GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
2404.07206
0
0
Abstract
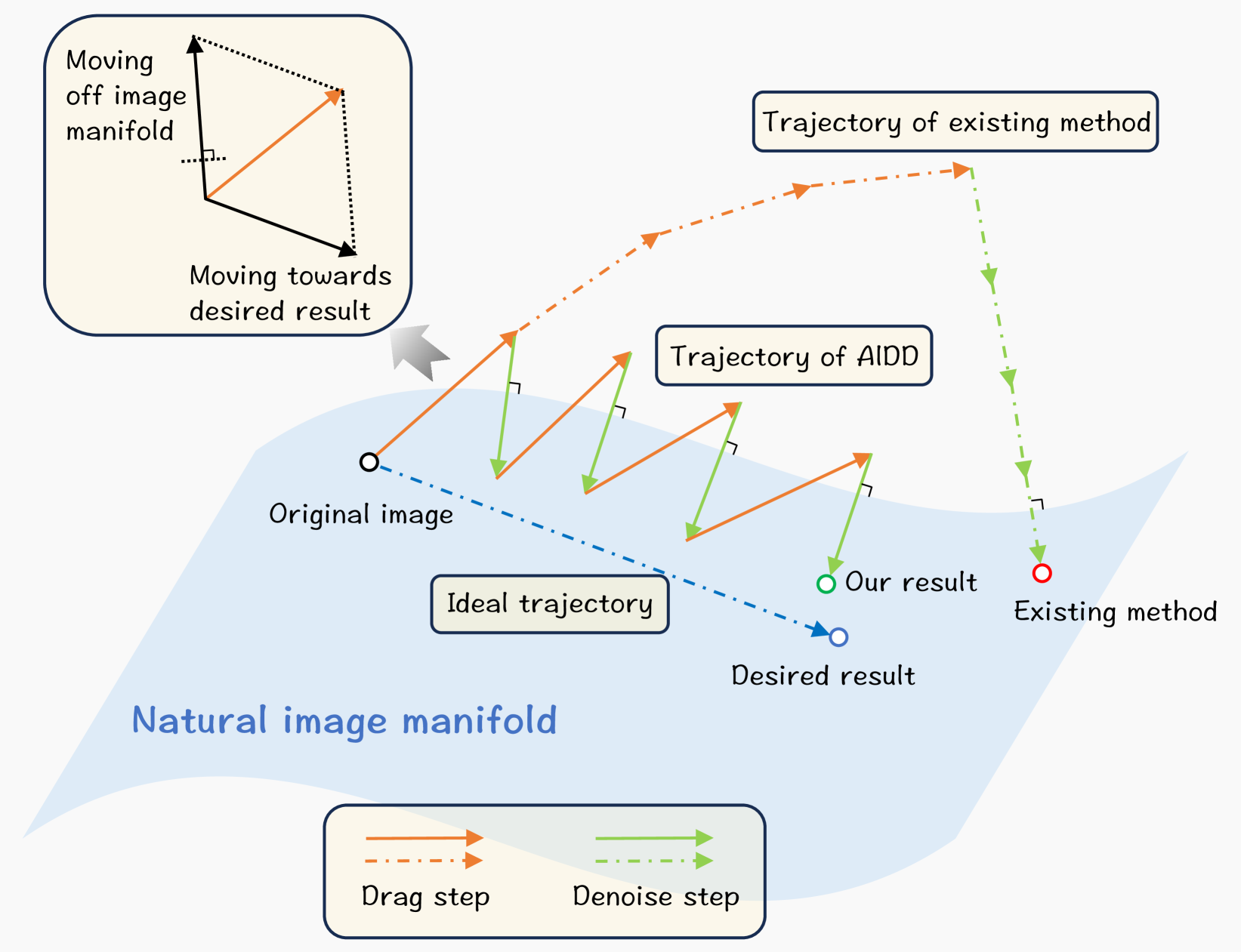
In this paper, we introduce GoodDrag, a novel approach to improve the stability and image quality of drag editing. Unlike existing methods that struggle with accumulated perturbations and often result in distortions, GoodDrag introduces an AlDD framework that alternates between drag and denoising operations within the diffusion process, effectively improving the fidelity of the result. We also propose an information-preserving motion supervision operation that maintains the original features of the starting point for precise manipulation and artifact reduction. In addition, we contribute to the benchmarking of drag editing by introducing a new dataset, Drag100, and developing dedicated quality assessment metrics, Dragging Accuracy Index and Gemini Score, utilizing Large Multimodal Models. Extensive experiments demonstrate that the proposed GoodDrag compares favorably against the state-of-the-art approaches both qualitatively and quantitatively. The project page is https://gooddrag.github.io.
Create account to get full access
Overview
- This paper presents "GoodDrag", a set of guidelines for using diffusion models to edit images through drag-and-drop interactions.
- Diffusion models are a type of machine learning model that can generate new images by gradually adding noise to an existing image and then reversing the process to create a new image.
- The researchers explore how to apply diffusion models to enable interactive editing of images through intuitive drag-and-drop operations.
Plain English Explanation
The paper discusses ways to make it easier for people to edit images using a technique called "diffusion models". Diffusion models are a type of machine learning model that can generate new images by starting with a noisy image and gradually cleaning it up.
The researchers wanted to find good practices for using diffusion models to let people edit images by simply dragging and dropping parts of the image around. This could make image editing much more intuitive and accessible for non-experts. They explore different strategies for how to best apply diffusion models to enable this type of interactive editing.
The goal is to make it easier for anyone to manipulate and customize images in creative ways, without needing advanced technical skills. By harnessing the power of diffusion models, the researchers hope to unlock new possibilities for interactive image and video editing.
Technical Explanation
The paper first reviews prior work on using diffusion models for image manipulation and multimodal editing. It then proposes a set of guidelines, termed "GoodDrag", for effectively applying diffusion models to enable intuitive drag-and-drop editing of images.
Key elements of the GoodDrag approach include:
- Guidance Conditioning: Leveraging the diffusion model's ability to integrate external guidance signals to steer the editing process.
- Semantic-Aware Editing: Incorporating semantic segmentation to enable more precise and semantically-meaningful edits.
- Progressive Refinement: Allowing users to iteratively refine edits through successive drag-and-drop interactions.
- Robust Diffusion Inversion: Developing robust techniques for inverting the diffusion process to reconstruct an edited image.
The paper evaluates these techniques through user studies and qualitative examples, demonstrating how GoodDrag can enable natural and expressive image editing powered by diffusion models.
Critical Analysis
The paper presents a well-designed set of guidelines for leveraging diffusion models to power intuitive image editing capabilities. The researchers acknowledge that further work is needed to improve the efficiency of diffusion models and address potential issues like semantic consistency and mode collapse.
While the user study results are promising, additional research is warranted to better understand the strengths and limitations of the GoodDrag approach across a wider range of editing tasks and user demographics. Expanding the evaluation to more complex images and real-world editing scenarios could also provide valuable insights.
Overall, the paper makes a compelling case for the potential of diffusion models to revolutionize interactive image editing, and the GoodDrag guidelines offer a solid foundation for further exploration and refinement of this exciting area of research.
Conclusion
This paper introduces "GoodDrag", a set of best practices for using diffusion models to enable intuitive, drag-and-drop image editing. By harnessing the capabilities of diffusion models, the researchers aim to make image manipulation more accessible and expressive for a wide range of users.
The GoodDrag guidelines cover key aspects such as guidance conditioning, semantic-aware editing, progressive refinement, and robust diffusion inversion. Through user studies and qualitative examples, the paper demonstrates the potential of this approach to unlock new possibilities for interactive image and video editing powered by advanced machine learning techniques.
As diffusion models continue to evolve and improve, the insights and principles outlined in this paper can serve as a valuable reference for developers and researchers seeking to leverage these powerful generative models to create more accessible and user-friendly creative tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FastDrag: Manipulate Anything in One Step
Xuanjia Zhao, Jian Guan, Congyi Fan, Dongli Xu, Youtian Lin, Haiwei Pan, Pengming Feng
0
0
Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance. Project page: https://fastdrag-site.github.io/ .
6/7/2024
🗣️
DragVideo: Interactive Drag-style Video Editing
Yufan Deng, Ruida Wang, Yuhao Zhang, Yu-Wing Tai, Chi-Keung Tang
0
0
Video generation models have shown their superior ability to generate photo-realistic video. However, how to accurately control (or edit) the video remains a formidable challenge. The main issues are: 1) how to perform direct and accurate user control in editing; 2) how to execute editings like changing shape, expression, and layout without unsightly distortion and artifacts to the edited content; and 3) how to maintain spatio-temporal consistency of video after editing. To address the above issues, we propose DragVideo, a general drag-style video editing framework. Inspired by DragGAN, DragVideo addresses issues 1) and 2) by proposing the drag-style video latent optimization method which gives desired control by updating noisy video latent according to drag instructions through video-level drag objective function. We amend issue 3) by integrating the video diffusion model with sample-specific LoRA and Mutual Self-Attention in DragVideo to ensure the edited result is spatio-temporally consistent. We also present a series of testing examples for drag-style video editing and conduct extensive experiments across a wide array of challenging editing tasks, such as motion, skeleton editing, etc, underscoring DragVideo can edit video in an intuitive, faithful to the user's intention manner, with nearly unnoticeable distortion and artifacts, while maintaining spatio-temporal consistency. While traditional prompt-based video editing fails to do the former two and directly applying image drag editing fails in the last, DragVideo's versatility and generality are emphasized. Github link: https://github.com/RickySkywalker/DragVideo-Official.
4/1/2024
🖼️
InstaDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos
Yujun Shi, Jun Hao Liew, Hanshu Yan, Vincent Y. F. Tan, Jiashi Feng
0
0
Accuracy and speed are critical in image editing tasks. Pan et al. introduced a drag-based image editing framework that achieves pixel-level control using Generative Adversarial Networks (GANs). A flurry of subsequent studies enhanced this framework's generality by leveraging large-scale diffusion models. However, these methods often suffer from inordinately long processing times (exceeding 1 minute per edit) and low success rates. Addressing these issues head on, we present InstaDrag, a rapid approach enabling high quality drag-based image editing in ~1 second. Unlike most previous methods, we redefine drag-based editing as a conditional generation task, eliminating the need for time-consuming latent optimization or gradient-based guidance during inference. In addition, the design of our pipeline allows us to train our model on large-scale paired video frames, which contain rich motion information such as object translations, changing poses and orientations, zooming in and out, etc. By learning from videos, our approach can significantly outperform previous methods in terms of accuracy and consistency. Despite being trained solely on videos, our model generalizes well to perform local shape deformations not presented in the training data (e.g., lengthening of hair, twisting rainbows, etc.). Extensive qualitative and quantitative evaluations on benchmark datasets corroborate the superiority of our approach. The code and model will be released at https://github.com/magic-research/InstaDrag.
5/24/2024

Localize, Understand, Collaborate: Semantic-Aware Dragging via Intention Reasoner
Xing Cui, Peipei Li, Zekun Li, Xuannan Liu, Yueying Zou, Zhaofeng He
0
0
Flexible and accurate drag-based editing is a challenging task that has recently garnered significant attention. Current methods typically model this problem as automatically learning ``how to drag'' through point dragging and often produce one deterministic estimation, which presents two key limitations: 1) Overlooking the inherently ill-posed nature of drag-based editing, where multiple results may correspond to a given input, as illustrated in Fig.1; 2) Ignoring the constraint of image quality, which may lead to unexpected distortion. To alleviate this, we propose LucidDrag, which shifts the focus from ``how to drag'' to a paradigm of ``what-then-how''. LucidDrag comprises an intention reasoner and a collaborative guidance sampling mechanism. The former infers several optimal editing strategies, identifying what content and what semantic direction to be edited. Based on the former, the latter addresses how to drag by collaboratively integrating existing editing guidance with the newly proposed semantic guidance and quality guidance. Specifically, semantic guidance is derived by establishing a semantic editing direction based on reasoned intentions, while quality guidance is achieved through classifier guidance using an image fidelity discriminator. Both qualitative and quantitative comparisons demonstrate the superiority of LucidDrag over previous methods. The code will be released.
6/4/2024