DragVideo: Interactive Drag-style Video Editing
2312.02216
0
0
🗣️
Abstract
Video generation models have shown their superior ability to generate photo-realistic video. However, how to accurately control (or edit) the video remains a formidable challenge. The main issues are: 1) how to perform direct and accurate user control in editing; 2) how to execute editings like changing shape, expression, and layout without unsightly distortion and artifacts to the edited content; and 3) how to maintain spatio-temporal consistency of video after editing. To address the above issues, we propose DragVideo, a general drag-style video editing framework. Inspired by DragGAN, DragVideo addresses issues 1) and 2) by proposing the drag-style video latent optimization method which gives desired control by updating noisy video latent according to drag instructions through video-level drag objective function. We amend issue 3) by integrating the video diffusion model with sample-specific LoRA and Mutual Self-Attention in DragVideo to ensure the edited result is spatio-temporally consistent. We also present a series of testing examples for drag-style video editing and conduct extensive experiments across a wide array of challenging editing tasks, such as motion, skeleton editing, etc, underscoring DragVideo can edit video in an intuitive, faithful to the user's intention manner, with nearly unnoticeable distortion and artifacts, while maintaining spatio-temporal consistency. While traditional prompt-based video editing fails to do the former two and directly applying image drag editing fails in the last, DragVideo's versatility and generality are emphasized. Github link: https://github.com/RickySkywalker/DragVideo-Official.
Create account to get full access
Overview
- Video generation models can now produce highly realistic videos, but accurately controlling or editing these videos remains a challenge
- Key issues include: 1) providing users with direct and accurate control during editing, 2) executing edits like changing shape, expression, and layout without noticeable distortions or artifacts, and 3) maintaining the video's spatio-temporal consistency after editing
Plain English Explanation
Advances in video generation have led to the creation of remarkably lifelike videos. However, the ability to precisely control or edit these videos remains a significant hurdle. The main problems are:
-
Giving users direct and accurate control over the editing process. It can be difficult for people to make the specific changes they want.
-
Executing edits, like altering a character's shape, expression, or positioning, without introducing unsightly distortions or glitches in the final video. Maintaining the video's visual quality is crucial.
-
Ensuring the edited video remains consistent in terms of space and time. The various elements should flow naturally and seamlessly after any changes are made.
To address these challenges, the researchers developed a framework called DragVideo. This system allows users to intuitively edit videos by "dragging" on the content, similar to how one might edit an image. DragVideo aims to provide precise user control, preserve the video's visual integrity, and keep the spatio-temporal qualities intact.
Technical Explanation
The key innovations in DragVideo are:
-
A "drag-style" video latent optimization method that updates the video's latent representation based on the user's drag instructions, enabling direct and accurate control.
-
Integration of a video diffusion model with sample-specific LoRA (Low-Rank Adaptation) and Mutual Self-Attention mechanisms to maintain the spatio-temporal consistency of the edited video.
The researchers tested DragVideo on a variety of challenging video editing tasks, such as altering motion and skeleton. They found that DragVideo allows for intuitive, intention-preserving edits with minimal distortion or artifacts, outperforming traditional prompt-based approaches and direct application of image-based drag editing.
Critical Analysis
The paper provides a comprehensive technical solution to the challenging problem of video editing, addressing key issues around user control, visual fidelity, and spatio-temporal consistency. However, the researchers acknowledge that their approach has certain limitations:
- The paper does not explore the scalability of DragVideo to longer or more complex videos, which could present additional technical hurdles.
- The evaluation focuses on specific editing tasks, and the system's performance on a wider range of real-world editing scenarios remains to be seen.
- While the paper demonstrates DragVideo's advantages over existing methods, a more extensive comparison to state-of-the-art video editing tools would provide further context.
Additionally, the ethical implications of highly realistic video editing capabilities, such as the potential for misuse or the spread of misinformation, are not addressed in the paper. As these technologies continue to advance, it will be important for the research community to consider such broader societal impacts.
Conclusion
DragVideo presents a novel and promising approach to video editing, addressing longstanding challenges around user control, visual fidelity, and spatio-temporal consistency. By enabling intuitive, intention-preserving edits with minimal distortion, the framework represents a significant advancement in the field of video generation and manipulation. As these technologies continue to evolve, it will be crucial to explore their broader implications and work towards developing responsible, ethical, and socially-conscious applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
InstaDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos
Yujun Shi, Jun Hao Liew, Hanshu Yan, Vincent Y. F. Tan, Jiashi Feng
0
0
Accuracy and speed are critical in image editing tasks. Pan et al. introduced a drag-based image editing framework that achieves pixel-level control using Generative Adversarial Networks (GANs). A flurry of subsequent studies enhanced this framework's generality by leveraging large-scale diffusion models. However, these methods often suffer from inordinately long processing times (exceeding 1 minute per edit) and low success rates. Addressing these issues head on, we present InstaDrag, a rapid approach enabling high quality drag-based image editing in ~1 second. Unlike most previous methods, we redefine drag-based editing as a conditional generation task, eliminating the need for time-consuming latent optimization or gradient-based guidance during inference. In addition, the design of our pipeline allows us to train our model on large-scale paired video frames, which contain rich motion information such as object translations, changing poses and orientations, zooming in and out, etc. By learning from videos, our approach can significantly outperform previous methods in terms of accuracy and consistency. Despite being trained solely on videos, our model generalizes well to perform local shape deformations not presented in the training data (e.g., lengthening of hair, twisting rainbows, etc.). Extensive qualitative and quantitative evaluations on benchmark datasets corroborate the superiority of our approach. The code and model will be released at https://github.com/magic-research/InstaDrag.
5/24/2024

FastDrag: Manipulate Anything in One Step
Xuanjia Zhao, Jian Guan, Congyi Fan, Dongli Xu, Youtian Lin, Haiwei Pan, Pengming Feng
0
0
Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance. Project page: https://fastdrag-site.github.io/ .
6/7/2024
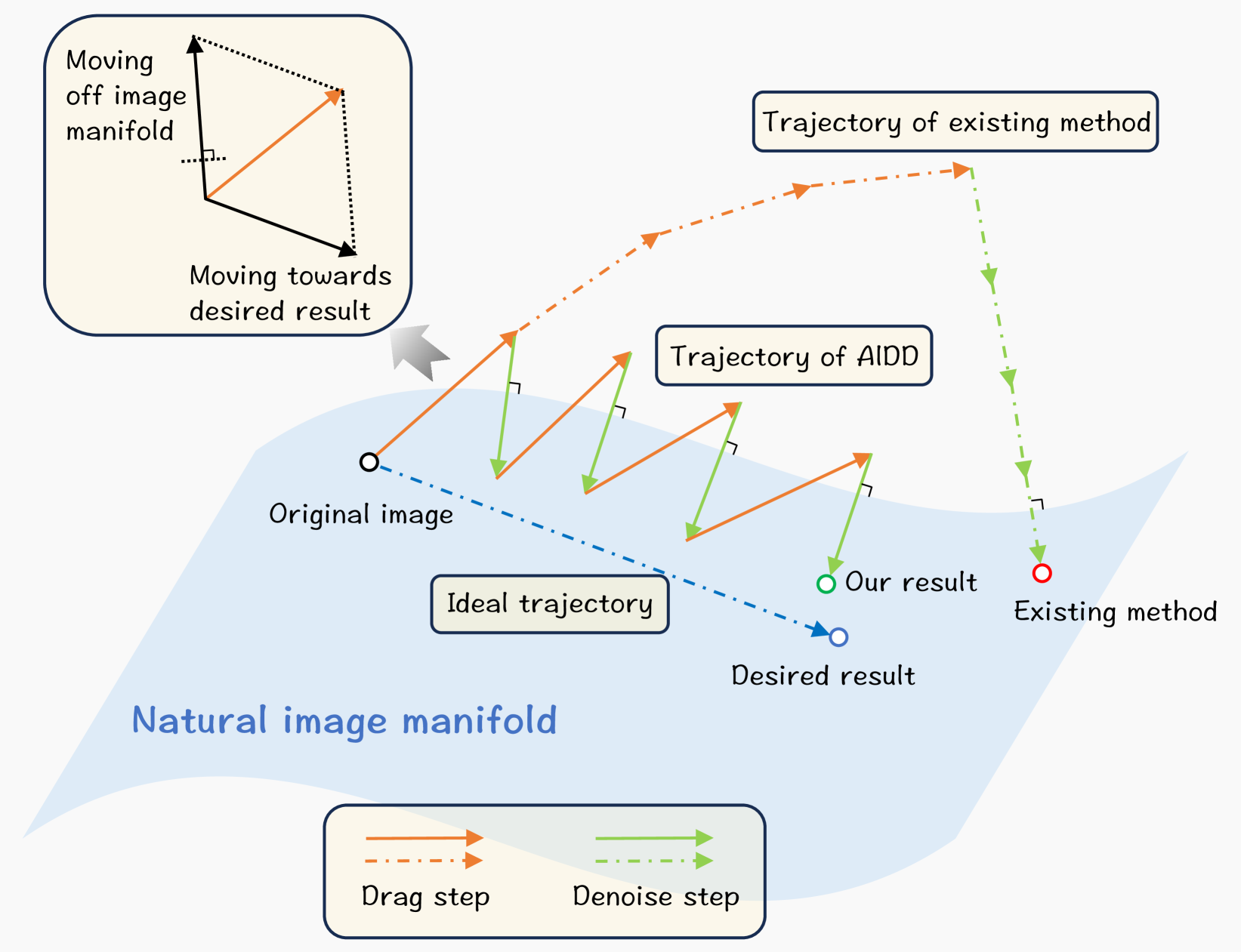
GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
Zewei Zhang, Huan Liu, Jun Chen, Xiangyu Xu
0
0
In this paper, we introduce GoodDrag, a novel approach to improve the stability and image quality of drag editing. Unlike existing methods that struggle with accumulated perturbations and often result in distortions, GoodDrag introduces an AlDD framework that alternates between drag and denoising operations within the diffusion process, effectively improving the fidelity of the result. We also propose an information-preserving motion supervision operation that maintains the original features of the starting point for precise manipulation and artifact reduction. In addition, we contribute to the benchmarking of drag editing by introducing a new dataset, Drag100, and developing dedicated quality assessment metrics, Dragging Accuracy Index and Gemini Score, utilizing Large Multimodal Models. Extensive experiments demonstrate that the proposed GoodDrag compares favorably against the state-of-the-art approaches both qualitatively and quantitatively. The project page is https://gooddrag.github.io.
4/11/2024

Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas Guibas, Gordon Wetzstein
0
0
Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories make strides towards it. Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision. The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism. Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments. Project page: https://collaborativevideodiffusion.github.io/.
5/28/2024