Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis

0

Sign in to get full access
Overview
- This paper introduces a novel approach called "Draw an Audio" for generating audio from video inputs using multi-task learning.
- The method leverages advances in diffusion models and language models to generate high-quality audio from silent videos.
- The authors demonstrate the effectiveness of their approach on various video-to-audio synthesis tasks, including speech generation, sound effects, and music.
Plain English Explanation
The paper presents a new way to create audio from video clips, called "Draw an Audio". The key idea is to use machine learning models that can learn from both video and audio data, and then use that knowledge to generate realistic-sounding audio to match a silent video.
The researchers use a type of machine learning model called a diffusion model, which is good at generating new data like images or audio from scratch. They combine this with a language model, which is good at understanding and generating human-like text. By training these models on lots of video and audio data, they can learn the connections between what's happening in a video and the sounds that should go with it.
When you give the "Draw an Audio" system a new silent video, it can then use this learned knowledge to produce an original audio track that matches the visuals. This could be used to add speech, sound effects, or even music to videos that were originally silent.
The paper shows that this approach outperforms previous methods for video-to-audio synthesis, producing higher quality and more realistic-sounding audio. This could be useful for a wide range of applications, from making home movies more engaging to creating special effects for films and TV shows.
Technical Explanation
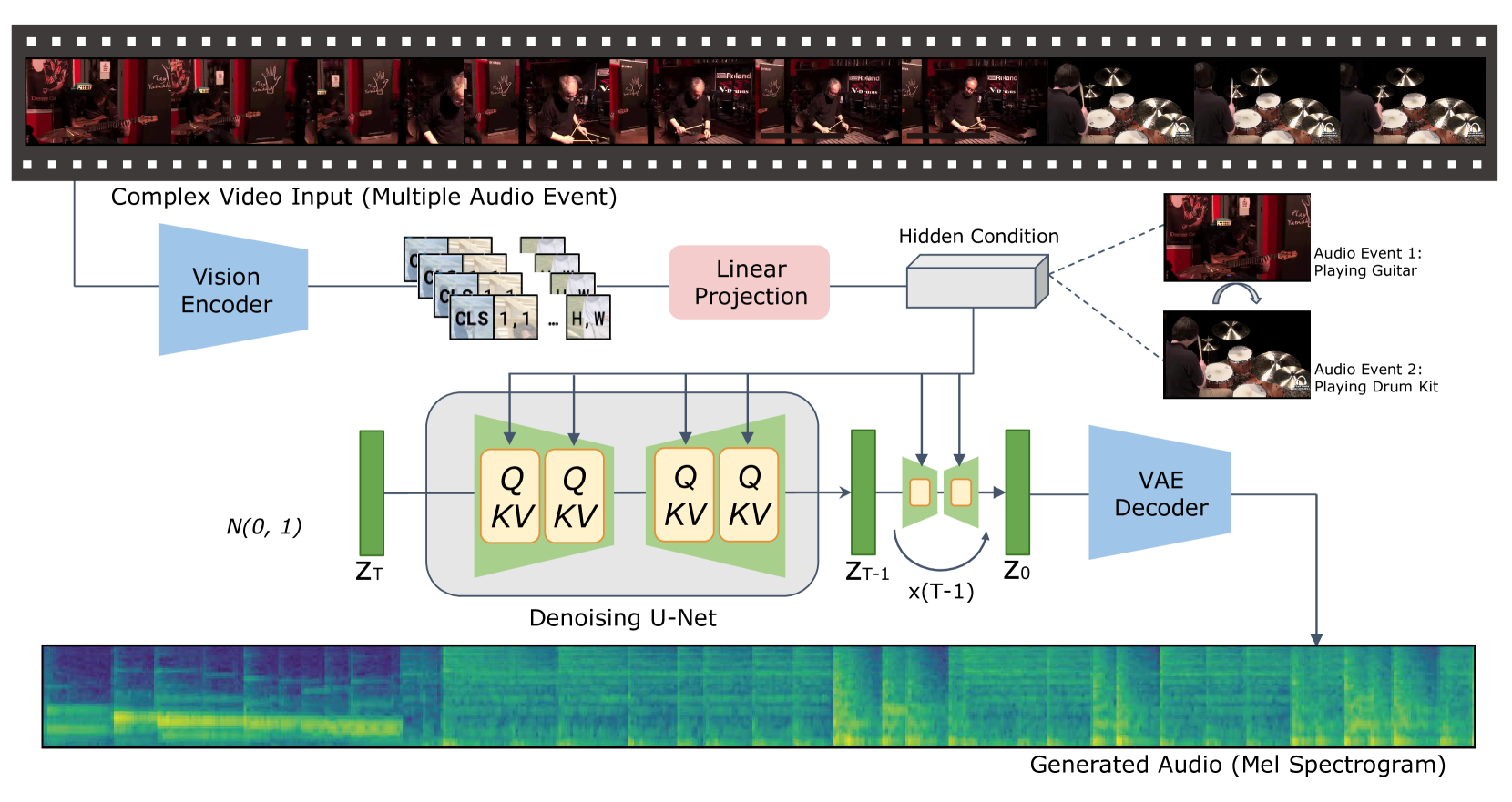
The key innovation in this paper is the introduction of a multi-task learning framework for video-to-audio synthesis, called "Draw an Audio". The authors leverage recent advances in diffusion models and language models to generate high-quality audio that corresponds to silent video inputs.
The architecture consists of a video encoder that extracts visual features, a text encoder that encodes text instructions, and a diffusion-based audio generator. By training this model on pairs of videos and corresponding audio/text data, it learns to associate visual cues with the appropriate audio and textual descriptions.
During inference, the model can take in a silent video and either generate matching audio or produce text descriptions of the sounds that should accompany the visuals. The authors demonstrate the effectiveness of their approach on a variety of video-to-audio synthesis tasks, including speech generation, sound effects, and music.
Critical Analysis
The paper presents a compelling approach to video-to-audio synthesis, but there are a few potential limitations and areas for further research:
-
The evaluation is primarily focused on subjective human ratings, which could be biased or inconsistent. Incorporating more objective metrics, such as audio quality or alignment with the video, could provide a more comprehensive assessment.
-
The model is trained on a relatively small dataset, which may limit its ability to generalize to a wider range of video and audio content. Exploring ways to scale up the training data or use transfer learning could help improve the model's performance.
-
The text-to-audio generation component is still quite limited, producing only short descriptions rather than full audio tracks. Enhancing this capability could expand the system's usefulness in applications like audio narration or audio-visual storytelling.
Overall, the "Draw an Audio" approach represents an exciting step forward in video-to-audio synthesis and opens up numerous possibilities for further research and real-world applications.
Conclusion
This paper introduces a novel multi-task learning framework called "Draw an Audio" that can generate high-quality audio to accompany silent video inputs. By leveraging advances in diffusion models and language models, the system is able to associate visual cues with appropriate audio and textual descriptions.
The authors demonstrate the effectiveness of their approach on a variety of video-to-audio synthesis tasks, including speech generation, sound effects, and music. While the method has some limitations, it represents a significant advancement in the field and could have wide-ranging applications in areas like filmmaking, video production, and interactive media.
As machine learning continues to evolve, techniques like "Draw an Audio" will likely become increasingly important for bridging the gap between visual and auditory information, enabling more immersive and engaging experiences across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Qi Yang, Binjie Mao, Zili Wang, Xing Nie, Pengfei Gao, Ying Guo, Cheng Zhen, Pengfei Yan, Shiming Xiang
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
Read more9/11/2024

0
FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Kai Chen
We study Neural Foley, the automatic generation of high-quality sound effects synchronizing with videos, enabling an immersive audio-visual experience. Despite its wide range of applications, existing approaches encounter limitations when it comes to simultaneously synthesizing high-quality and video-aligned (i.e.,, semantic relevant and temporal synchronized) sounds. To overcome these limitations, we propose FoleyCrafter, a novel framework that leverages a pre-trained text-to-audio model to ensure high-quality audio generation. FoleyCrafter comprises two key components: the semantic adapter for semantic alignment and the temporal controller for precise audio-video synchronization. The semantic adapter utilizes parallel cross-attention layers to condition audio generation on video features, producing realistic sound effects that are semantically relevant to the visual content. Meanwhile, the temporal controller incorporates an onset detector and a timestampbased adapter to achieve precise audio-video alignment. One notable advantage of FoleyCrafter is its compatibility with text prompts, enabling the use of text descriptions to achieve controllable and diverse video-to-audio generation according to user intents. We conduct extensive quantitative and qualitative experiments on standard benchmarks to verify the effectiveness of FoleyCrafter. Models and codes are available at https://github.com/open-mmlab/FoleyCrafter.
Read more7/2/2024
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024

0
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Santiago Pascual, Chunghsin Yeh, Ioannis Tsiamas, Joan Serr`a
Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Read more7/16/2024