Dynamic Diffusion Transformer

0
Sign in to get full access
Overview
- This paper introduces the Dynamic Diffusion Transformer, a novel machine learning model for image generation.
- The model combines the strengths of diffusion models and transformers to achieve efficient and high-quality image synthesis.
- The key innovations include a dynamic self-attention mechanism and a multi-scale diffusion process.
Plain English Explanation
The Dynamic Diffusion Transformer is a new type of AI model that can generate high-quality images from scratch. It works by blending two powerful machine learning techniques: diffusion models and transformers.
Diffusion models are great at generating realistic-looking images, but they can be slow and computationally intensive. Transformers, on the other hand, are very efficient at processing information, but they've historically struggled with image generation.
The Dynamic Diffusion Transformer takes the best of both worlds. It uses a "dynamic self-attention" mechanism that allows the model to efficiently focus on the most relevant parts of the image as it's being generated. And it uses a "multi-scale diffusion process" that generates the image at different resolutions, making the overall process faster and more efficient.
The end result is a model that can generate high-quality images quickly and efficiently, with potential applications in areas like computer vision, creative AI, and image-based user interfaces.
Technical Explanation
The key innovations of the Dynamic Diffusion Transformer include:
-
Dynamic Self-Attention Mechanism: Instead of using a fixed self-attention mechanism, the model employs a "dynamic" version that adapts the attention patterns based on the current state of the diffusion process. This allows the model to focus on the most relevant parts of the image as it's being generated.
-
Multi-Scale Diffusion Process: The model uses a multi-scale diffusion process, where the image is generated at different resolutions simultaneously. This enables faster generation and better preservation of high-frequency details compared to standard diffusion models.
-
Efficient Transformer Encoder-Decoder Architecture: The model uses a transformer-based encoder-decoder architecture, leveraging the efficiency and flexibility of transformers for image generation. The encoder processes the input noise, while the decoder generates the output image.
The authors extensively evaluate the Dynamic Diffusion Transformer on various image generation benchmarks, including CIFAR-10, ImageNet, and CelebA-HQ. The results demonstrate that the model outperforms state-of-the-art diffusion and GAN-based approaches in terms of both image quality and generation speed.
Critical Analysis
The authors acknowledge several limitations and potential areas for further research:
- The model's performance may degrade on highly diverse or complex datasets, as the dynamic self-attention mechanism may struggle to capture the necessary global and local interactions.
- The multi-scale diffusion process, while efficient, may not be as effective at preserving fine-grained details as other approaches, such as U-DITs.
- The authors suggest exploring alternative transformer architectures and incorporating additional inductive biases to further improve the model's performance and generalization capabilities.
Additionally, while the Dynamic Diffusion Transformer shows promising results, it is important to consider potential ethical implications and biases that may arise from the model's training data and generation process. Responsible development and deployment of such AI systems should be a priority.
Conclusion
The Dynamic Diffusion Transformer represents a significant advancement in the field of generative AI, combining the strengths of diffusion models and transformers to achieve efficient and high-quality image synthesis. The novel dynamic self-attention mechanism and multi-scale diffusion process demonstrate the potential of this approach and open up new avenues for further research and applications in areas like computer vision, creative AI, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic Diffusion Transformer
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Yibing Song, Gao Huang, Fan Wang, Yang You
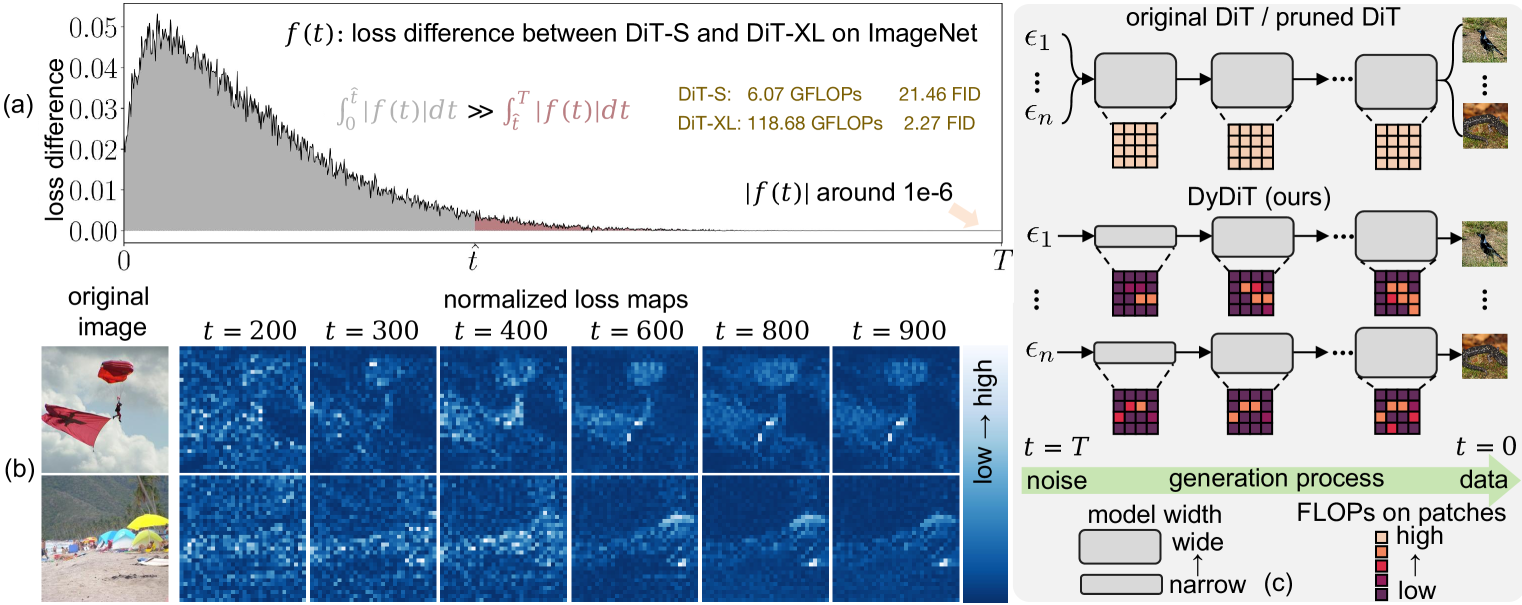
Diffusion Transformer (DiT), an emerging diffusion model for image generation, has demonstrated superior performance but suffers from substantial computational costs. Our investigations reveal that these costs stem from the static inference paradigm, which inevitably introduces redundant computation in certain diffusion timesteps and spatial regions. To address this inefficiency, we propose Dynamic Diffusion Transformer (DyDiT), an architecture that dynamically adjusts its computation along both timestep and spatial dimensions during generation. Specifically, we introduce a Timestep-wise Dynamic Width (TDW) approach that adapts model width conditioned on the generation timesteps. In addition, we design a Spatial-wise Dynamic Token (SDT) strategy to avoid redundant computation at unnecessary spatial locations. Extensive experiments on various datasets and different-sized models verify the superiority of DyDiT. Notably, with <3% additional fine-tuning iterations, our method reduces the FLOPs of DiT-XL by 51%, accelerates generation by 1.73, and achieves a competitive FID score of 2.07 on ImageNet. The code is publicly available at https://github.com/NUS-HPC-AI-Lab/ Dynamic-Diffusion-Transformer.
Read more10/10/2024
⛏️
0
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
Read more5/24/2024

0
$Delta$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, Tao Chen
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$alpha$ and DiT-XL demonstrate that the $Delta$-DiT can achieve a $1.6times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
Read more6/4/2024
👀
0
DiffiT: Diffusion Vision Transformers for Image Generation
Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, Arash Vahdat
Diffusion models with their powerful expressivity and high sample quality have achieved State-Of-The-Art (SOTA) performance in the generative domain. The pioneering Vision Transformer (ViT) has also demonstrated strong modeling capabilities and scalability, especially for recognition tasks. In this paper, we study the effectiveness of ViTs in diffusion-based generative learning and propose a new model denoted as Diffusion Vision Transformers (DiffiT). Specifically, we propose a methodology for finegrained control of the denoising process and introduce the Time-dependant Multihead Self Attention (TMSA) mechanism. DiffiT is surprisingly effective in generating high-fidelity images with significantly better parameter efficiency. We also propose latent and image space DiffiT models and show SOTA performance on a variety of class-conditional and unconditional synthesis tasks at different resolutions. The Latent DiffiT model achieves a new SOTA FID score of 1.73 on ImageNet256 dataset while having 19.85%, 16.88% less parameters than other Transformer-based diffusion models such as MDT and DiT,respectively. Code: https://github.com/NVlabs/DiffiT
Read more8/30/2024