Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
2404.14757
0
0
🔎
Abstract
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
Create account to get full access
Overview
- Time series forecasting is an important problem with applications in various fields like weather, finance, and scientific simulations.
- Transformers have proven effective in capturing dependencies, but their quadratic complexity limits their use in long-range time series forecasting.
- Recent progress on state space models (SSMs) like Mamba have shown promise in modeling long-range dependencies due to their subquadratic complexity.
- This paper introduces a hybrid framework called Mambaformer that combines Mamba for long-range dependency and Transformer for short-range dependency to address long-short range forecasting.
Plain English Explanation
Time series forecasting is the task of predicting future values based on past data. This is crucial in areas like weather forecasting, stock market analysis, and scientific simulations. Transformers, a type of machine learning model, have shown great success in capturing dependencies in data. However, the way they process information, known as the attention mechanism, has a significant drawback – it scales quadratically with the length of the input. This makes it difficult to use transformers for forecasting long-range time series, where the data can be very extensive.
On the other hand, recent advancements in state space models (SSMs), like the Mamba model, have demonstrated impressive performance in modeling long-range dependencies. This is because SSMs have a more efficient, subquadratic computational complexity, allowing them to handle long sequences of data.
The researchers in this paper propose a hybrid approach called Mambaformer that combines the strengths of Mamba and Transformer models. Mambaformer uses Mamba to capture the long-range dependencies in the time series data, while the Transformer component focuses on the short-range relationships. By integrating these two complementary models, the researchers aim to achieve better performance in long-short range time series forecasting tasks.
Technical Explanation
The paper introduces a hybrid framework called Mambaformer that combines the Mamba state space model and the Transformer architecture for long-short range time series forecasting.
Transformers have proven effective in capturing dependencies, but their quadratic complexity of the attention mechanism prevents their widespread adoption in long-range time series forecasting tasks. Recent progress on state space models (SSMs), such as Mamba, have shown impressive performance in modeling long-range dependencies due to their subquadratic complexity.
The researchers investigate different hybrid architectures to combine the Mamba layer and the attention layer of the Transformer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform both Mamba and Transformer models in long-short range time series forecasting problems.
Critical Analysis
The paper presents a promising approach to addressing the limitations of Transformers in long-range time series forecasting by leveraging the strengths of Mamba, a state space model. The authors provide a thorough comparative analysis and demonstrate the effectiveness of the Mambaformer family of models.
However, the paper does not discuss potential limitations or caveats of the proposed approach. For example, it would be valuable to understand the computational trade-offs of the hybrid architecture compared to the individual Mamba and Transformer models, as well as the sensitivity of the Mambaformer to hyperparameter tuning or dataset characteristics.
Additionally, the paper would benefit from a more in-depth discussion of the specific mechanisms by which the Mamba and Transformer components interact and complement each other in the hybrid framework. A deeper exploration of the insights gained from this combination could further strengthen the contributions of the research.
Conclusion
This paper presents a novel hybrid framework called Mambaformer that combines the Mamba state space model and the Transformer architecture to address the limitations of Transformers in long-range time series forecasting. By leveraging the strengths of Mamba in modeling long-range dependencies and the Transformer in capturing short-range relationships, the Mambaformer family of models demonstrates improved performance over standalone Mamba and Transformer models.
The proposed approach holds promise for advancing the field of time series forecasting, with potential applications in various domains that rely on accurate long-short range predictions, such as weather forecasting, financial analysis, and scientific simulations. Further research could explore the scalability, robustness, and practical implications of the Mambaformer framework, as well as its adaptability to different types of time series data and forecasting tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Bi-Mamba+: Bidirectional Mamba for Time Series Forecasting
Aobo Liang, Xingguo Jiang, Yan Sun, Xiaohou Shi, Ke Li
0
0
Long-term time series forecasting (LTSF) provides longer insights into future trends and patterns. Over the past few years, deep learning models especially Transformers have achieved advanced performance in LTSF tasks. However, LTSF faces inherent challenges such as long-term dependencies capturing and sparse semantic characteristics. Recently, a new state space model (SSM) named Mamba is proposed. With the selective capability on input data and the hardware-aware parallel computing algorithm, Mamba has shown great potential in balancing predicting performance and computational efficiency compared to Transformers. To enhance Mamba's ability to preserve historical information in a longer range, we design a novel Mamba+ block by adding a forget gate inside Mamba to selectively combine the new features with the historical features in a complementary manner. Furthermore, we apply Mamba+ both forward and backward and propose Bi-Mamba+, aiming to promote the model's ability to capture interactions among time series elements. Additionally, multivariate time series data in different scenarios may exhibit varying emphasis on intra- or inter-series dependencies. Therefore, we propose a series-relation-aware decider that controls the utilization of channel-independent or channel-mixing tokenization strategy for specific datasets. Extensive experiments on 8 real-world datasets show that our model achieves more accurate predictions compared with state-of-the-art methods.
6/28/2024

MambaTS: Improved Selective State Space Models for Long-term Time Series Forecasting
Xiuding Cai, Yaoyao Zhu, Xueyao Wang, Yu Yao
0
0
In recent years, Transformers have become the de-facto architecture for long-term sequence forecasting (LTSF), but faces challenges such as quadratic complexity and permutation invariant bias. A recent model, Mamba, based on selective state space models (SSMs), has emerged as a competitive alternative to Transformer, offering comparable performance with higher throughput and linear complexity related to sequence length. In this study, we analyze the limitations of current Mamba in LTSF and propose four targeted improvements, leading to MambaTS. We first introduce variable scan along time to arrange the historical information of all the variables together. We suggest that causal convolution in Mamba is not necessary for LTSF and propose the Temporal Mamba Block (TMB). We further incorporate a dropout mechanism for selective parameters of TMB to mitigate model overfitting. Moreover, we tackle the issue of variable scan order sensitivity by introducing variable permutation training. We further propose variable-aware scan along time to dynamically discover variable relationships during training and decode the optimal variable scan order by solving the shortest path visiting all nodes problem during inference. Extensive experiments conducted on eight public datasets demonstrate that MambaTS achieves new state-of-the-art performance.
5/28/2024

Is Mamba Effective for Time Series Forecasting?
Zihan Wang, Fanheng Kong, Shi Feng, Ming Wang, Xiaocui Yang, Han Zhao, Daling Wang, Yifei Zhang
0
0
In the realm of time series forecasting (TSF), it is imperative for models to adeptly discern and distill hidden patterns within historical time series data to forecast future states. Transformer-based models exhibit formidable efficacy in TSF, primarily attributed to their advantage in apprehending these patterns. However, the quadratic complexity of the Transformer leads to low computational efficiency and high costs, which somewhat hinders the deployment of the TSF model in real-world scenarios. Recently, Mamba, a selective state space model, has gained traction due to its ability to process dependencies in sequences while maintaining near-linear complexity. For TSF tasks, these characteristics enable Mamba to comprehend hidden patterns as the Transformer and reduce computational overhead compared to the Transformer. Therefore, we propose a Mamba-based model named Simple-Mamba (S-Mamba) for TSF. Specifically, we tokenize the time points of each variate autonomously via a linear layer. A bidirectional Mamba layer is utilized to extract inter-variate correlations and a Feed-Forward Network is set to learn temporal dependencies. Finally, the generation of forecast outcomes through a linear mapping layer. Experiments on thirteen public datasets prove that S-Mamba maintains low computational overhead and achieves leading performance. Furthermore, we conduct extensive experiments to explore Mamba's potential in TSF tasks. Our code is available at https://github.com/wzhwzhwzh0921/S-D-Mamba.
4/30/2024
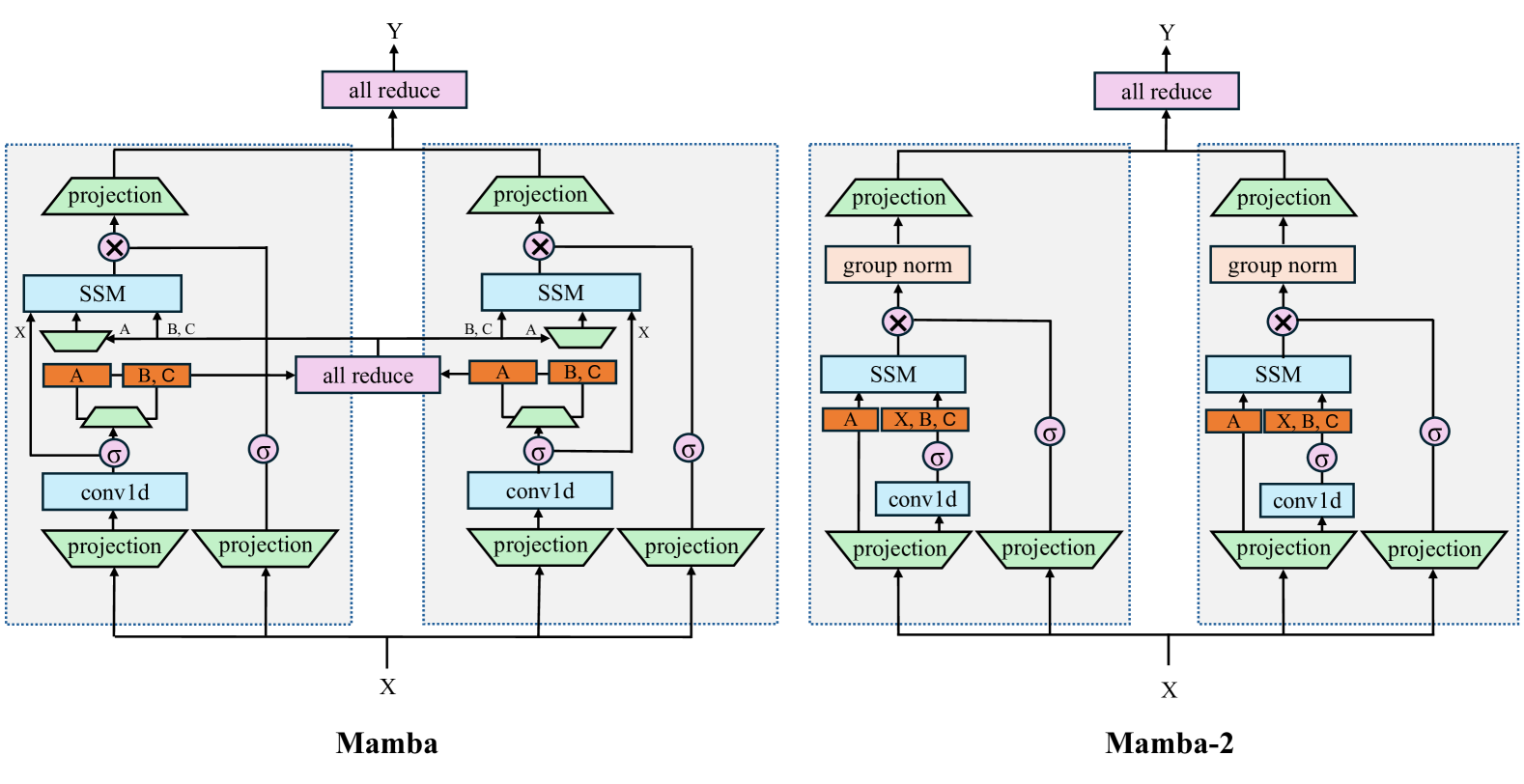
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan Catanzaro
0
0
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
6/13/2024