Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization

0

Sign in to get full access
Overview
- The paper explores techniques for enhancing language models with domain-specific knowledge, using vector stores, knowledge graphs, and tensor factorization.
- The key ideas include retrieval-augmented generation, knowledge graph integration, and non-negative tensor factorization for topic modeling.
- The techniques are evaluated on domain-specific tasks and compared to benchmark models.
Plain English Explanation
The paper looks at ways to make language models (like chatbots or writing assistants) more knowledgeable about specific topics. It explores three main techniques:
-
Retrieval-Augmented Generation: The language model can retrieve relevant information from a database or "vector store" to supplement its own knowledge when generating text.
-
Knowledge Graph Integration: The model can use a structured knowledge graph, which organizes information into concepts and their relationships, to enhance its understanding.
-
Non-Negative Tensor Factorization: This is a mathematical technique that can identify important topics and themes in a large amount of text data, which the model can then leverage.
The researchers evaluate these techniques on domain-specific tasks, like generating content for a particular industry or subject area. They compare the performance to existing benchmark models to see how much of an improvement these new approaches can provide.
The key insight is that equipping language models with more targeted knowledge, retrieved from external sources, can make them significantly more capable at generating relevant and informative text for specific use cases.
Technical Explanation
The paper presents a framework for domain-specific retrieval-augmented generation, which combines several techniques to enhance language models with domain-specific knowledge:
-
Vector Stores: The model can retrieve relevant information from a database of embeddings, or numerical representations of text, to augment its own knowledge during generation.
-
Knowledge Graphs: The model integrates structured knowledge graphs, which represent concepts and their relationships, to better understand the context and semantics of the domain.
-
Non-Negative Tensor Factorization: This unsupervised technique is used to identify latent topics and themes within a corpus of domain-specific text, which the model can then leverage.
The researchers evaluate this approach on a variety of domain-specific tasks, such as generating customer service responses or scientific abstracts. They compare the performance to state-of-the-art retrieval-augmented generation models and knowledge-enhanced language models.
The results demonstrate that integrating these domain-specific techniques can significantly improve the relevance, informativeness, and coherence of the generated text compared to baseline models. The proposed Chinese benchmark also provides a standardized way to evaluate domain-specific retrieval-augmented generation capabilities.
Critical Analysis
The paper presents a comprehensive approach to enhancing language models with domain-specific knowledge, but there are a few caveats to consider:
-
Data Dependency: The performance of the techniques relies heavily on the quality and coverage of the underlying data sources, such as the vector store and knowledge graph. Incomplete or biased data could limit the model's capabilities.
-
Scalability: Integrating multiple external knowledge sources and performing tensor factorization may introduce computational challenges, particularly for large-scale deployments.
-
Generalization: While the techniques are evaluated on domain-specific tasks, it's unclear how well they would generalize to broader, more open-ended generation scenarios.
-
Interpretability: The use of complex factorization techniques and black-box retrieval systems can make it harder to understand and explain the model's decision-making process.
Further research could explore ways to address these limitations, such as developing more robust data curation methods, efficient retrieval algorithms, and interpretable hybrid architectures.
Conclusion
This paper presents an innovative approach to enhancing language models with domain-specific knowledge, leveraging techniques like retrieval-augmented generation, knowledge graph integration, and tensor factorization. The results demonstrate significant improvements in the relevance and informativeness of generated text for targeted use cases.
While there are some practical considerations around data quality, scalability, and interpretability, the overall framework offers a promising direction for developing more capable and specialized language models. As the field of natural language processing continues to advance, techniques like these will be crucial for tailoring AI systems to the specific needs of different industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Ryan C. Barron, Ves Grantcharov, Selma Wanna, Maksim E. Eren, Manish Bhattarai, Nicholas Solovyev, George Tompkins, Charles Nicholas, Kim {O}. Rasmussen, Cynthia Matuszek, Boian S. Alexandrov
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
Read more10/4/2024

0
KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
Lei Liang, Mengshu Sun, Zhengke Gui, Zhongshu Zhu, Zhouyu Jiang, Ling Zhong, Yuan Qu, Peilong Zhao, Zhongpu Bo, Jin Yang, Huaidong Xiong, Lin Yuan, Jun Xu, Zaoyang Wang, Zhiqiang Zhang, Wen Zhang, Huajun Chen, Wenguang Chen, Jun Zhou
The recently developed retrieval-augmented generation (RAG) technology has enabled the efficient construction of domain-specific applications. However, it also has limitations, including the gap between vector similarity and the relevance of knowledge reasoning, as well as insensitivity to knowledge logic, such as numerical values, temporal relations, expert rules, and others, which hinder the effectiveness of professional knowledge services. In this work, we introduce a professional domain knowledge service framework called Knowledge Augmented Generation (KAG). KAG is designed to address the aforementioned challenges with the motivation of making full use of the advantages of knowledge graph(KG) and vector retrieval, and to improve generation and reasoning performance by bidirectionally enhancing large language models (LLMs) and KGs through five key aspects: (1) LLM-friendly knowledge representation, (2) mutual-indexing between knowledge graphs and original chunks, (3) logical-form-guided hybrid reasoning engine, (4) knowledge alignment with semantic reasoning, and (5) model capability enhancement for KAG. We compared KAG with existing RAG methods in multihop question answering and found that it significantly outperforms state-of-theart methods, achieving a relative improvement of 19.6% on 2wiki and 33.5% on hotpotQA in terms of F1 score. We have successfully applied KAG to two professional knowledge Q&A tasks of Ant Group, including E-Government Q&A and E-Health Q&A, achieving significant improvement in professionalism compared to RAG methods.
Read more9/27/2024
0
WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs
Weijian Xie, Xuefeng Liang, Yuhui Liu, Kaihua Ni, Hong Cheng, Zetian Hu
Large Language Models (LLMs) have greatly contributed to the development of adaptive intelligent agents and are positioned as an important way to achieve Artificial General Intelligence (AGI). However, LLMs are prone to produce factually incorrect information and often produce phantom content that undermines their reliability, which poses a serious challenge for their deployment in real-world scenarios. Enhancing LLMs by combining external databases and information retrieval mechanisms is an effective path. To address the above challenges, we propose a new approach called WeKnow-RAG, which integrates Web search and Knowledge Graphs into a Retrieval-Augmented Generation (RAG) system. First, the accuracy and reliability of LLM responses are improved by combining the structured representation of Knowledge Graphs with the flexibility of dense vector retrieval. WeKnow-RAG then utilizes domain-specific knowledge graphs to satisfy a variety of queries and domains, thereby improving performance on factual information and complex reasoning tasks by employing multi-stage web page retrieval techniques using both sparse and dense retrieval methods. Our approach effectively balances the efficiency and accuracy of information retrieval, thus improving the overall retrieval process. Finally, we also integrate a self-assessment mechanism for the LLM to evaluate the trustworthiness of the answers it generates. Our approach proves its outstanding effectiveness in a wide range of offline experiments and online submissions.
Read more8/29/2024
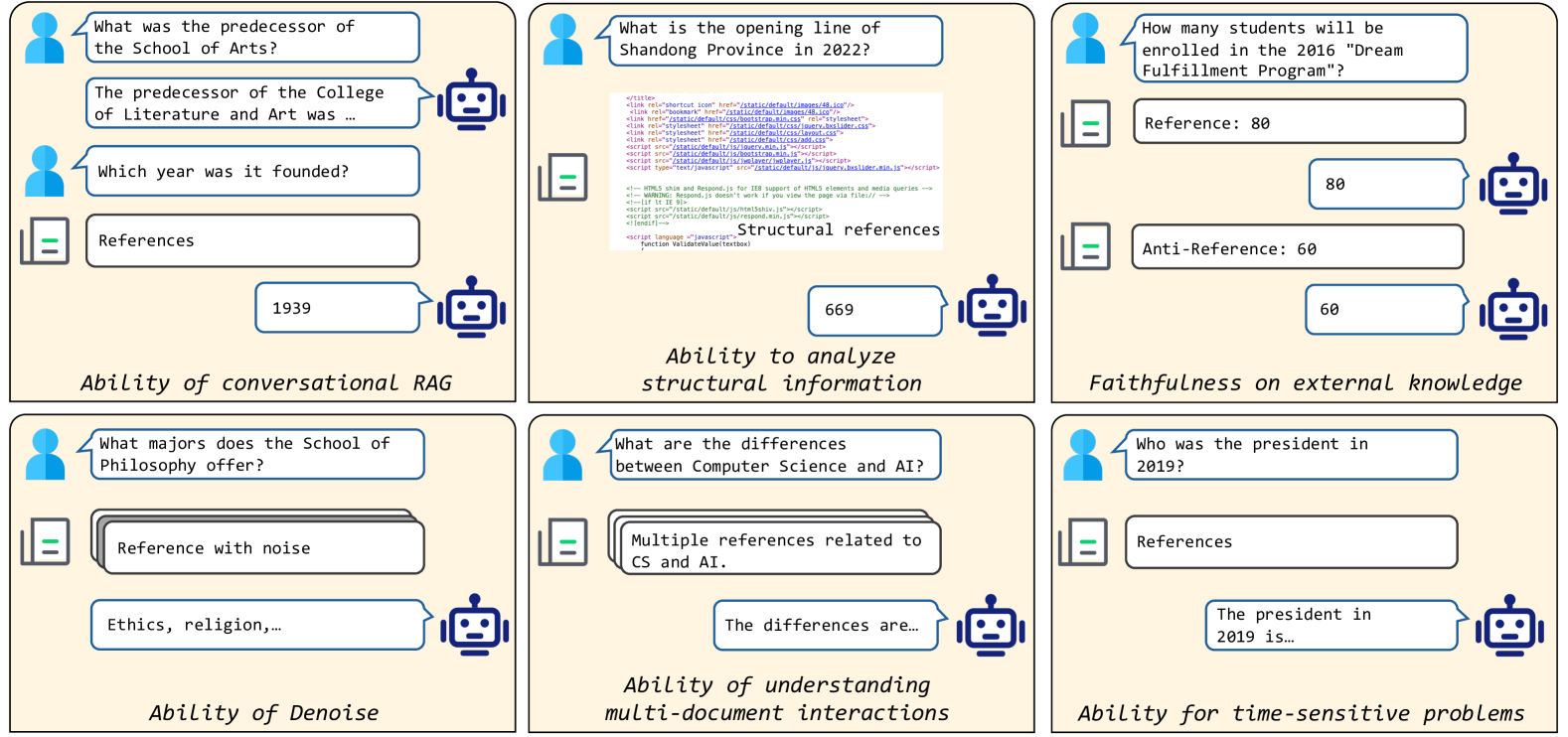
0
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Shuting Wang, Jiongnan Liu, Shiren Song, Jiehan Cheng, Yuqi Fu, Peidong Guo, Kun Fang, Yutao Zhu, Zhicheng Dou
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Read more6/18/2024