Dual-Decoupling Learning and Metric-Adaptive Thresholding for Semi-Supervised Multi-Label Learning

0

Sign in to get full access
Overview
- This paper proposes a semi-supervised multi-label learning approach that combines dual-decoupling learning and metric-adaptive thresholding.
- The dual-decoupling learning technique aims to improve the model's generalization by separating the learning of feature representations and the prediction of labels.
- The metric-adaptive thresholding method adjusts the classification thresholds for each label based on the model's confidence, which helps with imbalanced label distributions.
- The authors evaluate their approach on several multi-label datasets and show improvements over state-of-the-art semi-supervised multi-label learning methods.
Plain English Explanation
In this paper, the researchers present a new way to tackle the challenge of multi-label learning in a semi-supervised setting. Multi-label learning is when an example can have multiple labels assigned to it, and semi-supervised learning is when the model has access to both labeled and unlabeled data.
The key ideas behind their approach are:
-
Dual-Decoupling Learning: Instead of learning the feature representation and label prediction together, the model learns these two components separately. This helps the model generalize better to new examples.
-
Metric-Adaptive Thresholding: The model adjusts the classification thresholds for each label dynamically, based on how confident it is in its predictions. This is particularly helpful when the distribution of labels is imbalanced, meaning some labels are much more common than others.
By combining these two techniques, the researchers show that their model outperforms other state-of-the-art semi-supervised multi-label learning methods on several benchmark datasets. This suggests that their approach is a promising direction for improving the performance of multi-label learning models, especially when only a limited amount of labeled data is available.
Technical Explanation
The paper proposes a semi-supervised multi-label learning approach that consists of two main components: Dual-Decoupling Learning and Metric-Adaptive Thresholding.
Dual-Decoupling Learning: The researchers decouple the learning of the feature representation and the prediction of labels into two separate modules. The feature representation module learns a general feature extractor, while the prediction module learns to map the features to the relevant labels. This separation allows the model to better generalize to new examples, as the feature representation is not overly specialized to the training data.
Metric-Adaptive Thresholding: The second component of the proposed approach is a method for dynamically adjusting the classification thresholds for each label. This is particularly important in multi-label learning, where the distribution of labels is often imbalanced. The model learns a set of adaptive thresholds that depend on the model's confidence in its predictions for each label. This helps the model make more accurate predictions, especially for the rarer labels.
The authors evaluate their approach on several multi-label datasets and compare it to state-of-the-art semi-supervised multi-label learning methods. The results show that their dual-decoupling learning and metric-adaptive thresholding techniques lead to significant improvements in performance, demonstrating the effectiveness of their approach.
Critical Analysis
The paper presents a well-designed and empirically validated approach to semi-supervised multi-label learning. The key strengths of the proposed method are:
-
Dual-Decoupling Learning: Separating the feature representation and label prediction tasks allows the model to learn a more generalizable feature extractor, which is an important advantage in semi-supervised settings where the labeled data may not be representative of the entire data distribution.
-
Metric-Adaptive Thresholding: Dynamically adjusting the classification thresholds for each label based on the model's confidence is a clever way to address the challenges posed by imbalanced label distributions, a common issue in multi-label learning.
However, the paper does not discuss potential limitations or future research directions in depth. For example, it would be interesting to see how the method performs on extremely large-scale multi-label datasets or how it could be extended to incorporate additional sources of unlabeled data, such as text or image data, to further improve performance.
Additionally, the paper would benefit from a more thorough discussion of the theoretical motivations behind the dual-decoupling learning and metric-adaptive thresholding techniques, as well as their connections to prior work in semi-supervised and multi-label learning.
Conclusion
In summary, this paper presents a novel semi-supervised multi-label learning approach that combines dual-decoupling learning and metric-adaptive thresholding. The experimental results demonstrate the effectiveness of this approach, suggesting that it is a promising direction for improving the performance of multi-label learning models, especially when only limited labeled data is available. The paper provides a solid technical contribution, but could be strengthened by a more detailed discussion of the method's limitations and potential future research directions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual-Decoupling Learning and Metric-Adaptive Thresholding for Semi-Supervised Multi-Label Learning
Jia-Hao Xiao, Ming-Kun Xie, Heng-Bo Fan, Gang Niu, Masashi Sugiyama, Sheng-Jun Huang
Semi-supervised multi-label learning (SSMLL) is a powerful framework for leveraging unlabeled data to reduce the expensive cost of collecting precise multi-label annotations. Unlike semi-supervised learning, one cannot select the most probable label as the pseudo-label in SSMLL due to multiple semantics contained in an instance. To solve this problem, the mainstream method developed an effective thresholding strategy to generate accurate pseudo-labels. Unfortunately, the method neglected the quality of model predictions and its potential impact on pseudo-labeling performance. In this paper, we propose a dual-perspective method to generate high-quality pseudo-labels. To improve the quality of model predictions, we perform dual-decoupling to boost the learning of correlative and discriminative features, while refining the generation and utilization of pseudo-labels. To obtain proper class-wise thresholds, we propose the metric-adaptive thresholding strategy to estimate the thresholds, which maximize the pseudo-label performance for a given metric on labeled data. Experiments on multiple benchmark datasets show the proposed method can achieve the state-of-the-art performance and outperform the comparative methods with a significant margin.
Read more7/29/2024

0
Self Adaptive Threshold Pseudo-labeling and Unreliable Sample Contrastive Loss for Semi-supervised Image Classification
Xuerong Zhang, Li Huang, Jing Lv, Ming Yang
Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. However, pseudo-labeling-based semi-supervised approaches suffer from two problems in image classification: (1) Existing methods might fail to adopt suitable thresholds since they either use a pre-defined/fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. (2) Discarding unlabeled data with confidence below the thresholds results in the loss of discriminating information. To solve these issues, we develop an effective method to make sufficient use of unlabeled data. Specifically, we design a self adaptive threshold pseudo-labeling strategy, which thresholds for each class can be dynamically adjusted to increase the number of reliable samples. Meanwhile, in order to effectively utilise unlabeled data with confidence below the thresholds, we propose an unreliable sample contrastive loss to mine the discriminative information in low-confidence samples by learning the similarities and differences between sample features. We evaluate our method on several classification benchmarks under partially labeled settings and demonstrate its superiority over the other approaches.
Read more7/8/2024
🏋️
0
New!Pseudo-Labeling Based Practical Semi-Supervised Meta-Training for Few-Shot Learning
Xingping Dong, Tianran Ouyang, Shengcai Liao, Bo Du, Ling Shao
Most existing few-shot learning (FSL) methods require a large amount of labeled data in meta-training, which is a major limit. To reduce the requirement of labels, a semi-supervised meta-training (SSMT) setting has been proposed for FSL, which includes only a few labeled samples and numbers of unlabeled samples in base classes. However, existing methods under this setting require class-aware sample selection from the unlabeled set, which violates the assumption of unlabeled set. In this paper, we propose a practical semi-supervised meta-training setting with truly unlabeled data to facilitate the applications of FSL in realistic scenarios. To better utilize both the labeled and truly unlabeled data, we propose a simple and effective meta-training framework, called pseudo-labeling based meta-learning (PLML). Firstly, we train a classifier via common semi-supervised learning (SSL) and use it to obtain the pseudo-labels of unlabeled data. Then we build few-shot tasks from labeled and pseudo-labeled data and design a novel finetuning method with feature smoothing and noise suppression to better learn the FSL model from noise labels. Surprisingly, through extensive experiments across two FSL datasets, we find that this simple meta-training framework effectively prevents the performance degradation of various FSL models under limited labeled data, and also significantly outperforms the state-of-the-art SSMT models. Besides, benefiting from meta-training, our method also improves two representative SSL algorithms as well.
Read more9/17/2024
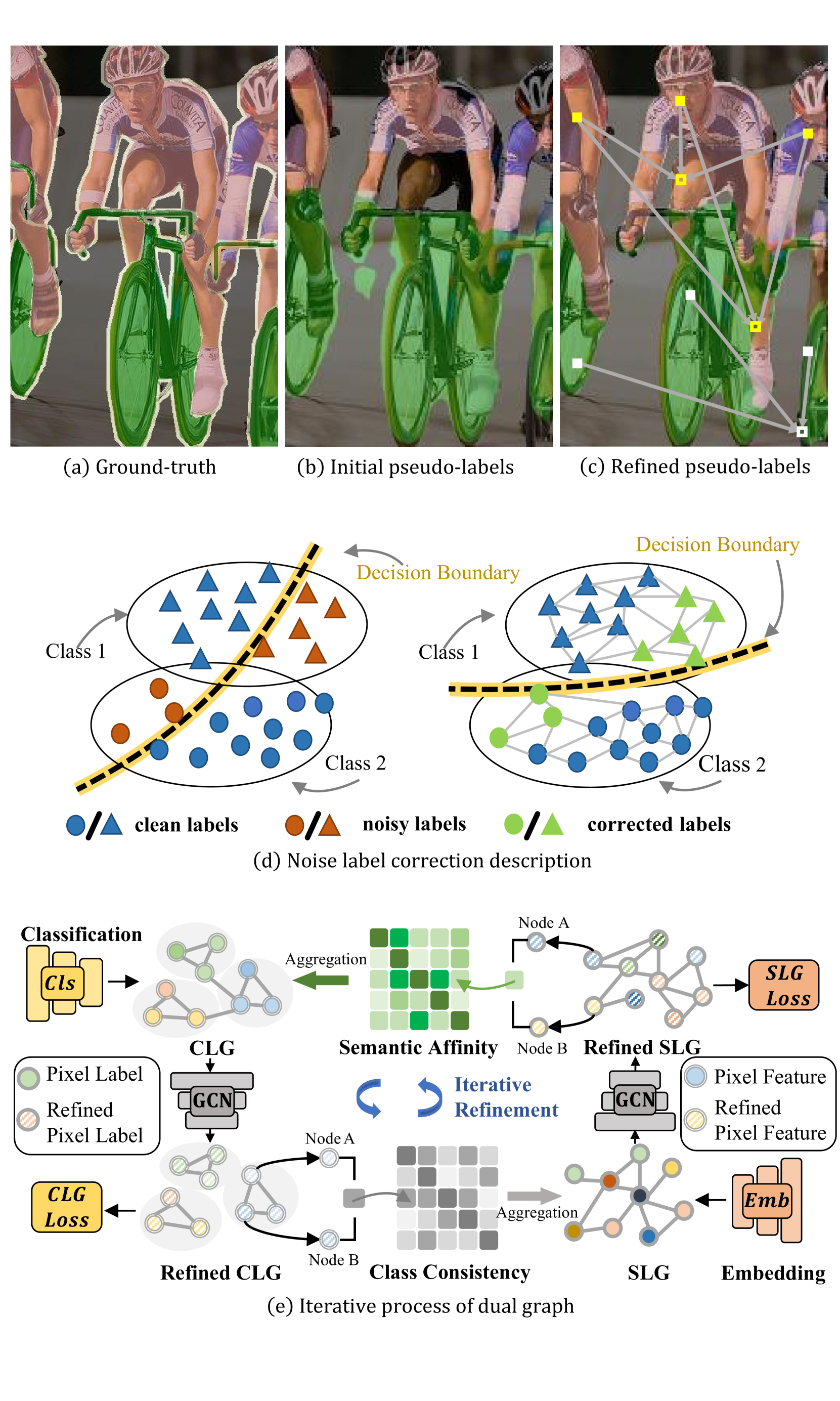
0
Multi-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
Hui Xiao, Yuting Hong, Li Dong, Diqun Yan, Jiayan Zhuang, Junjie Xiong, Dongtai Liang, Chengbin Peng
Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
Read more4/11/2024