InstaDrag: Lightning Fast and Accurate Drag-based Image Editing Emerging from Videos
2405.13722
0
0
🖼️
Abstract
Accuracy and speed are critical in image editing tasks. Pan et al. introduced a drag-based image editing framework that achieves pixel-level control using Generative Adversarial Networks (GANs). A flurry of subsequent studies enhanced this framework's generality by leveraging large-scale diffusion models. However, these methods often suffer from inordinately long processing times (exceeding 1 minute per edit) and low success rates. Addressing these issues head on, we present InstaDrag, a rapid approach enabling high quality drag-based image editing in ~1 second. Unlike most previous methods, we redefine drag-based editing as a conditional generation task, eliminating the need for time-consuming latent optimization or gradient-based guidance during inference. In addition, the design of our pipeline allows us to train our model on large-scale paired video frames, which contain rich motion information such as object translations, changing poses and orientations, zooming in and out, etc. By learning from videos, our approach can significantly outperform previous methods in terms of accuracy and consistency. Despite being trained solely on videos, our model generalizes well to perform local shape deformations not presented in the training data (e.g., lengthening of hair, twisting rainbows, etc.). Extensive qualitative and quantitative evaluations on benchmark datasets corroborate the superiority of our approach. The code and model will be released at https://github.com/magic-research/InstaDrag.
Create account to get full access
Overview
- Researchers introduced a new framework for interactive image editing using Generative Adversarial Networks (GANs) and large-scale diffusion models.
- This approach aims to provide pixel-level control and high-quality results, but often suffers from long processing times and low success rates.
- The paper presents InstaDrag, a new method that can achieve high-quality drag-based image editing in around 1 second.
Plain English Explanation
The researchers wanted to create a way for people to easily edit images by dragging and moving things around. Previous methods using GANs and diffusion models could do this, but it often took a long time (over a minute) and didn't always work well.
The new InstaDrag system solves these problems by redefining the editing process as a "conditional generation" task. This means the model can quickly generate a new image based on how the user wants to drag and move things around, without needing to do a lot of complicated calculations.
The researchers also trained their model using videos, which helped it learn about how objects move and change shape. This allows InstaDrag to do edits that previous methods couldn't, like lengthening hair or twisting rainbows.
The end result is an image editing tool that is fast, accurate, and can do a wide variety of edits, which could be very useful for things like photo editing, digital art, and special effects.
Technical Explanation
The InstaDrag system redefines drag-based image editing as a conditional generation task, eliminating the need for time-consuming latent optimization or gradient-based guidance during inference. This allows the model to generate the edited image directly, rather than having to iteratively refine a starting image.
Additionally, the researchers trained their model on large-scale paired video frames, which contain rich motion information such as object translations, changing poses and orientations, and zooming in and out. By learning from this diverse video data, the InstaDrag model can significantly outperform previous methods in terms of accuracy and consistency.
The model's ability to generalize beyond the training data is demonstrated by its capacity to perform local shape deformations not present in the video data, such as lengthening hair or twisting rainbows. This suggests the model has learned robust representations for reasoning about object shape and appearance changes.
Extensive qualitative and quantitative evaluations on benchmark datasets confirm the superiority of the InstaDrag approach compared to prior drag-based and diffusion-based image editing methods.
Critical Analysis
The paper provides a compelling solution to the challenges of previous interactive image editing methods, which often suffered from long processing times and low success rates. By redefining the task as conditional generation and leveraging diverse video data, the InstaDrag approach achieves impressive results in terms of speed and accuracy.
However, the paper does not address potential limitations or areas for further research. For example, it would be valuable to understand the model's performance on more complex editing tasks, such as multi-object manipulations or edits that require high-level semantic reasoning. Additionally, the generalization to non-video-like edits, such as lengthening hair, could be further explored and explained.
It would also be interesting to see how the InstaDrag approach compares to other recent advances in interactive and generative image editing, which may offer complementary capabilities or trade-offs.
Overall, the InstaDrag method represents a significant step forward in the field of interactive image editing, and the authors' decision to release the code and model will likely spur further advancements and applications in this domain.
Conclusion
The InstaDrag system introduced in this paper represents a breakthrough in interactive image editing, addressing key limitations of previous methods. By redefining the task as conditional generation and leveraging diverse video data, the model can produce high-quality edited images in just ~1 second, a drastic improvement over the long processing times of prior approaches.
The ability of the InstaDrag model to generalize beyond its training data and perform novel edits, such as lengthening hair or twisting rainbows, showcases its robustness and versatility. This could make the technology widely applicable in various domains, from photo editing and digital art to visual effects and beyond.
The release of the InstaDrag code and model will likely accelerate further research and development in this exciting area of interactive image editing, unlocking new possibilities for creative expression and visual storytelling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

FastDrag: Manipulate Anything in One Step
Xuanjia Zhao, Jian Guan, Congyi Fan, Dongli Xu, Youtian Lin, Haiwei Pan, Pengming Feng
0
0
Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance. Project page: https://fastdrag-site.github.io/ .
6/7/2024
🗣️
DragVideo: Interactive Drag-style Video Editing
Yufan Deng, Ruida Wang, Yuhao Zhang, Yu-Wing Tai, Chi-Keung Tang
0
0
Video generation models have shown their superior ability to generate photo-realistic video. However, how to accurately control (or edit) the video remains a formidable challenge. The main issues are: 1) how to perform direct and accurate user control in editing; 2) how to execute editings like changing shape, expression, and layout without unsightly distortion and artifacts to the edited content; and 3) how to maintain spatio-temporal consistency of video after editing. To address the above issues, we propose DragVideo, a general drag-style video editing framework. Inspired by DragGAN, DragVideo addresses issues 1) and 2) by proposing the drag-style video latent optimization method which gives desired control by updating noisy video latent according to drag instructions through video-level drag objective function. We amend issue 3) by integrating the video diffusion model with sample-specific LoRA and Mutual Self-Attention in DragVideo to ensure the edited result is spatio-temporally consistent. We also present a series of testing examples for drag-style video editing and conduct extensive experiments across a wide array of challenging editing tasks, such as motion, skeleton editing, etc, underscoring DragVideo can edit video in an intuitive, faithful to the user's intention manner, with nearly unnoticeable distortion and artifacts, while maintaining spatio-temporal consistency. While traditional prompt-based video editing fails to do the former two and directly applying image drag editing fails in the last, DragVideo's versatility and generality are emphasized. Github link: https://github.com/RickySkywalker/DragVideo-Official.
4/1/2024
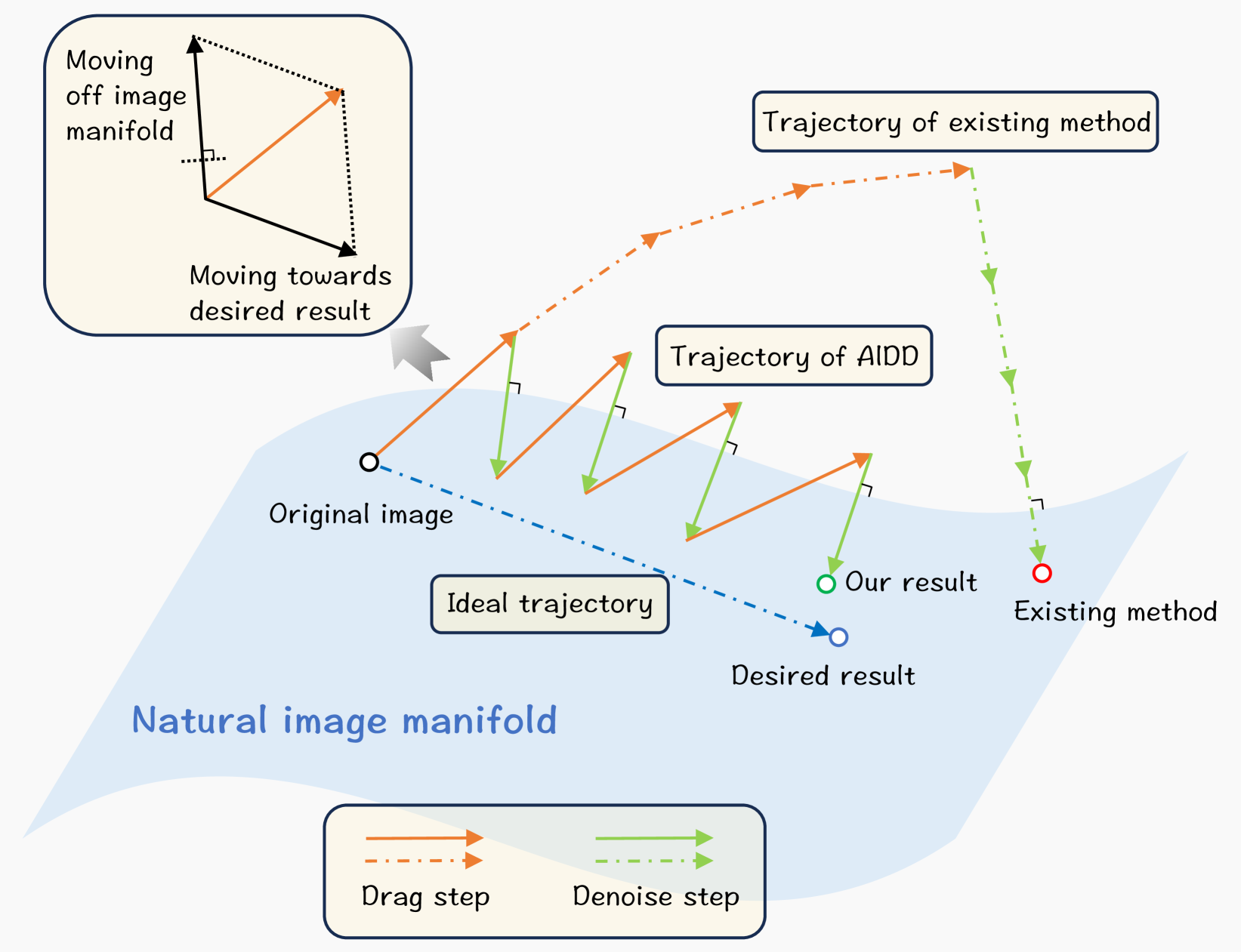
GoodDrag: Towards Good Practices for Drag Editing with Diffusion Models
Zewei Zhang, Huan Liu, Jun Chen, Xiangyu Xu
0
0
In this paper, we introduce GoodDrag, a novel approach to improve the stability and image quality of drag editing. Unlike existing methods that struggle with accumulated perturbations and often result in distortions, GoodDrag introduces an AlDD framework that alternates between drag and denoising operations within the diffusion process, effectively improving the fidelity of the result. We also propose an information-preserving motion supervision operation that maintains the original features of the starting point for precise manipulation and artifact reduction. In addition, we contribute to the benchmarking of drag editing by introducing a new dataset, Drag100, and developing dedicated quality assessment metrics, Dragging Accuracy Index and Gemini Score, utilizing Large Multimodal Models. Extensive experiments demonstrate that the proposed GoodDrag compares favorably against the state-of-the-art approaches both qualitatively and quantitatively. The project page is https://gooddrag.github.io.
4/11/2024

E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
Yifan Gong, Zheng Zhan, Qing Jin, Yanyu Li, Yerlan Idelbayev, Xian Liu, Andrey Zharkov, Kfir Aberman, Sergey Tulyakov, Yanzhi Wang, Jian Ren
0
0
One highly promising direction for enabling flexible real-time on-device image editing is utilizing data distillation by leveraging large-scale text-to-image diffusion models to generate paired datasets used for training generative adversarial networks (GANs). This approach notably alleviates the stringent requirements typically imposed by high-end commercial GPUs for performing image editing with diffusion models. However, unlike text-to-image diffusion models, each distilled GAN is specialized for a specific image editing task, necessitating costly training efforts to obtain models for various concepts. In this work, we introduce and address a novel research direction: can the process of distilling GANs from diffusion models be made significantly more efficient? To achieve this goal, we propose a series of innovative techniques. First, we construct a base GAN model with generalized features, adaptable to different concepts through fine-tuning, eliminating the need for training from scratch. Second, we identify crucial layers within the base GAN model and employ Low-Rank Adaptation (LoRA) with a simple yet effective rank search process, rather than fine-tuning the entire base model. Third, we investigate the minimal amount of data necessary for fine-tuning, further reducing the overall training time. Extensive experiments show that we can efficiently empower GANs with the ability to perform real-time high-quality image editing on mobile devices with remarkably reduced training and storage costs for each concept.
6/4/2024