Dynamic Deep Learning Based Super-Resolution For The Shallow Water Equations

0
🤿
Sign in to get full access
Overview
- This paper demonstrates that a simulation with the ICON-O ocean model at a 20km resolution can achieve discretization errors similar to a 10km resolution simulation, by frequently correcting the coarse mesh with a U-net-type neural network.
- The neural network, originally developed for image-based super-resolution in post-processing, is trained to compute the difference between solutions on the 20km and 10km meshes, and is used to correct the coarse mesh every 12 hours.
- The setup is the Galewsky test case, which models the transition of a barotropic instability into turbulent flow.
- The ML-corrected coarse resolution run correctly maintains a balance flow and captures the transition to turbulence, with the L2-error being similar to the higher resolution simulation after 8 days.
Plain English Explanation
The paper presents a way to improve the accuracy of ocean simulations without having to use a very fine computer mesh, which would be computationally expensive. Instead, they use a U-net-type neural network to continuously correct a coarser 20km mesh simulation, making it as accurate as a 10km mesh simulation.
The neural network was trained to learn the difference between the solutions on the 20km and 10km meshes. It then uses this knowledge to "fix" the coarser 20km simulation every 12 hours, keeping it on track and matching the higher resolution version.
They tested this approach on a standard ocean modeling problem called the Galewsky test case, which involves modeling the transition from a smooth flow to a more turbulent, chaotic flow. The ML-corrected coarse resolution run was able to accurately capture this transition, performing as well as the higher resolution simulation after 8 days of simulation time.
This is a promising approach to improve the resolution of fluid simulations without having to dramatically increase the computational cost. It could be useful for a variety of ocean and atmospheric modeling applications where high resolution is needed but computational resources are limited.
Technical Explanation
The paper uses the nonlinear shallow water equations as a benchmark to demonstrate the effectiveness of their approach. They simulate the Galewsky test case, which models the transition of a barotropic instability into turbulent flow, using the ICON-O ocean model.
They compare a 20km resolution simulation to a 10km resolution simulation, which serves as the reference. To improve the coarse 20km simulation, they train a U-net-type neural network to learn the difference between the solutions on the two meshes. This network is then used to correct the coarse 20km mesh every 12 hours, effectively "boosting" its resolution.
The results show that the ML-corrected coarse resolution run is able to maintain the correct balance flow and capture the transition to turbulence, matching the higher resolution simulation. After 8 days of simulation, the L2-error of the corrected run is similar to the higher resolution simulation.
While the corrected runs conserve mass, the authors note that they observe some spurious generation of kinetic energy, which is an area for further investigation.
Critical Analysis
The paper presents a promising approach to enhancing the resolution of fluid simulations without requiring a prohibitive increase in computational cost. By leveraging a neural network to correct a coarser simulation, the authors are able to achieve accuracy comparable to a much finer mesh.
One potential limitation is the reliance on the neural network being able to accurately learn the difference between the coarse and fine mesh solutions. The authors do not provide a detailed analysis of the network's performance or its sensitivity to factors like the training data or hyperparameter choices.
Additionally, the observation of spurious kinetic energy generation in the corrected runs is an important issue that warrants further investigation. It's possible that the network is introducing numerical artifacts or failing to fully capture the underlying physics, which could limit the reliability of the approach in certain scenarios.
Overall, the research is a valuable contribution to the field of high-resolution fluid simulation, demonstrating the potential of machine learning techniques to enhance the performance of traditional numerical methods. However, further work is needed to fully understand the strengths, limitations, and broader applicability of this approach.
Conclusion
This paper presents a novel approach to improving the resolution of ocean simulations using a U-net-type neural network to correct a coarse 20km mesh simulation. By learning the difference between the coarse and fine mesh solutions, the network is able to "boost" the accuracy of the coarse simulation, achieving discretization errors comparable to a 10km resolution run.
The results on the Galewsky test case are promising, showing that the ML-corrected coarse resolution run can correctly capture the transition to turbulent flow. This technique could be valuable for a range of ocean and atmospheric modeling applications where high resolution is needed but computational resources are limited.
While the paper highlights some potential issues, such as the generation of spurious kinetic energy, the overall approach demonstrates the power of combining numerical simulations with machine learning to enhance the performance of scientific computing. As the field of scientific machine learning continues to advance, techniques like the one presented in this paper may become increasingly important tools for tackling complex scientific challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Dynamic Deep Learning Based Super-Resolution For The Shallow Water Equations
Maximilian Witte, Fabricio Rodrigues Lapolli, Philip Freese, Sebastian Gotschel, Daniel Ruprecht, Peter Korn, Christopher Kadow
Using the nonlinear shallow water equations as benchmark, we demonstrate that a simulation with the ICON-O ocean model with a 20km resolution that is frequently corrected by a U-net-type neural network can achieve discretization errors of a simulation with 10km resolution. The network, originally developed for image-based super-resolution in post-processing, is trained to compute the difference between solutions on both meshes and is used to correct the coarse mesh every 12h. Our setup is the Galewsky test case, modeling transition of a barotropic instability into turbulent flow. We show that the ML-corrected coarse resolution run correctly maintains a balance flow and captures the transition to turbulence in line with the higher resolution simulation. After 8 day of simulation, the $L_2$-error of the corrected run is similar to a simulation run on the finer mesh. While mass is conserved in the corrected runs, we observe some spurious generation of kinetic energy.
Read more4/10/2024
0
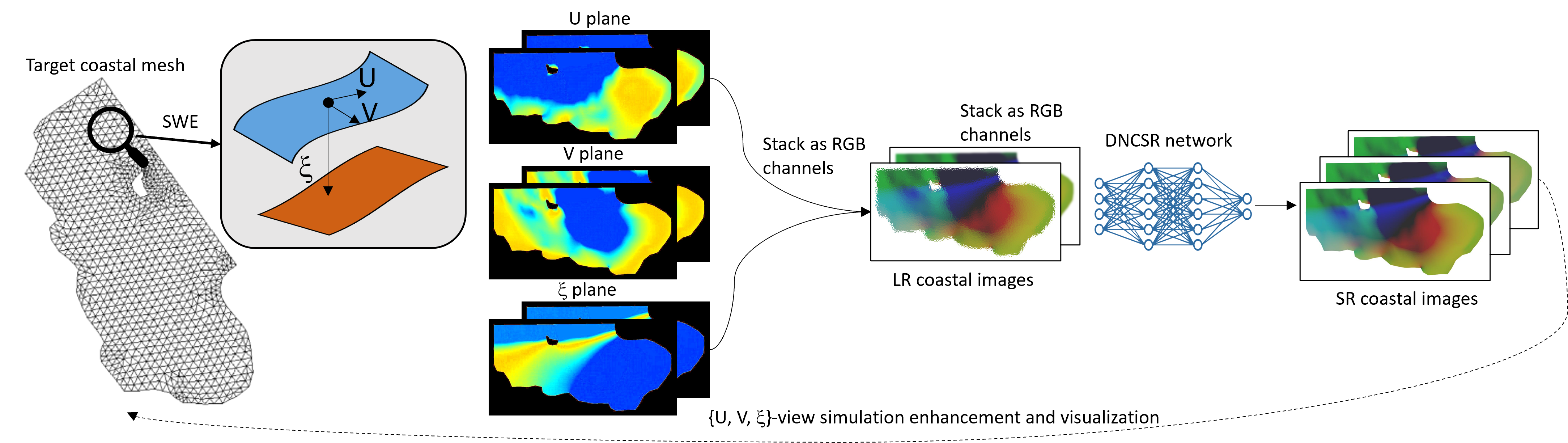
Super-Resolution works for coastal simulations
Zhi-Song Liu, Markus Buttner, Vadym Aizinger, Andreas Rupp
Learning fine-scale details of a coastal ocean simulation from a coarse representation is a challenging task. For real-world applications, high-resolution simulations are necessary to advance understanding of many coastal processes, specifically, to predict flooding resulting from tsunamis and storm surges. We propose a Deep Network for Coastal Super-Resolution (DNCSR) for spatiotemporal enhancement to efficiently learn the high-resolution numerical solution. Given images of coastal simulations produced on low-resolution computational meshes using low polynomial order discontinuous Galerkin discretizations and a coarse temporal resolution, the proposed DNCSR learns to produce high-resolution free surface elevation and velocity visualizations in both time and space. To efficiently model the dynamic changes over time and space, we propose grid-aware spatiotemporal attention to project the temporal features to the spatial domain for non-local feature matching. The coordinate information is also utilized via positional encoding. For the final reconstruction, we use the spatiotemporal bilinear operation to interpolate the missing frames and then expand the feature maps to the frequency domain for residual mapping. Besides data-driven losses, the proposed physics-informed loss guarantees gradient consistency and momentum changes. Their combination contributes to the overall 24% improvements in RMSE. To train the proposed model, we propose a large-scale coastal simulation dataset and use it for model optimization and evaluation. Our method shows superior super-resolution quality and fast computation compared to the state-of-the-art methods.
Read more8/30/2024

0
Mesh-based Super-Resolution of Fluid Flows with Multiscale Graph Neural Networks
Shivam Barwey, Pinaki Pal, Saumil Patel, Riccardo Balin, Bethany Lusch, Venkatram Vishwanath, Romit Maulik, Ramesh Balakrishnan
A graph neural network (GNN) approach is introduced in this work which enables mesh-based three-dimensional super-resolution of fluid flows. In this framework, the GNN is designed to operate not on the full mesh-based field at once, but on localized meshes of elements (or cells) directly. To facilitate mesh-based GNN representations in a manner similar to spectral (or finite) element discretizations, a baseline GNN layer (termed a message passing layer, which updates local node properties) is modified to account for synchronization of coincident graph nodes, rendering compatibility with commonly used element-based mesh connectivities. The architecture is multiscale in nature, and is comprised of a combination of coarse-scale and fine-scale message passing layer sequences (termed processors) separated by a graph unpooling layer. The coarse-scale processor embeds a query element (alongside a set number of neighboring coarse elements) into a single latent graph representation using coarse-scale synchronized message passing over the element neighborhood, and the fine-scale processor leverages additional message passing operations on this latent graph to correct for interpolation errors. Demonstration studies are performed using hexahedral mesh-based data from Taylor-Green Vortex flow simulations at Reynolds numbers of 1600 and 3200. Through analysis of both global and local errors, the results ultimately show how the GNN is able to produce accurate super-resolved fields compared to targets in both coarse-scale and multiscale model configurations.
Read more9/19/2024
🤿
0
Reducing Spatial Discretization Error on Coarse CFD Simulations Using an OpenFOAM-Embedded Deep Learning Framework
Jesus Gonzalez-Sieiro, David Pardo, Vincenzo Nava, Victor M. Calo, Markus Towara
We propose a method for reducing the spatial discretization error of coarse computational fluid dynamics (CFD) problems by enhancing the quality of low-resolution simulations using deep learning. We feed the model with fine-grid data after projecting it to the coarse-grid discretization. We substitute the default differencing scheme for the convection term by a feed-forward neural network that interpolates velocities from cell centers to face values to produce velocities that approximate the down-sampled fine-grid data well. The deep learning framework incorporates the open-source CFD code OpenFOAM, resulting in an end-to-end differentiable model. We automatically differentiate the CFD physics using a discrete adjoint code version. We present a fast communication method between TensorFlow (Python) and OpenFOAM (c++) that accelerates the training process. We applied the model to the flow past a square cylinder problem, reducing the error from 120% to 25% in the velocity for simulations inside the training distribution compared to the traditional solver using an x8 coarser mesh. For simulations outside the training distribution, the error reduction in the velocities was about 50%. The training is affordable in terms of time and data samples since the architecture exploits the local features of the physics.
Read more9/6/2024