DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution
2405.17357
0
0

Abstract
Fine-tuning large-scale pre-trained models is inherently a resource-intensive task. While it can enhance the capabilities of the model, it also incurs substantial computational costs, posing challenges to the practical application of downstream tasks. Existing parameter-efficient fine-tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) rely on a bypass framework that ignores the differential parameter budget requirements across weight matrices, which may lead to suboptimal fine-tuning outcomes. To address this issue, we introduce the Dynamic Low-Rank Adaptation (DoRA) method. DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. Experimental results demonstrate that DoRA can achieve competitive performance compared with LoRA and full model fine-tuning, and outperform various strong baselines with the same storage parameter budget. Our code is available at https://github.com/MIkumikumi0116/DoRA
Create account to get full access
Overview
- This paper introduces a new technique called DoRA (Dynamic Rank Distribution) to enhance parameter-efficient fine-tuning of large language models.
- DoRA aims to improve upon existing techniques like ALORA, DLORA, and AFLORA by dynamically adjusting the rank distribution during fine-tuning.
- The goal is to achieve higher performance with fewer trainable parameters compared to standard fine-tuning.
Plain English Explanation
When training large language models like GPT-3 on a new task, the standard approach is to "fine-tune" the entire model by updating all the parameters. This works well but requires retraining the full model, which can be computationally expensive and time-consuming.
To address this, researchers have developed techniques like ALORA, DLORA, and AFLORA that only update a small subset of the model's parameters during fine-tuning. This is called "parameter-efficient fine-tuning."
The new DoRA technique takes this idea a step further by dynamically adjusting the "rank" or complexity of the parameter updates during training. The intuition is that the model may need more complex updates early on, but can get by with simpler updates later in training. By adapting the rank distribution, DoRA aims to achieve higher performance with even fewer trainable parameters compared to existing techniques.
Technical Explanation
The key innovation in DoRA is the dynamic adjustment of the rank distribution during fine-tuning. Existing low-rank adaptation techniques like ALORA and DLORA use a fixed rank, which may not be optimal throughout the training process.
DoRA addresses this by allowing the rank to change over the course of fine-tuning. It starts with a higher rank to capture more complex patterns in the data, then gradually decreases the rank to reduce the number of trainable parameters. This dynamic rank distribution is implemented using a sigmoid-like function that smoothly transitions the rank over time.
The authors show that DoRA outperforms fixed-rank techniques like ALORA and AFLORA in terms of both task performance and parameter efficiency across a range of language modeling and text classification tasks.
Critical Analysis
The paper provides a thorough evaluation of DoRA and demonstrates its advantages over existing techniques. However, there are a few potential limitations and areas for further research:
- The dynamic rank distribution is controlled by a manually-tuned sigmoid function. It's not clear if this is the optimal way to schedule the rank changes, and more flexible or automated approaches could be explored.
- The experiments focus on relatively small-scale tasks and datasets. It would be valuable to see how DoRA scales to larger, more complex language modeling tasks that are more representative of real-world applications.
- The paper does not address the computational and memory overhead of implementing the dynamic rank distribution, which could be an important practical consideration.
- While DoRA outperforms other parameter-efficient techniques, there may still be a significant gap in performance compared to full fine-tuning. Combining DoRA with other techniques like MORA could lead to further improvements.
Overall, DoRA represents an interesting and promising advancement in parameter-efficient fine-tuning, but there is still room for further research and refinement to fully unlock its potential.
Conclusion
The DoRA technique introduced in this paper provides a novel approach to enhance parameter-efficient fine-tuning of large language models. By dynamically adjusting the rank distribution of the parameter updates during training, DoRA achieves higher performance with fewer trainable parameters compared to existing fixed-rank techniques.
This work advances the state-of-the-art in efficient fine-tuning and could have significant practical implications, allowing for faster, more cost-effective deployment of large language models in a wide range of real-world applications. As the field continues to push the boundaries of what's possible with these powerful models, techniques like DoRA will play an increasingly important role in making them more accessible and practical to use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen
0
0
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed Low-Rank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing ours, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. ours~consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding. Code is available at https://github.com/NVlabs/DoRA.
6/4/2024
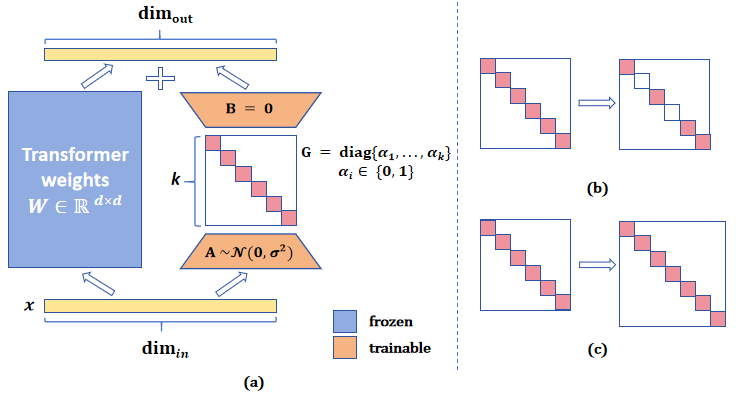
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
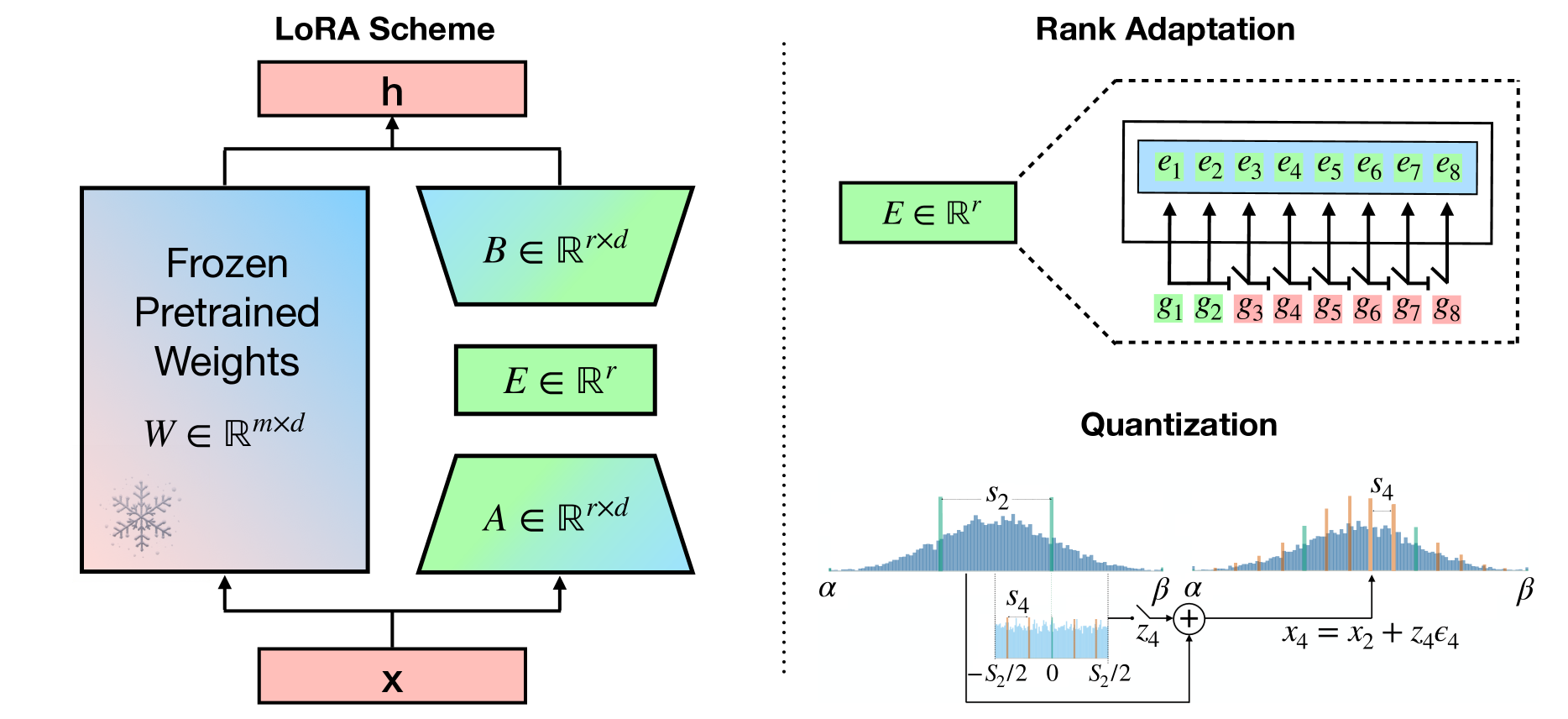
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Cristian Meo, Ksenia Sycheva, Anirudh Goyal, Justin Dauwels
0
0
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.
6/21/2024
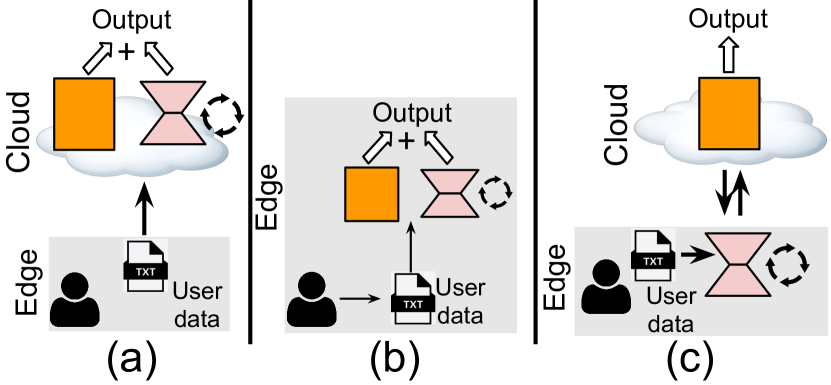
DLoRA: Distributed Parameter-Efficient Fine-Tuning Solution for Large Language Model
Chao Gao, Sai Qian Zhang
0
0
To enhance the performance of large language models (LLM) on downstream tasks, one solution is to fine-tune certain LLM parameters and make it better align with the characteristics of the training dataset. This process is commonly known as parameter-efficient fine-tuning (PEFT). Due to the scale of LLM, PEFT operations are usually executed in the public environment (e.g., cloud server). This necessitates the sharing of sensitive user data across public environments, thereby raising potential privacy concerns. To tackle these challenges, we propose a distributed PEFT framework called DLoRA. DLoRA enables scalable PEFT operations to be performed collaboratively between the cloud and user devices. Coupled with the proposed Kill and Revive algorithm, the evaluation results demonstrate that DLoRA can significantly reduce the computation and communication workload over the user devices while achieving superior accuracy and privacy protection.
4/9/2024