Dual-Branch Network for Portrait Image Quality Assessment

0
🌐
Sign in to get full access
Overview
- The paper introduces a dual-branch network for assessing the quality of portrait images.
- The network utilizes two backbone networks to extract quality-aware features from the entire portrait image and the facial image within it.
- The backbone networks are pre-trained on large-scale video and facial image quality assessment datasets to enhance their feature representation.
- The network also leverages an image scene classification and quality assessment model to capture additional quality-aware and scene-specific features.
- The final quality score is predicted by concatenating these features and passing them through a multi-perception layer.
- The model is trained using a fidelity loss in a learning-to-rank manner to address inconsistencies in the portrait image quality assessment dataset.
Plain English Explanation
Portrait images often feature a person as the main subject against a background. With the rise of mobile devices, people can easily capture portrait images anytime and anywhere. However, the quality of these portraits can suffer due to various factors, such as unfavorable environmental conditions, poor photography techniques, and lower-quality camera equipment.
To address this issue, the researchers developed a dual-branch network for portrait image quality assessment (PIQA). This network uses two separate neural networks to analyze the quality of the portrait image as a whole and the quality of the person's face within the image.
To enhance the quality-aware features extracted by the neural networks, the researchers pre-trained them on large-scale video and facial image quality assessment datasets, LSVQ and GFIQA, respectively. This helps the networks better understand what constitutes high-quality visual content.
Additionally, the researchers incorporated an image scene classification and quality assessment model, LIQE, to capture the quality-aware and scene-specific features of the portrait image.
Finally, the network combines all these features and predicts a quality score for the portrait image using a multi-perception layer. The model is trained using a fidelity loss in a learning-to-rank manner, which helps address inconsistencies in the portrait image quality assessment dataset.
Technical Explanation
The proposed dual-branch network for portrait image quality assessment (PIQA) uses two backbone networks (Swin Transformer-B) to extract quality-aware features from the entire portrait image and the facial image cropped from it. To enhance the quality-aware feature representation of the backbones, the researchers pre-trained them on the large-scale video quality assessment dataset LSVQ and the large-scale facial image quality assessment dataset GFIQA.
In addition, the researchers leveraged LIQE, an image scene classification and quality assessment model, to capture the quality-aware and scene-specific features as auxiliary features. Finally, the features from the two backbone networks and the LIQE model are concatenated and regressed into quality scores via a multi-perception layer (MLP).
The model is trained using the fidelity loss in a learning-to-rank manner to mitigate inconsistencies in quality scores in the portrait image quality assessment dataset PIQ.
Critical Analysis
The paper presents a comprehensive approach to assessing the quality of portrait images, which is an important task given the prevalence of such images captured on mobile devices. The use of a dual-branch network to separately analyze the salient person and the background is a thoughtful design choice, as these elements can independently impact the overall image quality.
The pre-training of the backbone networks on large-scale video and facial image quality assessment datasets is a valuable contribution, as it helps the model better understand the characteristics of high-quality visual content. Additionally, the incorporation of the LIQE model to capture scene-specific quality-aware features is a novel approach that likely improves the model's ability to assess the overall image quality.
However, the paper does not thoroughly discuss the potential limitations of the proposed approach. It would be valuable to understand the model's performance in edge cases, such as portraits with unusual compositions or lighting conditions, and how it compares to human-level quality assessment. Additionally, the paper could explore the interpretability of the model's predictions, which would be helpful for understanding the underlying factors driving the quality assessment.
Furthermore, the dataset used for training and evaluation, PIQ, is not publicly available, which may limit the ability of other researchers to build upon this work or validate the findings. Releasing the dataset or using a publicly available alternative would enhance the transparency and reproducibility of the research.
Conclusion
Overall, the proposed dual-branch network for portrait image quality assessment (PIQA) is a promising approach to addressing the challenge of assessing the quality of portrait images captured in diverse real-world conditions. By leveraging pre-trained backbone networks and incorporating scene-specific quality-aware features, the model demonstrates superior performance on the PIQ dataset.
The research highlights the importance of considering the salient person and background elements separately when evaluating portrait image quality, and the potential benefits of cross-task pre-training to enhance the model's feature representation. As mobile photography continues to evolve, tools like the PIQA network could help users and applications better understand and improve the visual quality of their portrait images.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Dual-Branch Network for Portrait Image Quality Assessment
Wei Sun, Weixia Zhang, Yanwei Jiang, Haoning Wu, Zicheng Zhang, Jun Jia, Yingjie Zhou, Zhongpeng Ji, Xiongkuo Min, Weisi Lin, Guangtao Zhai
Portrait images typically consist of a salient person against diverse backgrounds. With the development of mobile devices and image processing techniques, users can conveniently capture portrait images anytime and anywhere. However, the quality of these portraits may suffer from the degradation caused by unfavorable environmental conditions, subpar photography techniques, and inferior capturing devices. In this paper, we introduce a dual-branch network for portrait image quality assessment (PIQA), which can effectively address how the salient person and the background of a portrait image influence its visual quality. Specifically, we utilize two backbone networks (textit{i.e.,} Swin Transformer-B) to extract the quality-aware features from the entire portrait image and the facial image cropped from it. To enhance the quality-aware feature representation of the backbones, we pre-train them on the large-scale video quality assessment dataset LSVQ and the large-scale facial image quality assessment dataset GFIQA. Additionally, we leverage LIQE, an image scene classification and quality assessment model, to capture the quality-aware and scene-specific features as the auxiliary features. Finally, we concatenate these features and regress them into quality scores via a multi-perception layer (MLP). We employ the fidelity loss to train the model via a learning-to-rank manner to mitigate inconsistencies in quality scores in the portrait image quality assessment dataset PIQ. Experimental results demonstrate that the proposed model achieves superior performance in the PIQ dataset, validating its effectiveness. The code is available at url{https://github.com/sunwei925/DN-PIQA.git}.
Read more5/15/2024
0
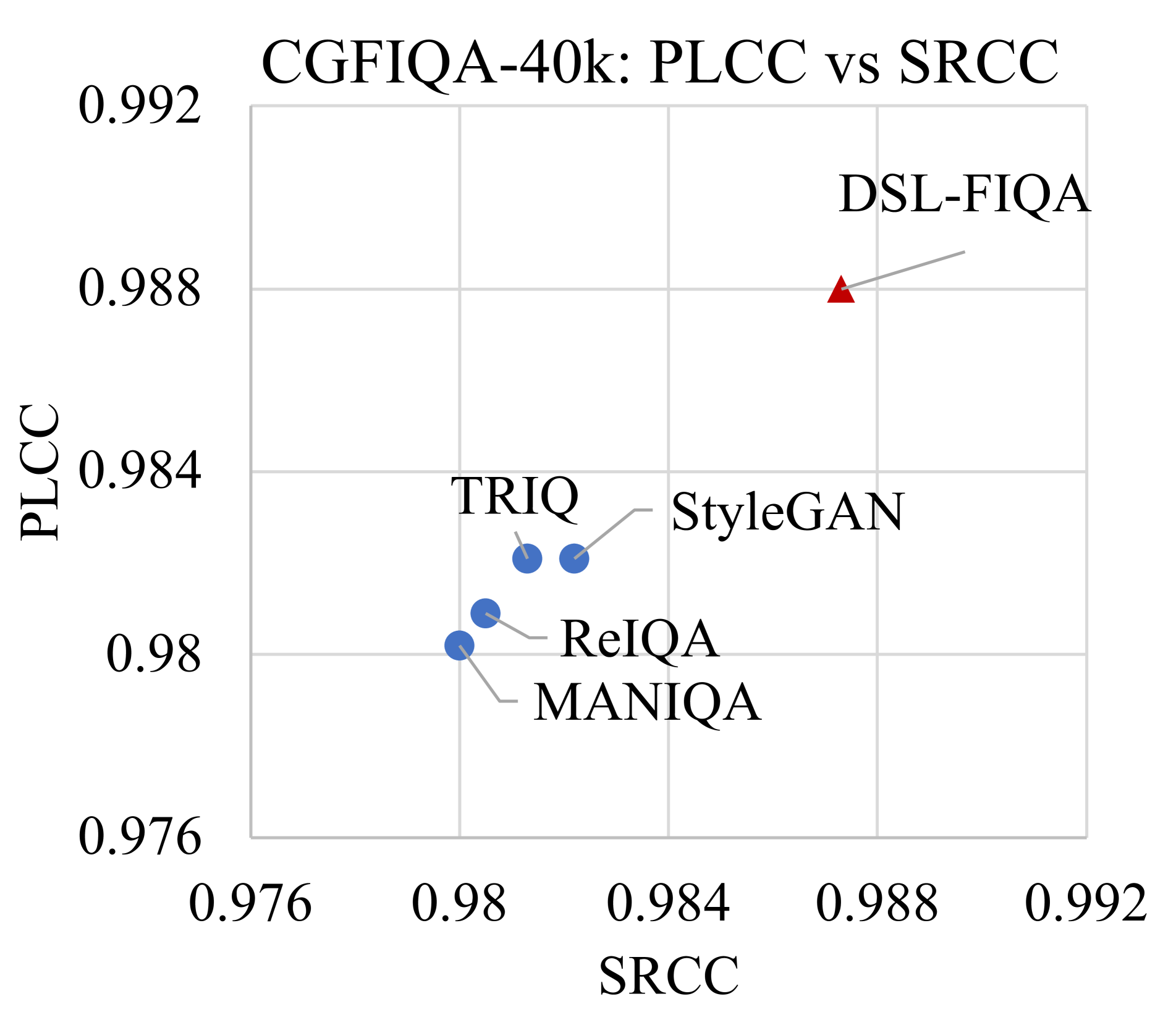
DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer
Wei-Ting Chen, Gurunandan Krishnan, Qiang Gao, Sy-Yen Kuo, Sizhuo Ma, Jian Wang
Generic Face Image Quality Assessment (GFIQA) evaluates the perceptual quality of facial images, which is crucial in improving image restoration algorithms and selecting high-quality face images for downstream tasks. We present a novel transformer-based method for GFIQA, which is aided by two unique mechanisms. First, a Dual-Set Degradation Representation Learning (DSL) mechanism uses facial images with both synthetic and real degradations to decouple degradation from content, ensuring generalizability to real-world scenarios. This self-supervised method learns degradation features on a global scale, providing a robust alternative to conventional methods that use local patch information in degradation learning. Second, our transformer leverages facial landmarks to emphasize visually salient parts of a face image in evaluating its perceptual quality. We also introduce a balanced and diverse Comprehensive Generic Face IQA (CGFIQA-40k) dataset of 40K images carefully designed to overcome the biases, in particular the imbalances in skin tone and gender representation, in existing datasets. Extensive analysis and evaluation demonstrate the robustness of our method, marking a significant improvement over prior methods.
Read more6/17/2024

0
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Zewen Chen, Sunhan Xu, Yun Zeng, Haochen Guo, Jian Guo, Shuai Liu, Juan Wang, Bing Li, Weiming Hu, Dehua Liu, Hesong Li
With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.
Read more9/4/2024

0
Assessing UHD Image Quality from Aesthetics, Distortions, and Saliency
Wei Sun, Weixia Zhang, Yuqin Cao, Linhan Cao, Jun Jia, Zijian Chen, Zicheng Zhang, Xiongkuo Min, Guangtao Zhai
UHD images, typically with resolutions equal to or higher than 4K, pose a significant challenge for efficient image quality assessment (IQA) algorithms, as adopting full-resolution images as inputs leads to overwhelming computational complexity and commonly used pre-processing methods like resizing or cropping may cause substantial loss of detail. To address this problem, we design a multi-branch deep neural network (DNN) to assess the quality of UHD images from three perspectives: global aesthetic characteristics, local technical distortions, and salient content perception. Specifically, aesthetic features are extracted from low-resolution images downsampled from the UHD ones, which lose high-frequency texture information but still preserve the global aesthetics characteristics. Technical distortions are measured using a fragment image composed of mini-patches cropped from UHD images based on the grid mini-patch sampling strategy. The salient content of UHD images is detected and cropped to extract quality-aware features from the salient regions. We adopt the Swin Transformer Tiny as the backbone networks to extract features from these three perspectives. The extracted features are concatenated and regressed into quality scores by a two-layer multi-layer perceptron (MLP) network. We employ the mean square error (MSE) loss to optimize prediction accuracy and the fidelity loss to optimize prediction monotonicity. Experimental results show that the proposed model achieves the best performance on the UHD-IQA dataset while maintaining the lowest computational complexity, demonstrating its effectiveness and efficiency. Moreover, the proposed model won first prize in ECCV AIM 2024 UHD-IQA Challenge. The code is available at https://github.com/sunwei925/UIQA.
Read more9/4/2024