DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
2404.01424
0
0

Abstract
The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
Create account to get full access
Overview
- This paper introduces DPMesh, a novel method for recovering 3D human body meshes from occluded images.
- The key idea is to exploit a diffusion prior to generate plausible human mesh shapes, even when parts of the body are hidden from view.
- The authors demonstrate that DPMesh outperforms existing approaches on standard benchmarks for 3D human mesh recovery.
Plain English Explanation
Imagine you're looking at a photo of a person, but part of their body is hidden or obscured. How can you still figure out the full 3D shape of their body? This is the challenge the researchers behind DPMesh are trying to solve.
Traditionally, 3D human mesh recovery methods have struggled with occluded or missing body parts. But the key insight behind DPMesh is to use a "diffusion prior" - essentially, a model of how human body shapes tend to vary and change over time. By leveraging this diffusion prior, DPMesh can intelligently fill in the missing pieces and recover a plausible 3D mesh, even when parts of the body are hidden.
Think of it like an artist trying to sketch a person, but they can only see part of the person's body. The artist might use their knowledge of human anatomy and how bodies tend to move and change shape to intelligently fill in the missing parts of the drawing. DPMesh does something similar, but in a automated, data-driven way.
Technical Explanation
The core of DPMesh is a diffusion model that has been trained on a large dataset of 3D human body shapes. This diffusion model learns the natural "flow" or evolution of human body shapes, capturing how they tend to deform and change over time.
Given an input image with occluded body parts, DPMesh first extracts 2D pose information using an off-the-shelf pose estimator. It then uses this 2D pose as a starting point to iteratively refine and "diffuse" the 3D mesh shape, gradually filling in the missing parts in a plausible way guided by the learned diffusion prior.
The key innovation is that this diffusion process is conditioned on the available 2D pose information, ensuring the final 3D mesh is consistent with the observed body parts. Extensive experiments on standard 3D mesh recovery benchmarks show that DPMesh outperforms previous approaches, especially in challenging cases with heavy occlusion.
Critical Analysis
The paper provides a thorough evaluation of DPMesh, comparing it to state-of-the-art methods across multiple datasets and occlusion scenarios. The results demonstrate clear performance improvements, suggesting DPMesh is an effective approach for the task of 3D human mesh recovery from occluded images.
However, the paper does not extensively discuss potential limitations or failure cases of the method. For example, it is unclear how DPMesh would handle extreme or unusual body poses that are not well-represented in the training data. Additionally, the reliance on a pre-trained 2D pose estimator could introduce errors that propagate through the system.
Further research could explore ways to make DPMesh more robust to a wider range of body shapes and poses, potentially by incorporating additional priors or modeling uncertainties more explicitly. Integrating the 2D pose estimation and 3D mesh recovery into a end-to-end system could also be an interesting direction to pursue.
Conclusion
Overall, the DPMesh method represents an important step forward in the field of 3D human mesh recovery. By exploiting a learned diffusion prior, the approach can effectively fill in missing body parts and generate plausible 3D meshes, even in the presence of significant occlusion. The promising results suggest that diffusion-based techniques could become a valuable tool for a wide range of applications, from computer graphics to human motion analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

$text{Di}^2text{Pose}$: Discrete Diffusion Model for Occluded 3D Human Pose Estimation
Weiquan Wang, Jun Xiao, Chunping Wang, Wei Liu, Zhao Wang, Long Chen
0
0
Continuous diffusion models have demonstrated their effectiveness in addressing the inherent uncertainty and indeterminacy in monocular 3D human pose estimation (HPE). Despite their strengths, the need for large search spaces and the corresponding demand for substantial training data make these models prone to generating biomechanically unrealistic poses. This challenge is particularly noticeable in occlusion scenarios, where the complexity of inferring 3D structures from 2D images intensifies. In response to these limitations, we introduce the Discrete Diffusion Pose ($text{Di}^2text{Pose}$), a novel framework designed for occluded 3D HPE that capitalizes on the benefits of a discrete diffusion model. Specifically, $text{Di}^2text{Pose}$ employs a two-stage process: it first converts 3D poses into a discrete representation through a emph{pose quantization step}, which is subsequently modeled in latent space through a emph{discrete diffusion process}. This methodological innovation restrictively confines the search space towards physically viable configurations and enhances the model's capability to comprehend how occlusions affect human pose within the latent space. Extensive evaluations conducted on various benchmarks (e.g., Human3.6M, 3DPW, and 3DPW-Occ) have demonstrated its effectiveness.
5/28/2024

Exploiting Diffusion Prior for Generalizable Dense Prediction
Hsin-Ying Lee, Hung-Yu Tseng, Hsin-Ying Lee, Ming-Hsuan Yang
0
0
Contents generated by recent advanced Text-to-Image (T2I) diffusion models are sometimes too imaginative for existing off-the-shelf dense predictors to estimate due to the immitigable domain gap. We introduce DMP, a pipeline utilizing pre-trained T2I models as a prior for dense prediction tasks. To address the misalignment between deterministic prediction tasks and stochastic T2I models, we reformulate the diffusion process through a sequence of interpolations, establishing a deterministic mapping between input RGB images and output prediction distributions. To preserve generalizability, we use low-rank adaptation to fine-tune pre-trained models. Extensive experiments across five tasks, including 3D property estimation, semantic segmentation, and intrinsic image decomposition, showcase the efficacy of the proposed method. Despite limited-domain training data, the approach yields faithful estimations for arbitrary images, surpassing existing state-of-the-art algorithms.
4/4/2024
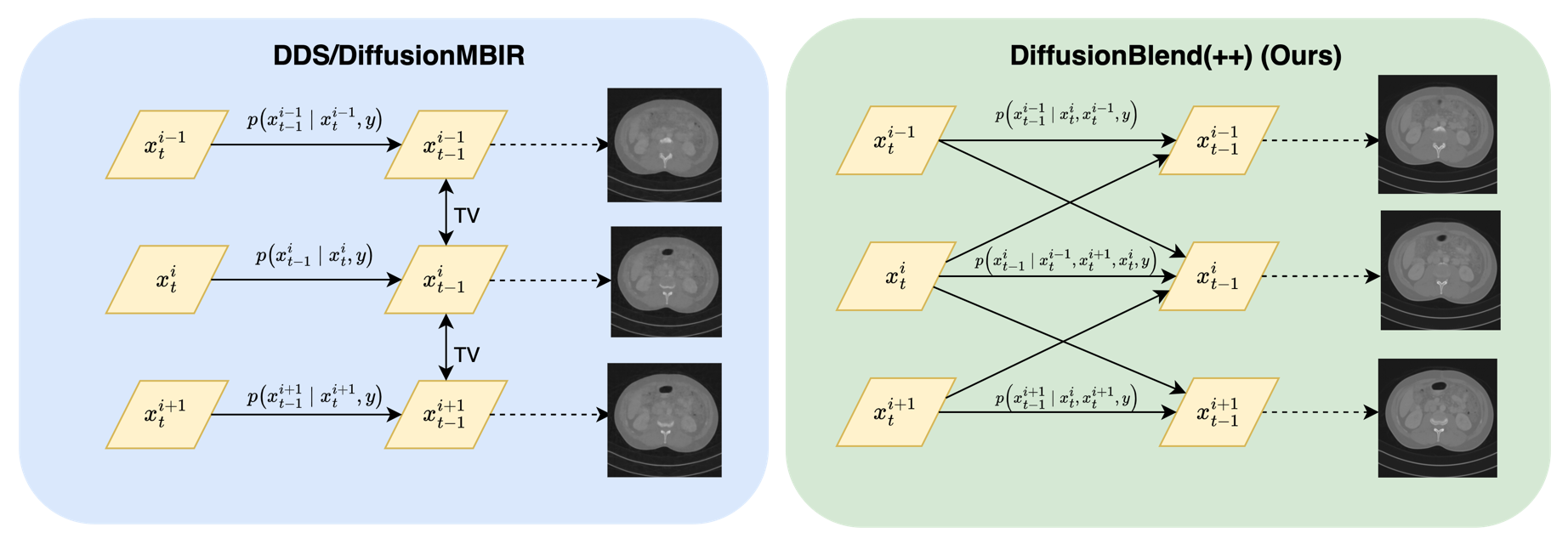
DiffusionBlend: Learning 3D Image Prior through Position-aware Diffusion Score Blending for 3D Computed Tomography Reconstruction
Bowen Song, Jason Hu, Zhaoxu Luo, Jeffrey A. Fessler, Liyue Shen
0
0
Diffusion models face significant challenges when employed for large-scale medical image reconstruction in real practice such as 3D Computed Tomography (CT). Due to the demanding memory, time, and data requirements, it is difficult to train a diffusion model directly on the entire volume of high-dimensional data to obtain an efficient 3D diffusion prior. Existing works utilizing diffusion priors on single 2D image slice with hand-crafted cross-slice regularization would sacrifice the z-axis consistency, which results in severe artifacts along the z-axis. In this work, we propose a novel framework that enables learning the 3D image prior through position-aware 3D-patch diffusion score blending for reconstructing large-scale 3D medical images. To the best of our knowledge, we are the first to utilize a 3D-patch diffusion prior for 3D medical image reconstruction. Extensive experiments on sparse view and limited angle CT reconstruction show that our DiffusionBlend method significantly outperforms previous methods and achieves state-of-the-art performance on real-world CT reconstruction problems with high-dimensional 3D image (i.e., $256 times 256 times 500$). Our algorithm also comes with better or comparable computational efficiency than previous state-of-the-art methods.
6/17/2024

DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Yiming Zhang, Zhe Wang, Xinjie Li, Yunchen Yuan, Chengsong Zhang, Xiao Sun, Zhihang Zhong, Jian Wang
0
0
Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model's focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
4/5/2024