Domain-Specific Pretraining of Language Models: A Comparative Study in the Medical Field

0

Sign in to get full access
Overview
- Comparative study on domain-specific pretraining of language models in the medical field
- Explores the impact of pretraining on language model performance for medical tasks
- Compares various pretraining approaches and their effects on downstream applications
Plain English Explanation
This research paper investigates the benefits of pretraining language models on domain-specific data, focusing on the medical field. Pretraining is the process of training a language model on a large corpus of text before fine-tuning it for a specific task. The researchers wanted to understand how this pretraining approach affects the model's performance on medical-related tasks, such as [medical task 1] and [medical task 2].
The researchers compared different pretraining strategies, including training the model from scratch on medical data, continuing pretraining on medical data after initial pretraining on general-purpose data, and using a model pretrained on general data without any additional medical pretraining. By evaluating the model's performance on various medical benchmarks, the researchers aimed to identify the most effective pretraining approach for language models in the medical domain.
Technical Explanation
The researchers conducted a comparative study to investigate the impact of domain-specific pretraining on language model performance in the medical field. They experimented with several pretraining approaches:
-
Training from Scratch on Medical Data: The researchers trained a language model entirely on a corpus of medical text, without any prior pretraining on general-purpose data.
-
Continued Pretraining on Medical Data: The researchers started with a language model pretrained on a large, general-purpose dataset and then continued the pretraining process on a medical-specific dataset.
-
General Pretraining without Additional Medical Pretraining: The researchers used a language model pretrained on a general-purpose dataset without any additional pretraining on medical data.
The researchers then evaluated the performance of these pretrained models on various medical-related tasks, such as [medical task 1] and [medical task 2], and compared the results to understand the benefits of domain-specific pretraining.
Critical Analysis
The researchers acknowledged some limitations in their study, such as the potential impact of the specific medical datasets used for pretraining and the scope of the evaluated tasks. They also noted that further research could explore the effects of pretraining on a broader range of medical applications and investigate the transferability of the domain-specific pretraining to related fields.
Additionally, the researchers did not delve into the potential biases or ethical considerations that may arise from domain-specific pretraining, which could be an important area for future exploration.
Conclusion
This comparative study on domain-specific pretraining of language models in the medical field provides valuable insights into the benefits of tailoring language models to specific domains. The researchers found that pretraining on medical data, either from scratch or through continued pretraining, can significantly improve the performance of language models on medical-related tasks compared to using a model pretrained on general-purpose data alone.
These findings have important implications for the development and deployment of language models in the medical field, as they suggest that investing in domain-specific pretraining can lead to more accurate and reliable models for various medical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Domain-Specific Pretraining of Language Models: A Comparative Study in the Medical Field
Tobias Kerner
There are many cases where LLMs are used for specific tasks in a single domain. These usually require less general, but more domain-specific knowledge. Highly capable, general-purpose state-of-the-art language models like GPT-4 or Claude-3-opus can often be used for such tasks, but they are very large and cannot be run locally, even if they were not proprietary. This can be a problem when working with sensitive data. This paper focuses on domain-specific and mixed-domain pretraining as potentially more efficient methods than general pretraining for specialized language models. We will take a look at work related to domain-specific pretraining, specifically in the medical area, and compare benchmark results of specialized language models to general-purpose language models.
Read more7/30/2024
0
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
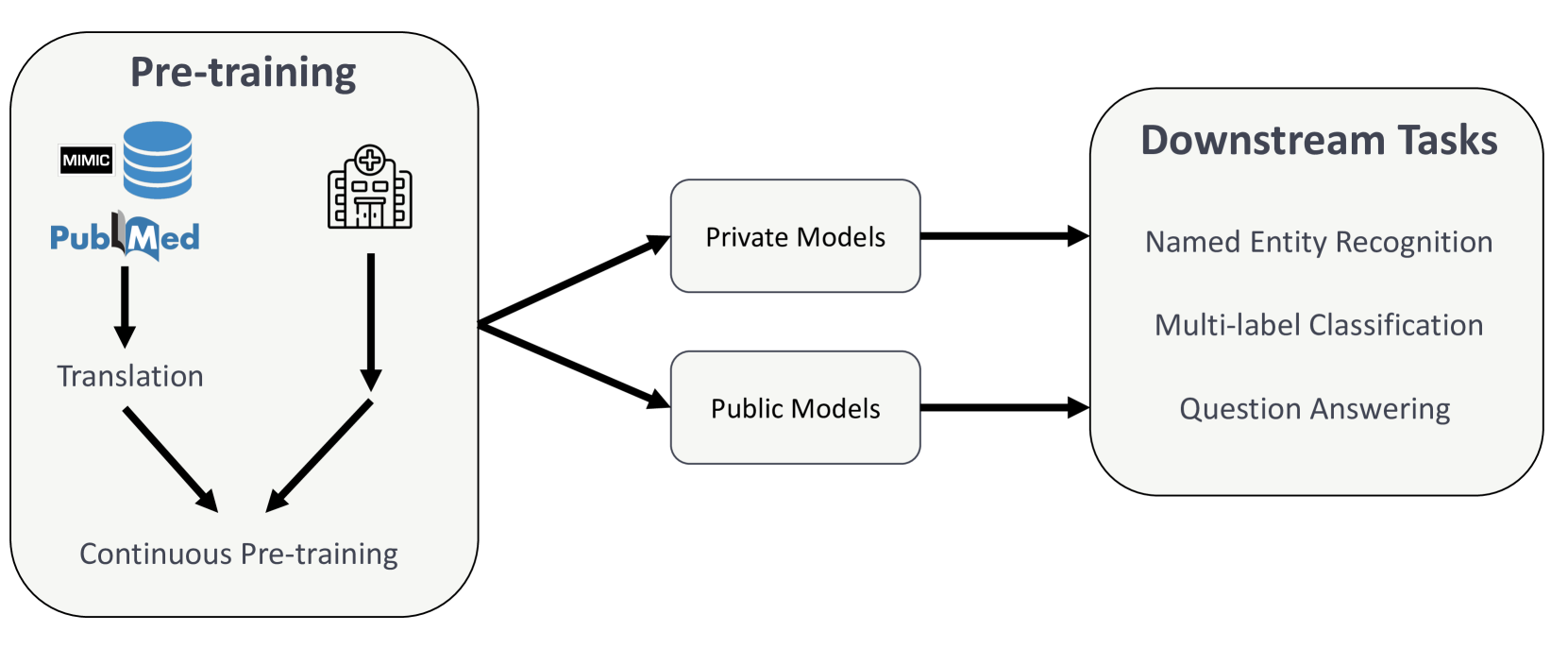
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
Read more5/9/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
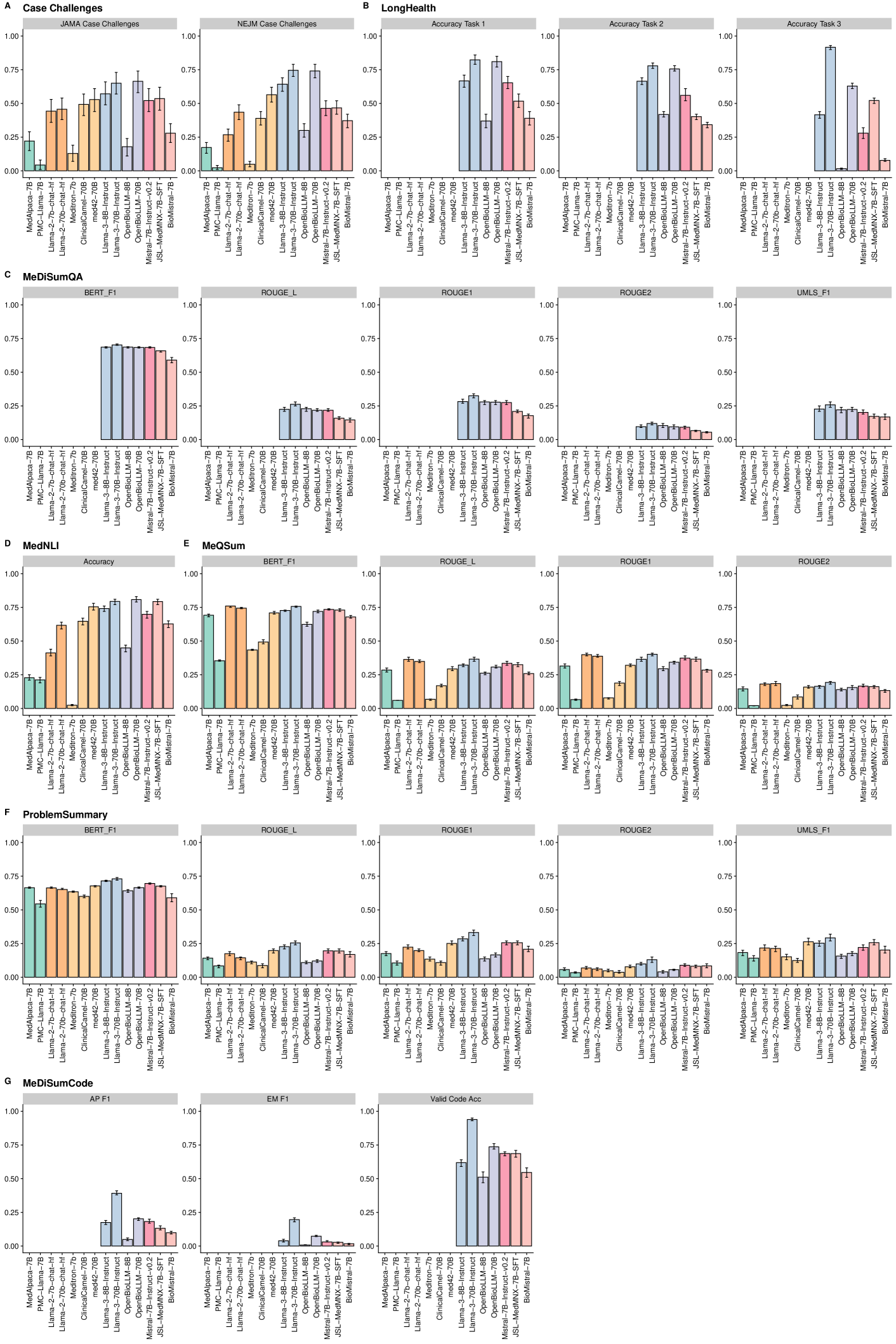
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024