Dual-Space Knowledge Distillation for Large Language Models

0
Sign in to get full access
Overview
- Dual-Space Knowledge Distillation for Large Language Models is a research paper that explores methods for efficiently training smaller language models by leveraging the knowledge of larger, more powerful models.
- The key ideas are:
- Distilling knowledge from a large language model (teacher) to a smaller model (student) in two parallel spaces - the token probability space and the contextual embedding space.
- Using a novel loss function that combines these two distillation objectives to guide the student model's training.
- Demonstrating the effectiveness of this technique on several language tasks, including text classification, question answering, and natural language inference.
Plain English Explanation
Dual-Space Knowledge Distillation for Large Language Models is a research paper that explores ways to efficiently train smaller language models by tapping into the knowledge of larger, more powerful models. The key idea is to distill, or transfer, knowledge from a large "teacher" model to a smaller "student" model in two parallel spaces - the space of token probabilities and the space of contextual word embeddings.
The researchers developed a novel loss function that combines these two distillation objectives to guide the training of the student model. This allows the student model to learn not just the final output predictions of the teacher, but also the underlying representations and understanding that the teacher has developed.
The researchers then demonstrated the effectiveness of this dual-space distillation technique on several language tasks, such as text classification, question answering, and natural language inference. They showed that the student models trained in this way could achieve performance close to that of the larger teacher models, while being much smaller and more efficient to deploy.
Technical Explanation
Dual-Space Knowledge Distillation for Large Language Models explores a novel approach to knowledge distillation for training smaller language models. The key innovation is to distill knowledge from a large "teacher" model to a smaller "student" model in two parallel spaces: the token probability space and the contextual embedding space.
In the token probability space, the student model is trained to match the output probability distribution of the teacher model for each token in the input sequence. This helps the student learn the teacher's overall understanding of language and task-specific knowledge.
In the contextual embedding space, the student model is trained to match the intermediate contextual representations learned by the teacher model. This allows the student to acquire the rich linguistic and semantic understanding developed by the teacher.
The researchers combine these two distillation objectives into a novel loss function that guides the training of the student model. This dual-space distillation approach enables the student to learn not just the final outputs of the teacher, but also the underlying knowledge representations.
The researchers evaluate this technique on a range of language tasks, including text classification, question answering, and natural language inference. They show that student models trained with dual-space distillation can achieve performance close to that of the larger teacher models, while being much smaller and more efficient.
Critical Analysis
The Dual-Space Knowledge Distillation for Large Language Models paper presents a compelling approach to training smaller language models by leveraging the knowledge of larger models. The key strengths of the research are:
- The dual-space distillation technique, which allows the student model to learn both the output predictions and the internal representations of the teacher, is a novel and promising approach.
- The empirical results demonstrate the effectiveness of this method, with student models achieving strong performance on a variety of language tasks.
- The efficiency gains of the student models, in terms of size and inference speed, are an important practical benefit for deploying language models in resource-constrained environments.
However, the paper also has some limitations:
- The experiments are primarily focused on standard benchmarks and may not fully capture the real-world challenges of deploying language models in diverse, dynamic environments.
- The analysis of the learned representations and knowledge transfer mechanisms could be expanded to provide deeper insights into how the dual-space distillation works.
- The paper does not extensively compare the dual-space approach to other distillation techniques, which would help situate the contributions more clearly.
Overall, the Dual-Space Knowledge Distillation for Large Language Models paper presents an innovative and promising approach to efficient language model training. Further research exploring the boundaries and limitations of this technique, as well as comparisons to other state-of-the-art methods, would be valuable for advancing the field of knowledge distillation for large language models.
Conclusion
Dual-Space Knowledge Distillation for Large Language Models introduces a novel approach to training smaller language models by efficiently distilling knowledge from larger, more powerful teacher models. The key innovation is to perform this distillation in two parallel spaces - the token probability space and the contextual embedding space - and combine these objectives into a unified loss function.
The empirical results demonstrate the effectiveness of this dual-space distillation technique, with student models achieving strong performance on a range of language tasks while being much smaller and more efficient than the teacher models. This has important practical implications for deploying language models in resource-constrained environments, such as on-device or edge computing applications.
The paper represents an exciting advancement in the field of knowledge distillation for large language models, and the ideas presented could inspire further research into more efficient and capable model architectures. As language models continue to grow in scale and complexity, techniques like dual-space distillation will become increasingly important for making these powerful tools accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual-Space Knowledge Distillation for Large Language Models
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, Jinan Xu
Knowledge distillation (KD) is known as a promising solution to compress large language models (LLMs) via transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the two models so that more knowledge can be transferred. However, in the current white-box KD framework, the output distributions are from the respective output spaces of the two models, using their own prediction heads. We argue that the space discrepancy will lead to low similarity between the teacher model and the student model on both representation and distribution levels. Furthermore, this discrepancy also hinders the KD process between models with different vocabularies, which is common for current LLMs. To address these issues, we propose a dual-space knowledge distillation (DSKD) framework that unifies the output spaces of the two models for KD. On the basis of DSKD, we further develop a cross-model attention mechanism, which can automatically align the representations of the two models with different vocabularies. Thus, our framework is not only compatible with various distance functions for KD (e.g., KL divergence) like the current framework, but also supports KD between any two LLMs regardless of their vocabularies. Experiments on task-agnostic instruction-following benchmarks show that DSKD significantly outperforms the current white-box KD framework with various distance functions, and also surpasses existing KD methods for LLMs with different vocabularies.
Read more8/14/2024

0
New!Enhancing Knowledge Distillation of Large Language Models through Efficient Multi-Modal Distribution Alignment
Tianyu Peng, Jiajun Zhang
Knowledge distillation (KD) is an effective model compression method that can transfer the internal capabilities of large language models (LLMs) to smaller ones. However, the multi-modal probability distribution predicted by teacher LLMs causes difficulties for student models to learn. In this paper, we first demonstrate the importance of multi-modal distribution alignment with experiments and then highlight the inefficiency of existing KD approaches in learning multi-modal distributions. To address this problem, we propose Ranking Loss based Knowledge Distillation (RLKD), which encourages the consistency of the ranking of peak predictions between the teacher and student models. By incorporating word-level ranking loss, we ensure excellent compatibility with existing distillation objectives while fully leveraging the fine-grained information between different categories in peaks of two predicted distribution. Experimental results demonstrate that our method enables the student model to better learn the multi-modal distributions of the teacher model, leading to a significant performance improvement in various downstream tasks.
Read more9/20/2024

0
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
Read more4/11/2024
0
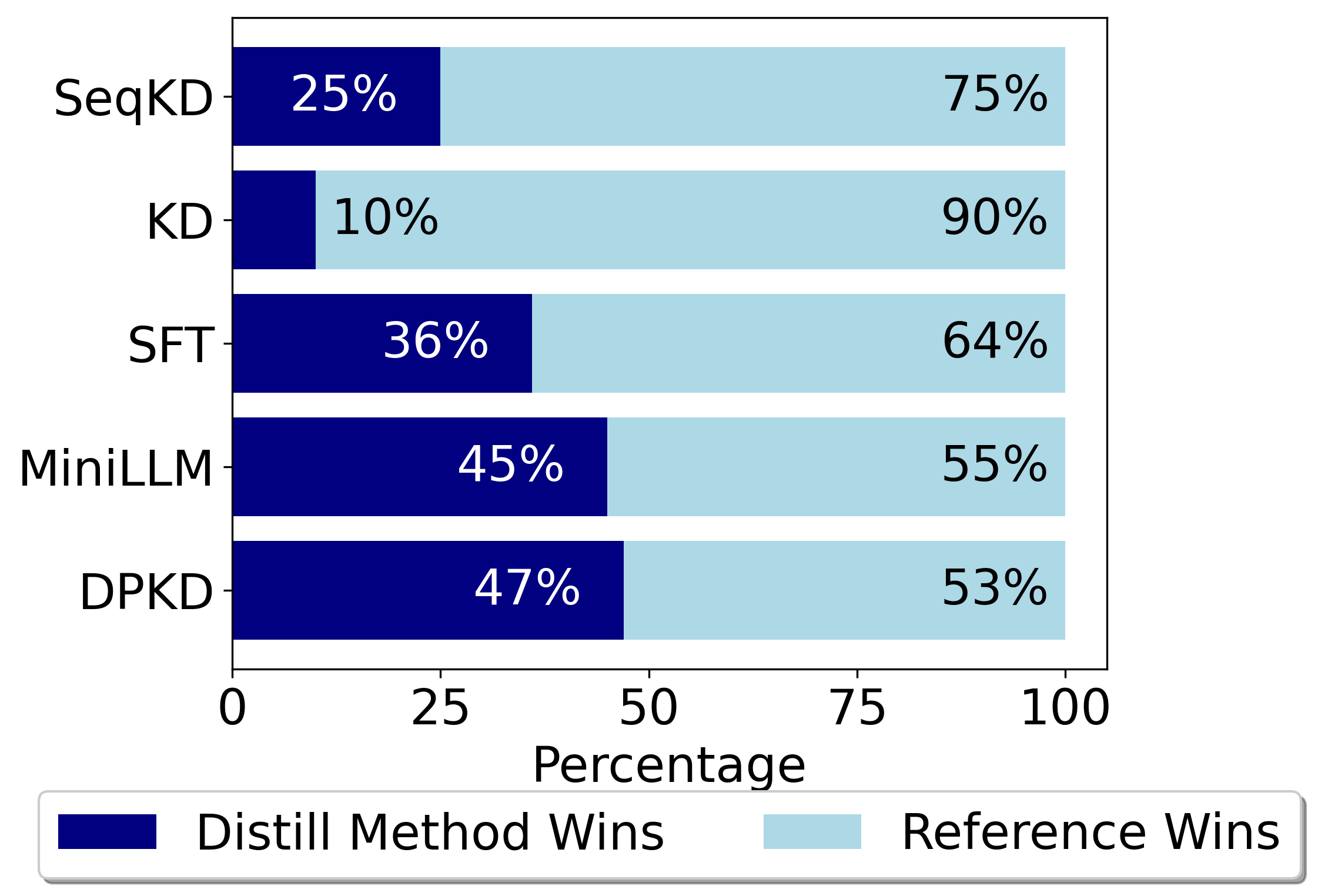
Direct Preference Knowledge Distillation for Large Language Models
Yixing Li, Yuxian Gu, Li Dong, Dequan Wang, Yu Cheng, Furu Wei
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
Read more7/1/2024