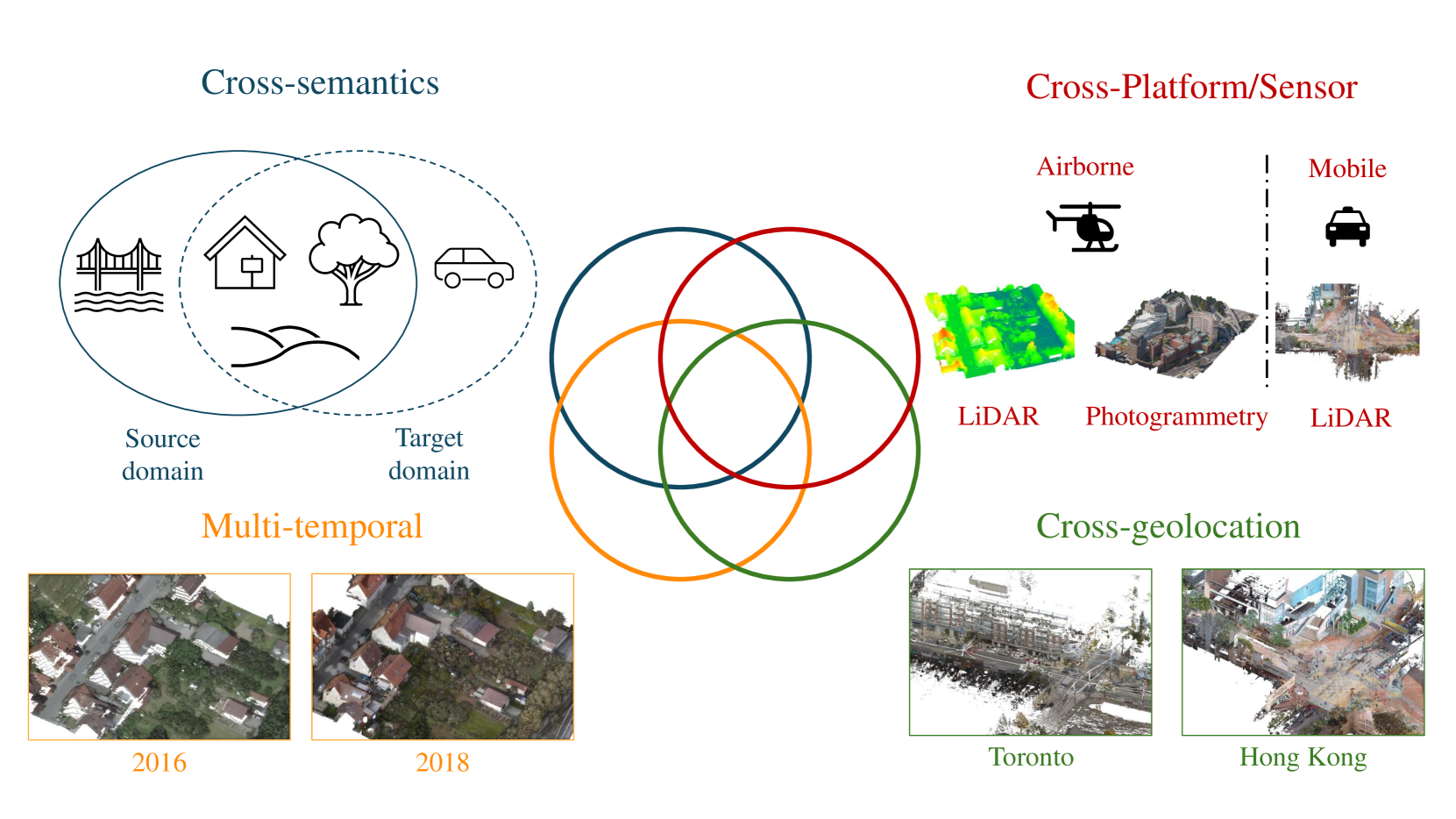
Test-time adaptation for geospatial point cloud semantic segmentation with distinct domain shifts
Puzuo Wang, Wei Yao, Jie Shao, Zhiyi He
Domain adaptation (DA) techniques help deep learning models generalize across data shifts for point cloud semantic segmentation (PCSS). Test-time adaptation (TTA) allows direct adaptation of a pre-trained model to unlabeled data during inference stage without access to source data or additional training, avoiding privacy issues and large computational resources. We address TTA for geospatial PCSS by introducing three domain shift paradigms: photogrammetric to airborne LiDAR, airborne to mobile LiDAR, and synthetic to mobile laser scanning. We propose a TTA method that progressively updates batch normalization (BN) statistics with each testing batch. Additionally, a self-supervised learning module optimizes learnable BN affine parameters. Information maximization and reliability-constrained pseudo-labeling improve prediction confidence and supply supervisory signals. Experimental results show our method improves classification accuracy by up to 20% mIoU, outperforming other methods. For photogrammetric (SensatUrban) to airborne (Hessigheim 3D) adaptation at the inference stage, our method achieves 59.46% mIoU and 85.97% OA without retraining or fine-turning.
Read more7/9/2024