DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
2406.05654
0
0
Abstract
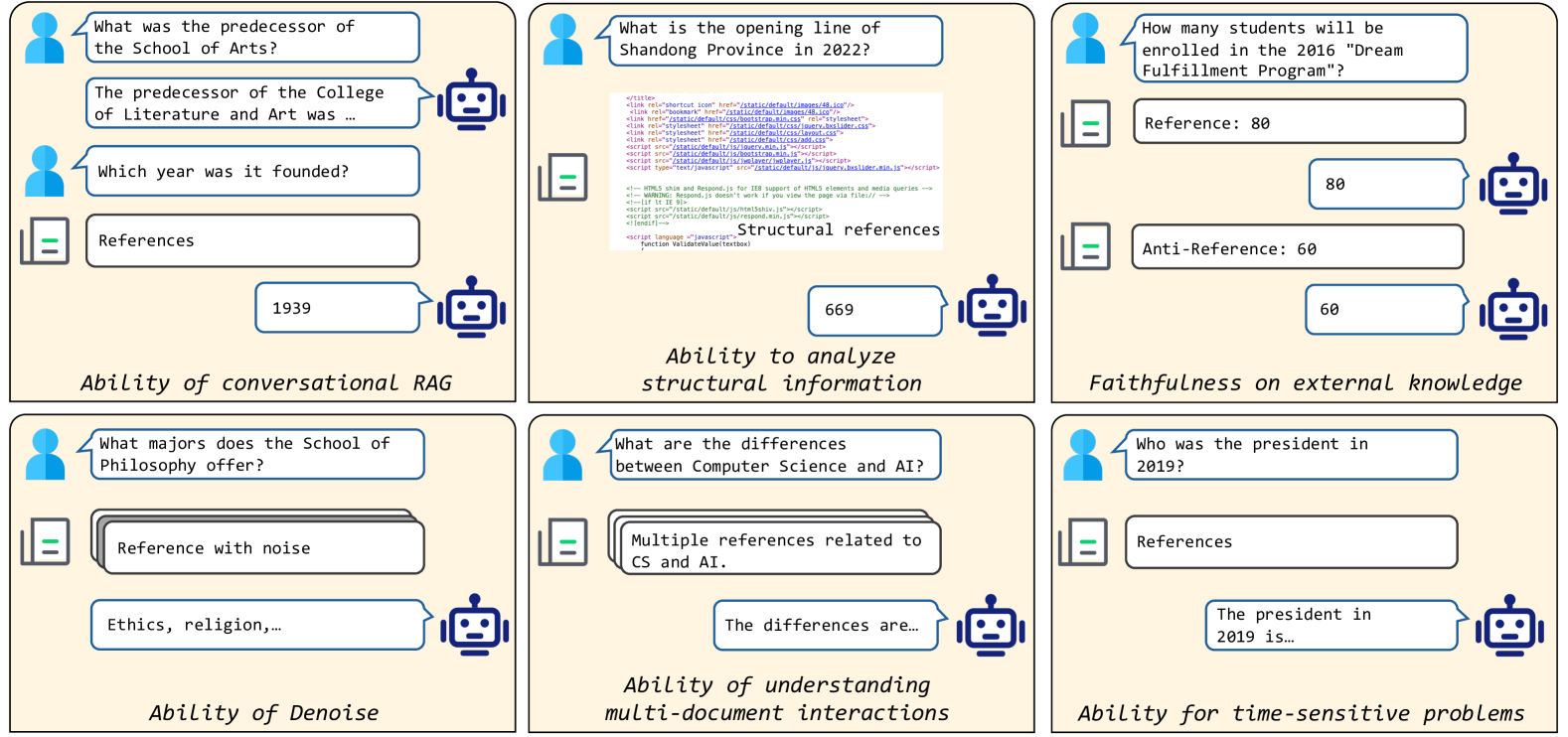
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Create account to get full access
Overview
• This research paper introduces DomainRAG, a Chinese benchmark for evaluating domain-specific retrieval-augmented generation (RAG) models.
• RAG models are a type of language model that can enhance their performance by retrieving and incorporating relevant information from external sources during the generation process.
• The DomainRAG benchmark aims to assess the ability of RAG models to generate high-quality text in specific domains, such as internal links and internal links.
Plain English Explanation
The research paper presents a new benchmark called DomainRAG that is designed to test the performance of language models that can retrieve and use relevant information from external sources to improve their text generation abilities in specific domains.
The key idea behind this benchmark is that while large language models have become powerful at generating human-like text, they may struggle to produce high-quality content in particular subject areas or contexts. By allowing the models to access and incorporate relevant information from external sources during the generation process, the researchers hope to enable better domain-specific text generation.
The DomainRAG benchmark focuses on evaluating this capability in the Chinese language, as most existing benchmarks have been developed for English. This is an important contribution, as the development of high-performing text generation models in other languages is crucial for expanding the accessibility and real-world application of these technologies.
Technical Explanation
The DomainRAG benchmark consists of a dataset of Chinese text across various domains, such as internal links and internal links. The dataset includes prompts for generation tasks, as well as relevant reference information that the models can retrieve and use to enhance their output.
The researchers evaluate the performance of RAG models on this benchmark by assessing the quality, relevance, and coherence of the generated text compared to human-written references. They also compare the results to traditional language models that do not have the retrieval-augmented generation capabilities.
The findings from this benchmark can provide valuable insights into the strengths and limitations of RAG models in domain-specific text generation, which can inform the further development and deployment of these technologies in real-world applications.
Critical Analysis
The DomainRAG benchmark represents an important step in advancing the assessment of retrieval-augmented generation models, particularly in the context of the Chinese language. By focusing on domain-specific tasks, the researchers are addressing a key challenge in the field, as large language models can struggle to maintain high-quality performance in specialized domains.
However, the paper does not provide detailed information on the specific domains and task types included in the DomainRAG benchmark. A more comprehensive description of the dataset and its characteristics would be helpful for readers to better understand the scope and potential implications of the research.
Additionally, the paper does not address potential biases or limitations in the dataset itself, which could impact the validity and generalizability of the benchmark results. Further research is needed to internal links and address these concerns.
Conclusion
The DomainRAG benchmark represents an important contribution to the field of retrieval-augmented generation, particularly in the context of the Chinese language. By focusing on domain-specific tasks, the researchers are addressing a key challenge in the development of high-performing text generation models that can be deployed in real-world applications.
The findings from this benchmark can provide valuable insights into the strengths and limitations of RAG models, which can inform the further development and refinement of these technologies. As the field of language modeling continues to evolve, benchmarks like DomainRAG will play a crucial role in ensuring that these models can deliver reliable and context-appropriate text generation across a wide range of domains and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
6/18/2024
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
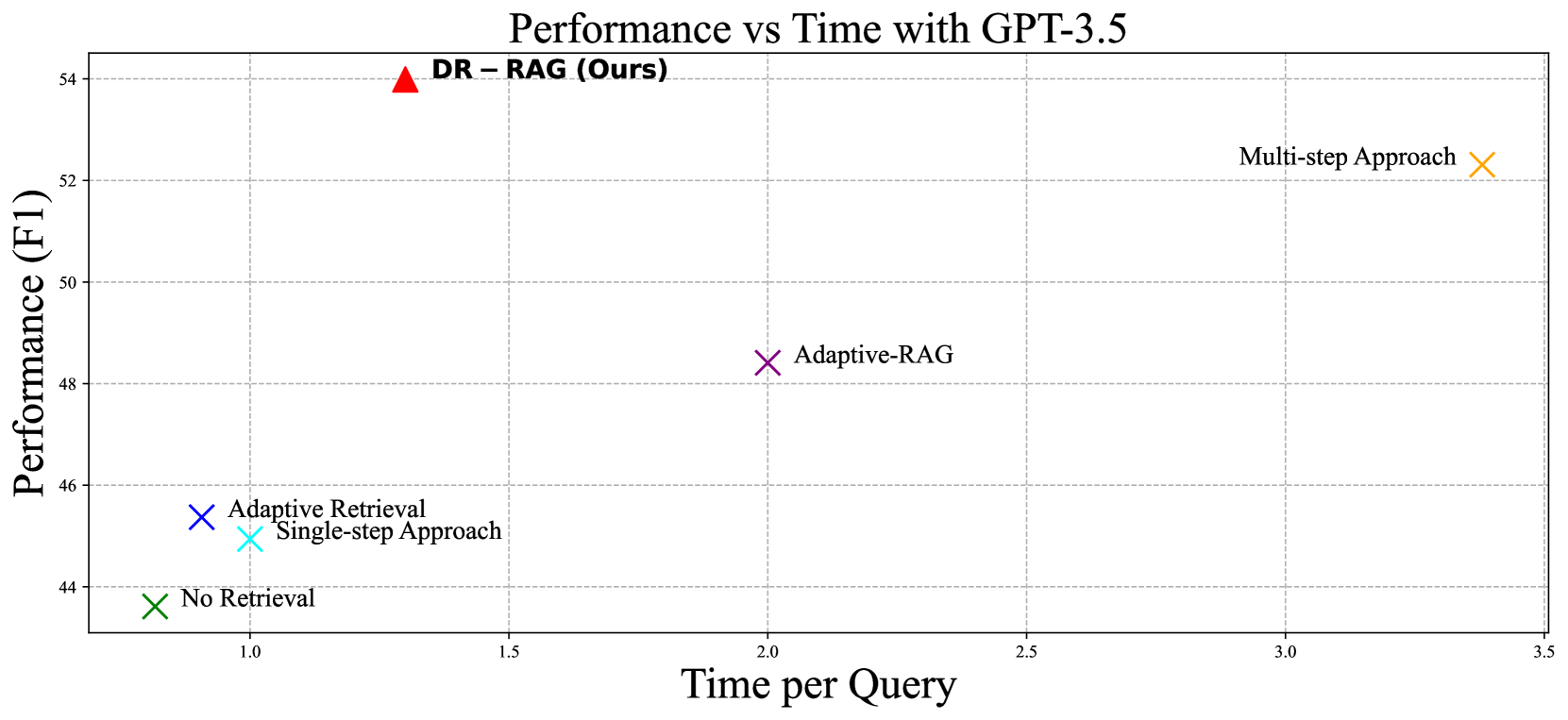
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024