DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training Quantization for Vision Transformers

0
Sign in to get full access
Overview
- The paper proposes a new post-training quantization method called DopQ-ViT for vision transformers.
- DopQ-ViT aims to create quantized models that are more distribution-friendly and outlier-aware.
- The method leverages the distribution of activation values and incorporates outlier-aware quantization to improve model performance.
Plain English Explanation
DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training Quantization for Vision Transformers is a research paper that introduces a new quantization technique for compressing and accelerating vision transformer models.
Quantization is a process that reduces the precision of a neural network's weights and activations, allowing for more efficient inference on hardware. However, traditional quantization methods can sometimes lead to a significant drop in model accuracy, especially when dealing with vision transformers, which have unique activation value distributions.
To address this, the researchers developed DopQ-ViT, which stands for "Distribution-friendly and Outlier-aware Post-Training Quantization for Vision Transformers." This approach aims to create quantized models that are more compatible with the natural distribution of activation values in vision transformers, as well as being more resilient to outliers.
The key innovations of DopQ-ViT include:
- Distribution-Friendly Quantization: The method analyzes the activation value distribution and adjusts the quantization parameters accordingly, ensuring a better fit between the quantized and original activation ranges.
- Outlier-Aware Quantization: DopQ-ViT identifies and handles outlier activation values separately, preventing them from skewing the overall quantization process and negatively impacting model performance.
By incorporating these techniques, the researchers were able to demonstrate improved performance of quantized vision transformer models compared to traditional quantization methods. This could lead to more efficient deployment of these powerful models on edge devices and embedded systems with limited computational resources.
Technical Explanation
DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training Quantization for Vision Transformers introduces a novel post-training quantization (PTQ) approach designed specifically for vision transformers.
The authors first observe that traditional PTQ methods often struggle to effectively quantize vision transformers, as these models exhibit unique activation value distributions that can deviate significantly from the Gaussian distributions typically assumed by standard quantization techniques.
To address this, the researchers propose DopQ-ViT, which stands for "Distribution-friendly and Outlier-aware Post-Training Quantization for Vision Transformers." The key components of DopQ-ViT include:
-
Distribution-Friendly Quantization: The method analyzes the empirical activation value distribution and adjusts the quantization parameters accordingly. This ensures a better fit between the quantized and original activation ranges, improving the overall quality of the quantized model.
-
Outlier-Aware Quantization: DopQ-ViT identifies and handles outlier activation values separately, preventing them from skewing the quantization process and negatively impacting model performance. This is achieved through the use of a dedicated outlier quantizer.
The authors evaluate DopQ-ViT on several popular vision transformer architectures, including ViT, DeiT, and Swin Transformer, across various image classification datasets. The results demonstrate that DopQ-ViT consistently outperforms traditional PTQ methods, achieving higher accuracy in the quantized models while maintaining a high level of compression.
Critical Analysis
The DopQ-ViT paper presents a thoughtful and well-designed approach to post-training quantization for vision transformers. The researchers' observations about the unique activation value distributions in these models and the need for more tailored quantization techniques are well-founded and supported by the experimental results.
One potential limitation of the work is the focus on post-training quantization, which may not be as flexible or adaptable as quantization-aware training techniques. The authors acknowledge this and suggest exploring the combination of DopQ-ViT with quantization-aware training as a potential avenue for future research.
Additionally, while the paper demonstrates the effectiveness of DopQ-ViT on several popular vision transformer architectures, it would be interesting to see how the method performs on a wider range of transformer-based models, including those beyond the computer vision domain.
Overall, the DopQ-ViT paper presents a valuable contribution to the field of model compression and acceleration, particularly for vision transformers. The distribution-friendly and outlier-aware quantization techniques introduced in this work could have broader implications for the efficient deployment of transformer-based models on resource-constrained devices.
Conclusion
The DopQ-ViT paper proposes a novel post-training quantization method specifically tailored for vision transformers. By addressing the unique activation value distributions and outlier-sensitivity of these models, the researchers were able to develop a quantization approach that outperforms traditional techniques in terms of preserving model accuracy.
The implications of this work are significant, as it could enable more efficient deployment of powerful vision transformer models on edge devices and embedded systems with limited computational resources. The distribution-friendly and outlier-aware quantization techniques introduced in this paper could also have broader applications in the field of model compression and acceleration, potentially benefiting a wide range of transformer-based architectures beyond the computer vision domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DopQ-ViT: Towards Distribution-Friendly and Outlier-Aware Post-Training Quantization for Vision Transformers
Lianwei Yang, Haisong Gong, Qingyi Gu
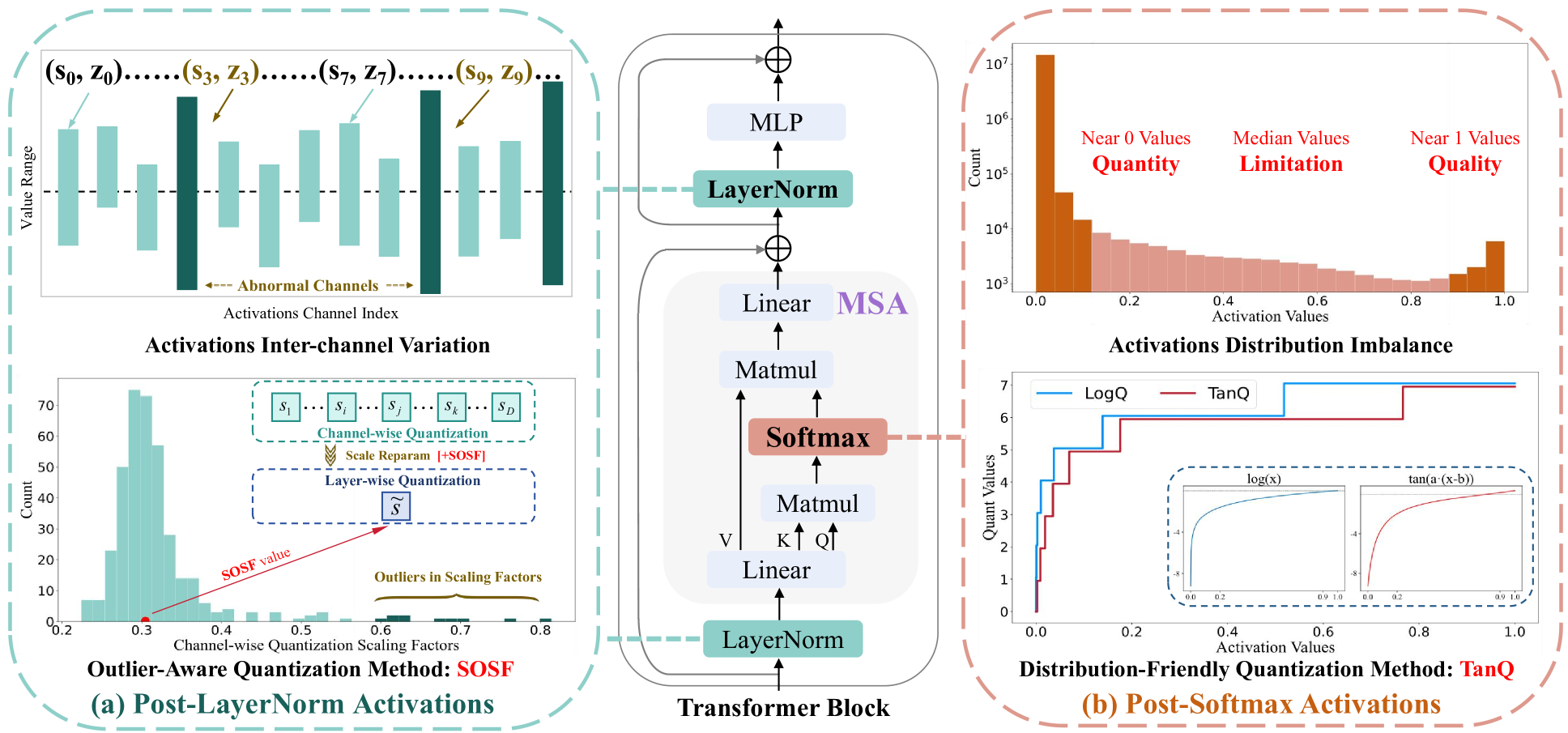
Vision transformers (ViTs) have garnered significant attention for their performance in vision tasks, but the high computational cost and significant latency issues have hindered widespread adoption. Post-training quantization (PTQ), a promising method for model compression, still faces accuracy degradation challenges with ViTs. There are two reasons for this: the existing quantization paradigm does not fit the power-law distribution of post-Softmax activations well, and accuracy inevitably decreases after reparameterizing post-LayerNorm activations. We propose a Distribution-Friendly and Outlier-Aware Post-training Quantization method for Vision Transformers, named DopQ-ViT. DopQ-ViT analyzes the inefficiencies of current quantizers and introduces a distribution-friendly Tan Quantizer called TanQ. TanQ focuses more on values near 1, more accurately preserving the power-law distribution of post-Softmax activations, and achieves favorable results. Besides, during the reparameterization of post-LayerNorm activations from channel-wise to layer-wise quantization, the accuracy degradation is mainly due to the significant impact of outliers in the scaling factors. Therefore, DopQ-ViT proposes a method to select Median as the Optimal Scaling Factor, denoted as MOSF, which compensates for the influence of outliers and preserves the performance of the quantization model. DopQ-ViT has been extensively validated and significantly improves the performance of quantization models, especially in low-bit settings.
Read more8/19/2024

0
ADFQ-ViT: Activation-Distribution-Friendly Post-Training Quantization for Vision Transformers
Yanfeng Jiang, Ning Sun, Xueshuo Xie, Fei Yang, Tao Li
Vision Transformers (ViTs) have exhibited exceptional performance across diverse computer vision tasks, while their substantial parameter size incurs significantly increased memory and computational demands, impeding effective inference on resource-constrained devices. Quantization has emerged as a promising solution to mitigate these challenges, yet existing methods still suffer from significant accuracy loss at low-bit. We attribute this issue to the distinctive distributions of post-LayerNorm and post-GELU activations within ViTs, rendering conventional hardware-friendly quantizers ineffective, particularly in low-bit scenarios. To address this issue, we propose a novel framework called Activation-Distribution-Friendly post-training Quantization for Vision Transformers, ADFQ-ViT. Concretely, we introduce the Per-Patch Outlier-aware Quantizer to tackle irregular outliers in post-LayerNorm activations. This quantizer refines the granularity of the uniform quantizer to a per-patch level while retaining a minimal subset of values exceeding a threshold at full-precision. To handle the non-uniform distributions of post-GELU activations between positive and negative regions, we design the Shift-Log2 Quantizer, which shifts all elements to the positive region and then applies log2 quantization. Moreover, we present the Attention-score enhanced Module-wise Optimization which adjusts the parameters of each quantizer by reconstructing errors to further mitigate quantization error. Extensive experiments demonstrate ADFQ-ViT provides significant improvements over various baselines in image classification, object detection, and instance segmentation tasks at 4-bit. Specifically, when quantizing the ViT-B model to 4-bit, we achieve a 10.23% improvement in Top-1 accuracy on the ImageNet dataset.
Read more7/4/2024
👀
0
Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
Read more5/20/2024
👀
0
PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, Guangyu Sun
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration at a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.
Read more6/26/2024