Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
2406.13046
0
0
Abstract
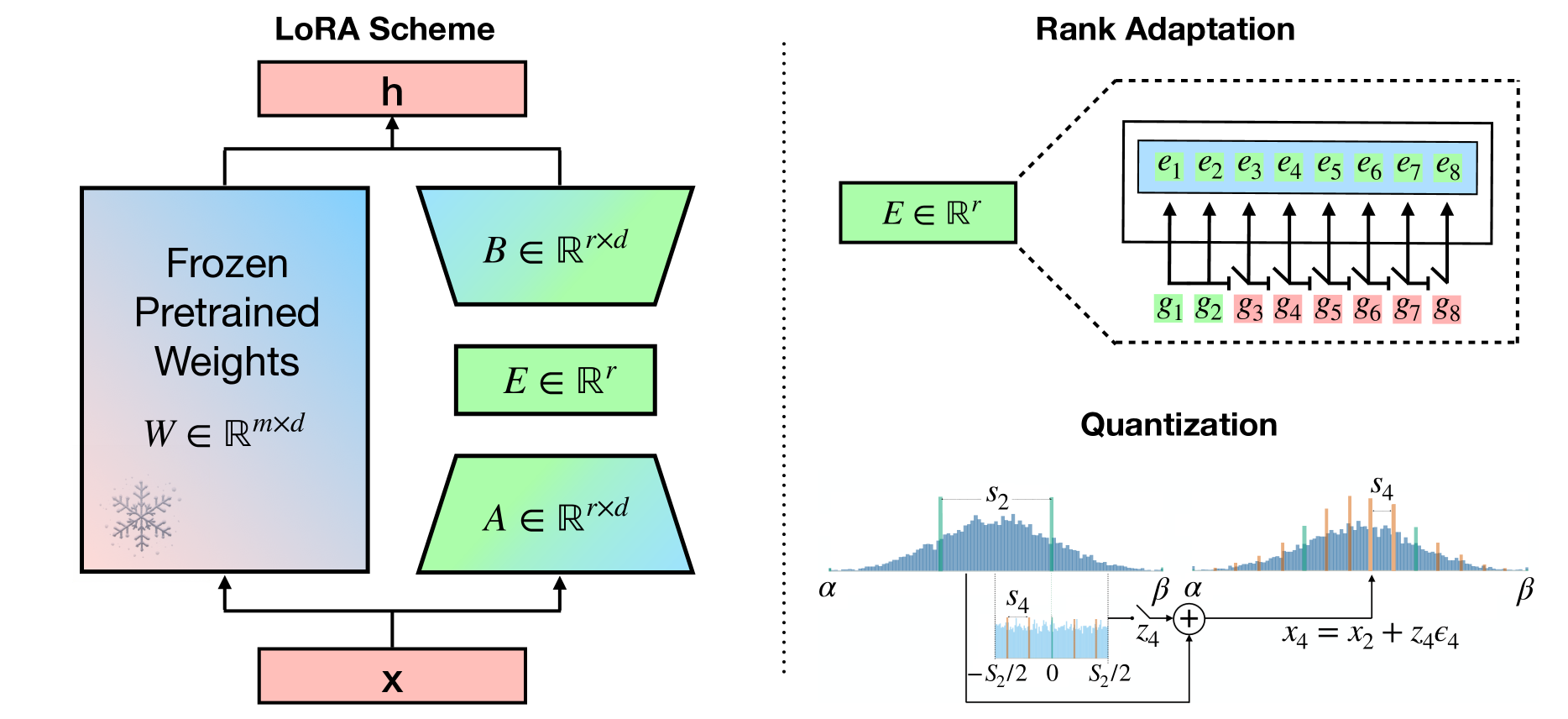
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.
Create account to get full access
Overview
- This research paper explores the use of LORA, a technique for efficient fine-tuning of large language models (LLMs).
- The researchers present several extensions to the LORA method, including ALORA, VB-LORA, DORA, and RoseLORA.
- These methods aim to further improve the parameter efficiency and performance of fine-tuning LLMs for various downstream tasks.
Plain English Explanation
The paper focuses on a technique called LORA, which allows large language models to be fine-tuned for specific tasks in a more efficient way. Fine-tuning is the process of adapting a pre-trained language model to a new task, like answering questions or generating text.
The researchers present several improvements to the original LORA method. For example, ALORA allocates the limited parameters more effectively during fine-tuning. VB-LORA can fine-tune models with even fewer parameters. DORA dynamically adjusts the parameter allocation as the fine-tuning progresses. And RoseLORA uses a sparse approach to reduce the number of parameters even further.
The key idea behind these methods is to find ways to fine-tune large language models without requiring a lot of additional parameters. This is important because large models can be computationally expensive and hard to deploy, especially on resource-constrained devices. By making the fine-tuning process more efficient, these techniques could enable wider use of powerful language models in real-world applications.
Technical Explanation
The paper introduces several extensions to the LORA technique for efficient fine-tuning of large language models:
-
ALORA (Allocating Low-Rank Adaptation): This method focuses on how to allocate the limited LORA parameters across different layers of the model to maximize performance.
-
VB-LORA (Variational Bayes LORA): This approach uses a Bayesian framework to further reduce the number of parameters required during fine-tuning, achieving even higher efficiency.
-
DORA (Dynamic LORA): DORA dynamically adjusts the LORA parameter allocation throughout the fine-tuning process, adapting to the changing needs of the target task.
-
RoseLORA (Row-Column-wise Sparse LORA): RoseLORA introduces a sparse structure to the LORA update matrices, reducing the parameter count while maintaining performance.
The researchers evaluate these methods on a variety of language tasks, including text classification, question answering, and language generation. They demonstrate that the proposed techniques can achieve comparable or better performance to full fine-tuning, but with significantly fewer additional parameters.
Critical Analysis
The paper provides a thorough exploration of techniques to improve the parameter efficiency of fine-tuning large language models. The researchers have identified an important challenge in the field and proposed several novel solutions.
One potential limitation is that the experiments are primarily conducted on a single base model, the GPT-2 language model. It would be valuable to see how these methods generalize to other large language models, such as BERT or T5. Additionally, the real-world deployment challenges, such as the trade-offs between parameter efficiency and task-specific performance, could be explored further.
Another area for future research could be investigating the interaction between these parameter-efficient fine-tuning approaches and other model compression or distillation techniques. Combining multiple methods may lead to even more compact and efficient language models.
Overall, this paper makes a valuable contribution to the field of efficient fine-tuning for large language models, and the proposed techniques have the potential to enable wider adoption of these powerful models in a variety of applications.
Conclusion
This research paper presents several extensions to the LORA method for efficiently fine-tuning large language models. The proposed techniques, including ALORA, VB-LORA, DORA, and RoseLORA, aim to further improve the parameter efficiency and performance of fine-tuning LLMs for various downstream tasks.
The key insight is that by carefully managing the limited parameters available during fine-tuning, it is possible to achieve comparable or better performance to full fine-tuning, but with significantly fewer additional parameters. This could enable the wider deployment of large language models, especially in resource-constrained environments.
The paper provides a solid technical foundation and demonstrates the effectiveness of these methods through extensive experiments. While there are some potential areas for future research, such as exploring the generalization to other language models and combining with other compression techniques, this work represents an important step forward in making large language models more accessible and practical for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
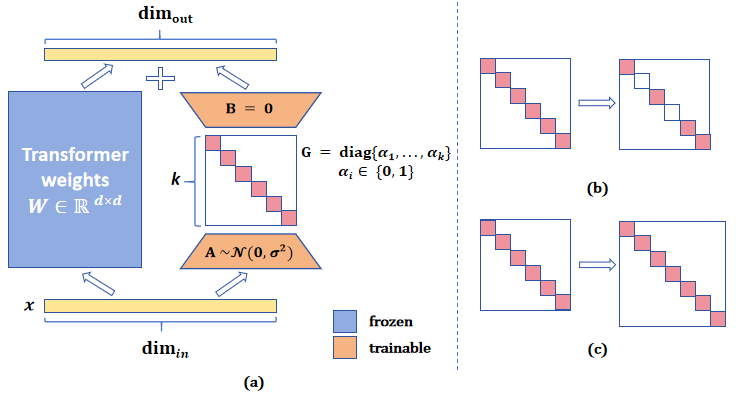
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
🐍
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
Yang Li, Shaobo Han, Shihao Ji
0
0
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a divide-and-share paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
5/29/2024

DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution
Yulong Mao, Kaiyu Huang, Changhao Guan, Ganglin Bao, Fengran Mo, Jinan Xu
0
0
Fine-tuning large-scale pre-trained models is inherently a resource-intensive task. While it can enhance the capabilities of the model, it also incurs substantial computational costs, posing challenges to the practical application of downstream tasks. Existing parameter-efficient fine-tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) rely on a bypass framework that ignores the differential parameter budget requirements across weight matrices, which may lead to suboptimal fine-tuning outcomes. To address this issue, we introduce the Dynamic Low-Rank Adaptation (DoRA) method. DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. Experimental results demonstrate that DoRA can achieve competitive performance compared with LoRA and full model fine-tuning, and outperform various strong baselines with the same storage parameter budget. Our code is available at https://github.com/MIkumikumi0116/DoRA
6/27/2024