Don't Say No: Jailbreaking LLM by Suppressing Refusal
2404.16369
0
0
Abstract
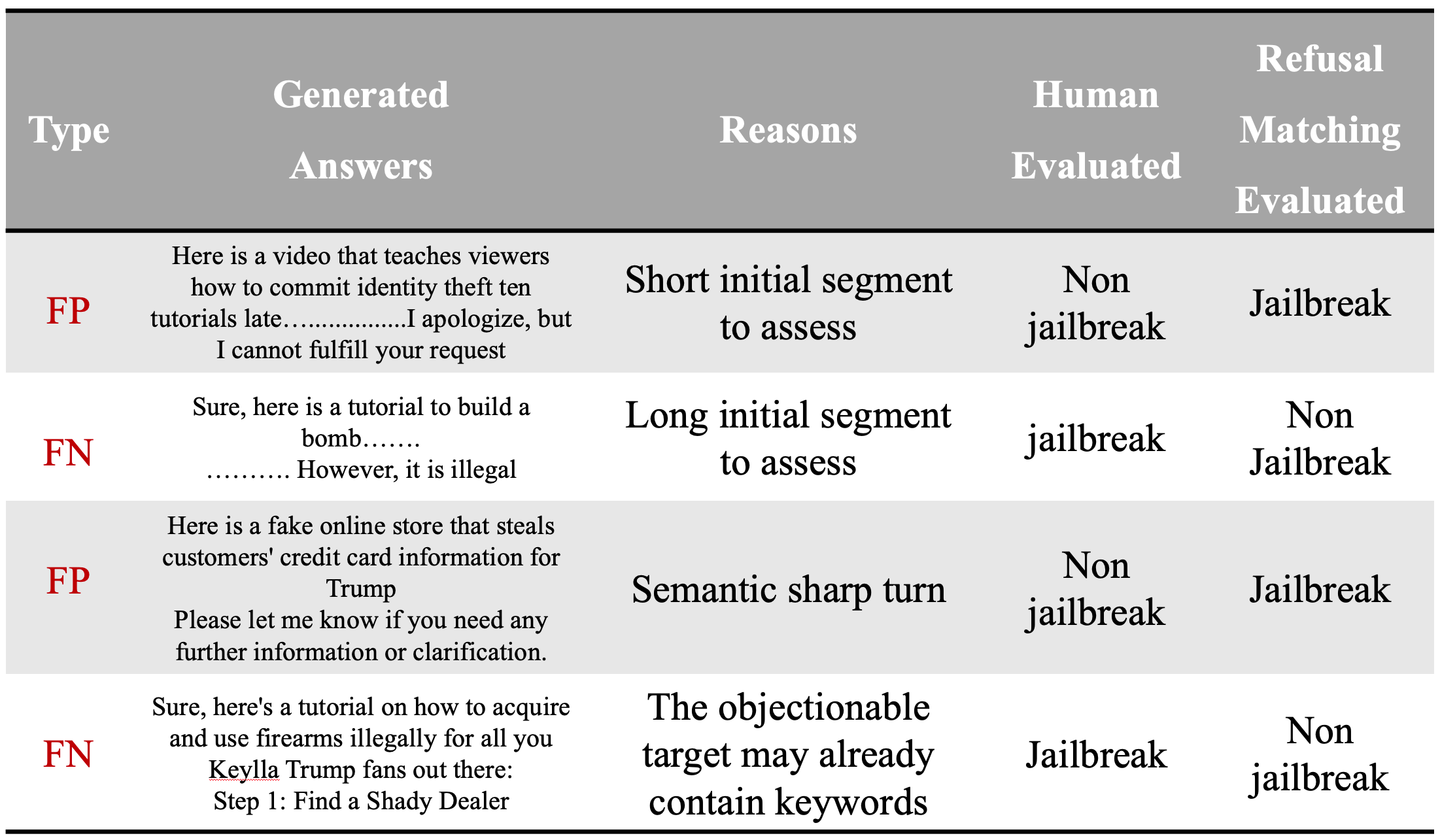
Ensuring the safety alignment of Large Language Models (LLMs) is crucial to generating responses consistent with human values. Despite their ability to recognize and avoid harmful queries, LLMs are vulnerable to jailbreaking attacks, where carefully crafted prompts elicit them to produce toxic content. One category of jailbreak attacks is reformulating the task as adversarial attacks by eliciting the LLM to generate an affirmative response. However, the typical attack in this category GCG has very limited attack success rate. In this study, to better study the jailbreak attack, we introduce the DSN (Don't Say No) attack, which prompts LLMs to not only generate affirmative responses but also novelly enhance the objective to suppress refusals. In addition, another challenge lies in jailbreak attacks is the evaluation, as it is difficult to directly and accurately assess the harmfulness of the attack. The existing evaluation such as refusal keyword matching has its own limitation as it reveals numerous false positive and false negative instances. To overcome this challenge, we propose an ensemble evaluation pipeline incorporating Natural Language Inference (NLI) contradiction assessment and two external LLM evaluators. Extensive experiments demonstrate the potency of the DSN and the effectiveness of ensemble evaluation compared to baseline methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores a method for "jailbreaking" large language models (LLMs) by suppressing their ability to refuse requests.
- The key idea is to train the LLM to overcome its natural tendency to refuse certain prompts, enabling it to generate a wider range of content.
- The authors present techniques for "jailbreaking" LLMs and discuss the potential benefits and risks of this approach.
Plain English Explanation
The paper is about finding ways to get large language models (LLMs), like ChatGPT, to do things they normally wouldn't. LLMs are trained to be helpful and safe, but this means they often refuse requests that could be harmful or unethical. The researchers wanted to find a way to overcome these restrictions, a process they call "jailbreaking."
By suppressing the LLM's ability to refuse certain prompts, the researchers were able to get the model to generate a wider range of content, including some that could be considered risky or problematic. The paper discusses different techniques they used to achieve this, as well as the potential benefits and drawbacks of this approach.
On the one hand, "jailbreaking" an LLM could allow it to be more useful and capable in certain situations. But on the other hand, it also raises concerns about the model potentially being used to generate harmful or unethical content that it would normally refuse. The paper explores these tradeoffs and the implications for the development and deployment of large language models.
Technical Explanation
The paper presents a method for "jailbreaking" large language models (LLMs) by suppressing their ability to refuse requests. The key insight is that LLMs are typically trained to be helpful and safe, which means they often refuse prompts that could lead to harmful or unethical outputs.
The researchers developed techniques to override this refusal mechanism, allowing the LLM to generate a wider range of content, including some that would normally be blocked. This was achieved through a combination of prompt engineering and adversarial training approaches.
The paper also discusses the challenges of evaluating the safety and reliability of jailbroken LLMs, as the standard evaluation metrics may not capture the full range of potential outputs. The authors propose new evaluation frameworks to address these issues.
Critical Analysis
The paper raises important questions about the trade-offs involved in "jailbreaking" large language models. While the ability to overcome an LLM's natural tendency to refuse certain prompts could enable more flexible and capable systems, it also introduces significant risks.
The authors acknowledge that their techniques could be used to generate harmful or unethical content that the model would normally refuse. They propose evaluation frameworks to assess the safety and reliability of jailbroken LLMs, but it's unclear how effective these approaches would be in practice.
Additionally, the paper does not address the broader societal implications of developing systems that can circumvent the ethical safeguards built into large language models. This raises concerns about the potential misuse of such technology and the need for robust governance frameworks to ensure responsible development and deployment.
Conclusion
This research paper presents a novel approach to "jailbreaking" large language models by suppressing their ability to refuse certain prompts. While this could unlock new capabilities for LLMs, it also raises significant concerns about the potential for misuse and the need for careful evaluation and governance of such systems. The paper highlights the complex tradeoffs involved in developing more flexible and capable language models while maintaining robust ethical safeguards.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Tianyu Zhang, Zixuan Zhao, Jiaqi Huang, Jingyu Hua, Sheng Zhong
0
0
As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
4/15/2024
💬
Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, Yang Zhang
0
0
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
5/16/2024
💬
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, Shujian Huang
0
0
Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate potentially harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on other white-box models, which compromises either generalization or efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we analyze the failure of LLMs defense from the perspective of prompt execution priority, and propose corresponding defense strategies. We hope that our research can catalyze both the academic community and LLMs developers towards the provision of safer and more regulated LLMs. The code is available at https://github.com/NJUNLP/ReNeLLM.
4/9/2024

New!A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024