Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
2403.18257
0
0
Abstract
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new model called "Dual-path Mamba" for speech separation, which aims to improve upon previous state-space models.
- The model uses a bidirectional and selective approach to capture both short-term and long-term dependencies in speech signals.
- The authors conduct experiments to evaluate the performance of their model on several speech separation tasks and compare it to other state-of-the-art methods.
Plain English Explanation
The goal of speech separation is to isolate individual voices or sounds from an audio recording that contains multiple speakers or sources. This is an important task for applications like voice assistants, hearing aids, and audio conferencing.
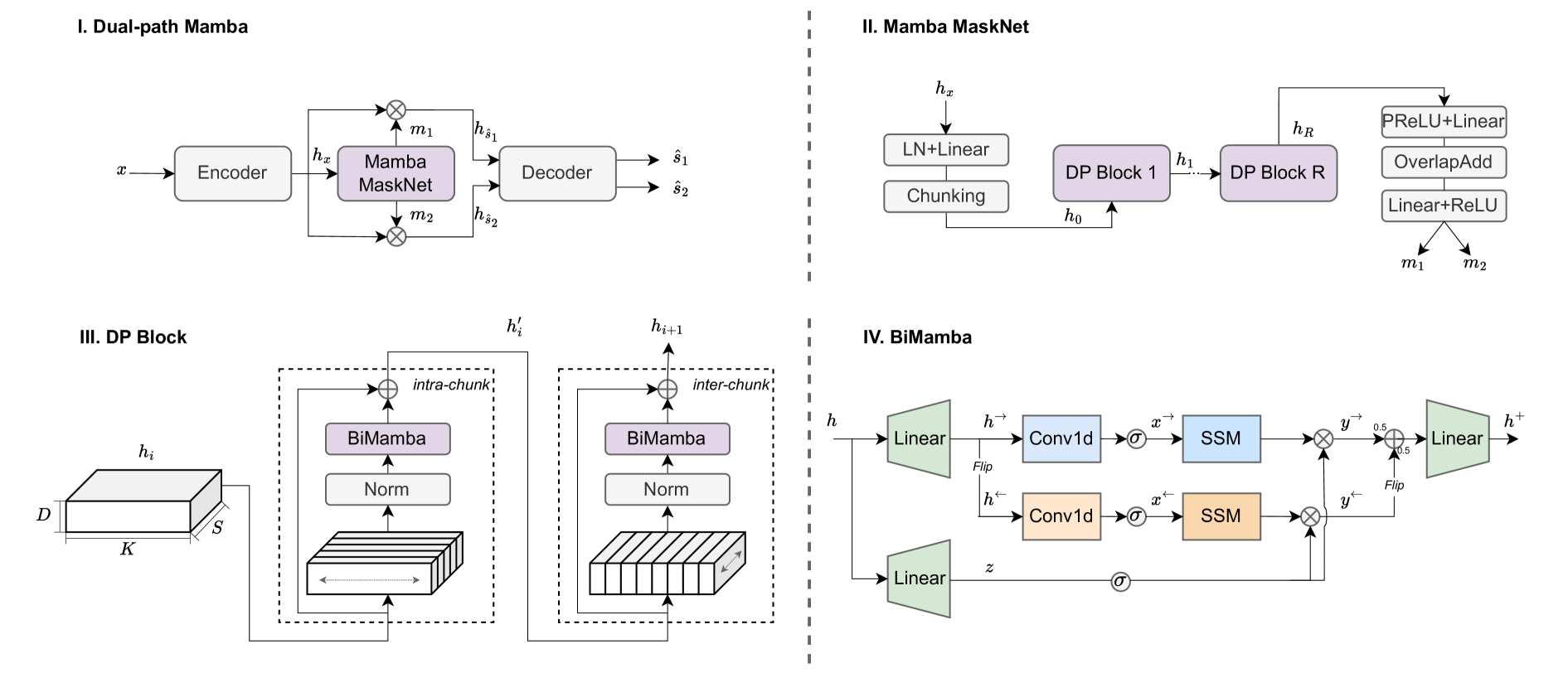
The Dual-path Mamba model proposed in this paper takes a novel approach to speech separation. It uses a bidirectional and selective state-space model to capture both short-term and long-term patterns in the speech signals.
The key idea is to use two parallel "paths" in the model - one to focus on short-term dependencies and one to focus on long-term dependencies. This allows the model to better understand the complex structure of speech and separate the individual voices or sounds more effectively.
The authors compare the Dual-path Mamba model to other state-of-the-art speech separation approaches and show that it outperforms them on several benchmark tasks. This suggests that the bidirectional and selective nature of the model is a promising direction for advancing the state of the art in speech separation.
Technical Explanation
The Dual-path Mamba model is based on a state-space framework, which models the speech signals as a sequence of hidden states that evolve over time. The key innovation is the use of a bidirectional and selective state-space structure to capture both short-term and long-term dependencies in the speech.
Specifically, the model has two parallel "paths" - one that focuses on short-term dependencies and one that focuses on long-term dependencies. The short-term path uses a recurrent neural network to model the immediate context, while the long-term path uses a transformer-based architecture to model longer-range temporal patterns.
The outputs of the two paths are then combined using a selective mechanism that learns to emphasize the most relevant information for the speech separation task.
The authors evaluate the Dual-path Mamba model on several speech separation benchmarks, including the popular Wall Street Journal (WSJ0-2mix) and LibriSpeech (Libri2Mix) datasets. They show that their model outperforms other state-of-the-art approaches, such as transformer-based models and traditional deep learning methods.
Critical Analysis
The Dual-path Mamba model represents a promising advancement in speech separation, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The use of both a recurrent neural network and a transformer-based architecture may increase the computational complexity of the model, making it less practical for real-time or resource-constrained applications.
-
Robustness to Noise: The paper does not extensively evaluate the model's performance on noisy speech signals, which are common in real-world scenarios. Further testing on noise-robust speech separation would be valuable.
-
Interpretability: As with many deep learning models, the internal workings of the Dual-path Mamba model may be difficult to interpret. Exploring ways to make the model more transparent could help researchers understand its strengths and limitations better.
-
Generalization: The experiments in the paper focus on specific speech separation datasets. Evaluating the model's performance on a wider range of speech separation tasks and datasets would help demonstrate its broader applicability.
Overall, the Dual-path Mamba model is a promising step forward in speech separation, but additional research and development may be needed to address these potential limitations and further advance the state of the art.
Conclusion
The Dual-path Mamba model introduced in this paper represents a novel approach to speech separation that combines bidirectional and selective state-space modeling to capture both short-term and long-term dependencies in speech signals. The authors' experiments show that their model outperforms other state-of-the-art methods on several speech separation benchmarks, suggesting that this approach is a promising direction for advancing the field.
While the Dual-path Mamba model has some potential limitations, such as computational complexity and the need for further robustness and interpretability testing, the core ideas behind the model represent an important contribution to the ongoing research on speech separation. As the field continues to evolve, the Dual-path Mamba approach could inspire new avenues of exploration and lead to even more powerful speech separation techniques with real-world applications in areas like voice assistants, hearing aids, and audio conferencing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SPMamba: State-space model is all you need in speech separation
Kai Li, Guo Chen
0
0
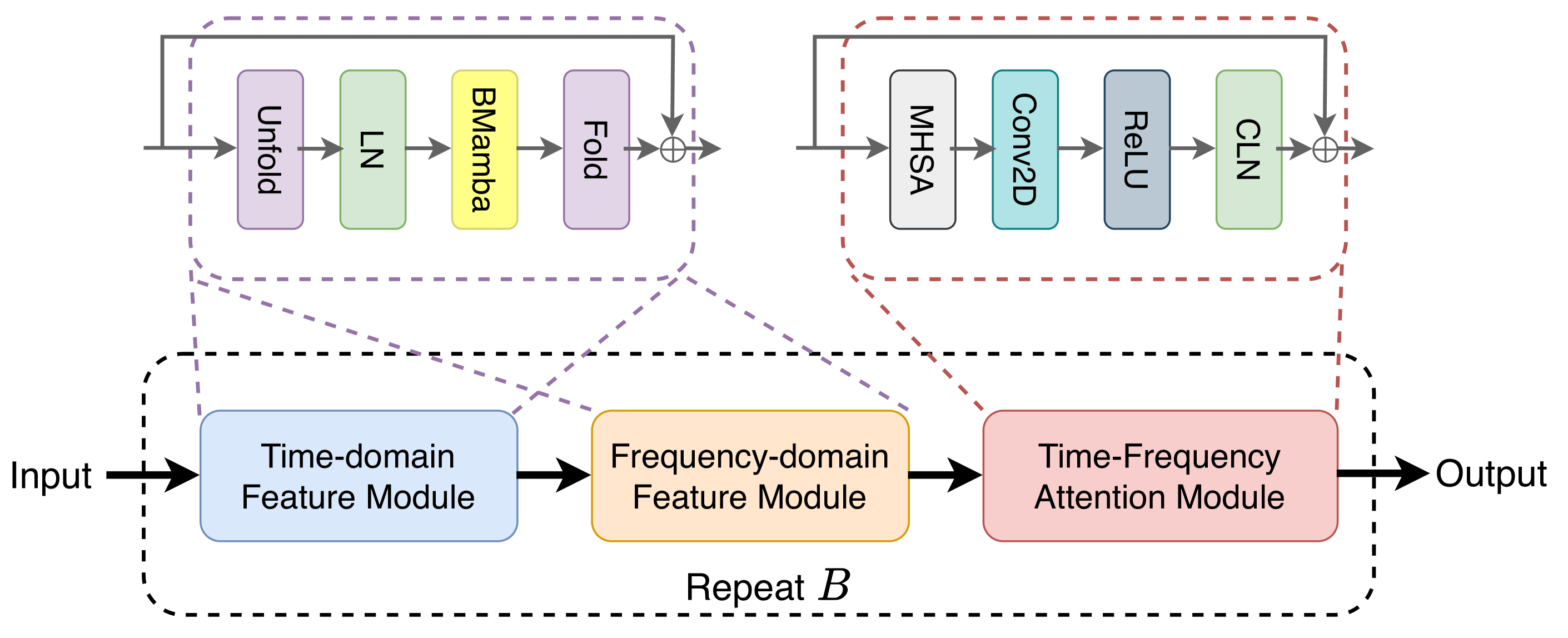
In speech separation, both CNN- and Transformer-based models have demonstrated robust separation capabilities, garnering significant attention within the research community. However, CNN-based methods have limited modelling capability for long-sequence audio, leading to suboptimal separation performance. Conversely, Transformer-based methods are limited in practical applications due to their high computational complexity. Notably, within computer vision, Mamba-based methods have been celebrated for their formidable performance and reduced computational requirements. In this paper, we propose a network architecture for speech separation using a state-space model, namely SPMamba. We adopt the TF-GridNet model as the foundational framework and substitute its Transformer component with a bidirectional Mamba module, aiming to capture a broader range of contextual information. Our experimental results reveal an important role in the performance aspects of Mamba-based models. SPMamba demonstrates superior performance with a significant advantage over existing separation models in a dataset built on Librispeech. Notably, SPMamba achieves a substantial improvement in separation quality, with a 2.42 dB enhancement in SI-SNRi compared to the TF-GridNet. The source code for SPMamba is publicly accessible at https://github.com/JusperLee/SPMamba .
4/3/2024

MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
Ali Behrouz, Michele Santacatterina, Ramin Zabih
0
0
Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
4/1/2024
🔎
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Xiongxiao Xu, Yueqing Liang, Baixiang Huang, Zhiling Lan, Kai Shu
0
0
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
4/24/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024