Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement

0

Sign in to get full access
Overview
- Efficient speech enhancement using a Dynamic Gated Recurrent Neural Network (DG-RNN)
- Reduces computational cost compared to traditional speech enhancement models
- Dynamically adjusts model complexity based on input complexity
Plain English Explanation
The paper presents a novel Dynamic Gated Recurrent Neural Network (DG-RNN) for efficient speech enhancement. Speech enhancement is the process of improving the quality of speech signals by removing noise and distortions.
Traditional speech enhancement models often have high computational requirements, which can be a challenge for deployment on resource-constrained devices like smartphones or IoT sensors. The key idea behind the DG-RNN is to dynamically adjust the model's complexity based on the complexity of the input speech signal. This helps to reduce the overall computational cost while maintaining high speech enhancement performance.
The DG-RNN architecture uses a gating mechanism to selectively activate different parts of the neural network based on the input signal. When the input is simple (e.g., low noise), the model uses a smaller, more efficient configuration. When the input is more complex (e.g., high noise), the model dynamically expands to a larger, more capable configuration to handle the increased complexity.
This adaptive approach allows the DG-RNN to achieve high-quality speech enhancement while using fewer computational resources compared to traditional static models. This makes it well-suited for deployment on devices with limited computing power, such as edge devices or mobile phones.
Technical Explanation
The Dynamic Gated Recurrent Neural Network (DG-RNN) consists of a gating mechanism that dynamically adjusts the model's complexity based on the input speech signal. The gating mechanism selects which parts of the neural network to activate, allowing the model to use fewer computational resources when the input is simple and expand to a larger configuration when the input is more complex.
The DG-RNN architecture includes a feature extraction module, a dynamic gating module, and a speech enhancement module. The feature extraction module converts the input speech signal into a sequence of feature representations. The dynamic gating module then determines the appropriate model configuration based on the input features, and the speech enhancement module performs the actual noise removal and signal reconstruction.
The authors conducted experiments to evaluate the DG-RNN's performance on speech enhancement tasks. The results show that the DG-RNN achieves comparable or better speech enhancement quality compared to traditional models while using significantly fewer computational resources, making it a promising approach for deploying speech enhancement on resource-constrained devices.
Critical Analysis
The paper provides a novel and promising approach to address the computational efficiency challenge in speech enhancement. The dynamic gating mechanism is an interesting solution that allows the model to adapt its complexity to the input signal, which can lead to significant computational savings.
However, the paper does not provide a detailed analysis of the tradeoffs between the computational savings and the potential impact on speech enhancement quality. It would be useful to understand the specific scenarios where the DG-RNN excels or falls short compared to traditional models, and the factors that influence these performance differences.
Additionally, the paper could have explored the generalization of the DG-RNN to other audio processing tasks beyond speech enhancement, as the dynamic gating mechanism may be applicable in a wider range of scenarios.
Conclusion
The Dynamic Gated Recurrent Neural Network (DG-RNN) presented in this paper offers a promising approach to improving the computational efficiency of speech enhancement without sacrificing performance. The dynamic gating mechanism allows the model to adapt its complexity to the input signal, resulting in significant computational savings while maintaining high-quality speech enhancement.
This research has the potential to enable deployment of speech enhancement on resource-constrained devices, such as smartphones or IoT sensors, opening up new opportunities for improved audio quality in a wide range of applications. Further exploration of the DG-RNN's generalization, as well as a deeper understanding of the tradeoffs between computational efficiency and speech enhancement quality, could lead to even more impactful advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement
Longbiao Cheng, Ashutosh Pandey, Buye Xu, Tobi Delbruck, Shih-Chii Liu
This paper introduces a new Dynamic Gated Recurrent Neural Network (DG-RNN) for compute-efficient speech enhancement models running on resource-constrained hardware platforms. It leverages the slow evolution characteristic of RNN hidden states over steps, and updates only a selected set of neurons at each step by adding a newly proposed select gate to the RNN model. This select gate allows the computation cost of the conventional RNN to be reduced during network inference. As a realization of the DG-RNN, we further propose the Dynamic Gated Recurrent Unit (D-GRU) which does not require additional parameters. Test results obtained from several state-of-the-art compute-efficient RNN-based speech enhancement architectures using the DNS challenge dataset, show that the D-GRU based model variants maintain similar speech intelligibility and quality metrics comparable to the baseline GRU based models even with an average 50% reduction in GRU computes.
Read more8/23/2024

0
Dynamic Spiking Graph Neural Networks
Nan Yin, Mengzhu Wang, Zhenghan Chen, Giulia De Masi, Bin Gu, Huan Xiong
The integration of Spiking Neural Networks (SNNs) and Graph Neural Networks (GNNs) is gradually attracting attention due to the low power consumption and high efficiency in processing the non-Euclidean data represented by graphs. However, as a common problem, dynamic graph representation learning faces challenges such as high complexity and large memory overheads. Current work often uses SNNs instead of Recurrent Neural Networks (RNNs) by using binary features instead of continuous ones for efficient training, which would overlooks graph structure information and leads to the loss of details during propagation. Additionally, optimizing dynamic spiking models typically requires propagation of information across time steps, which increases memory requirements. To address these challenges, we present a framework named underline{Dy}namic underline{S}punderline{i}king underline{G}raph underline{N}eural Networks (method{}). To mitigate the information loss problem, method{} propagates early-layer information directly to the last layer for information compensation. To accommodate the memory requirements, we apply the implicit differentiation on the equilibrium state, which does not rely on the exact reverse of the forward computation. While traditional implicit differentiation methods are usually used for static situations, method{} extends it to the dynamic graph setting. Extensive experiments on three large-scale real-world dynamic graph datasets validate the effectiveness of method{} on dynamic node classification tasks with lower computational costs.
Read more7/31/2024
0
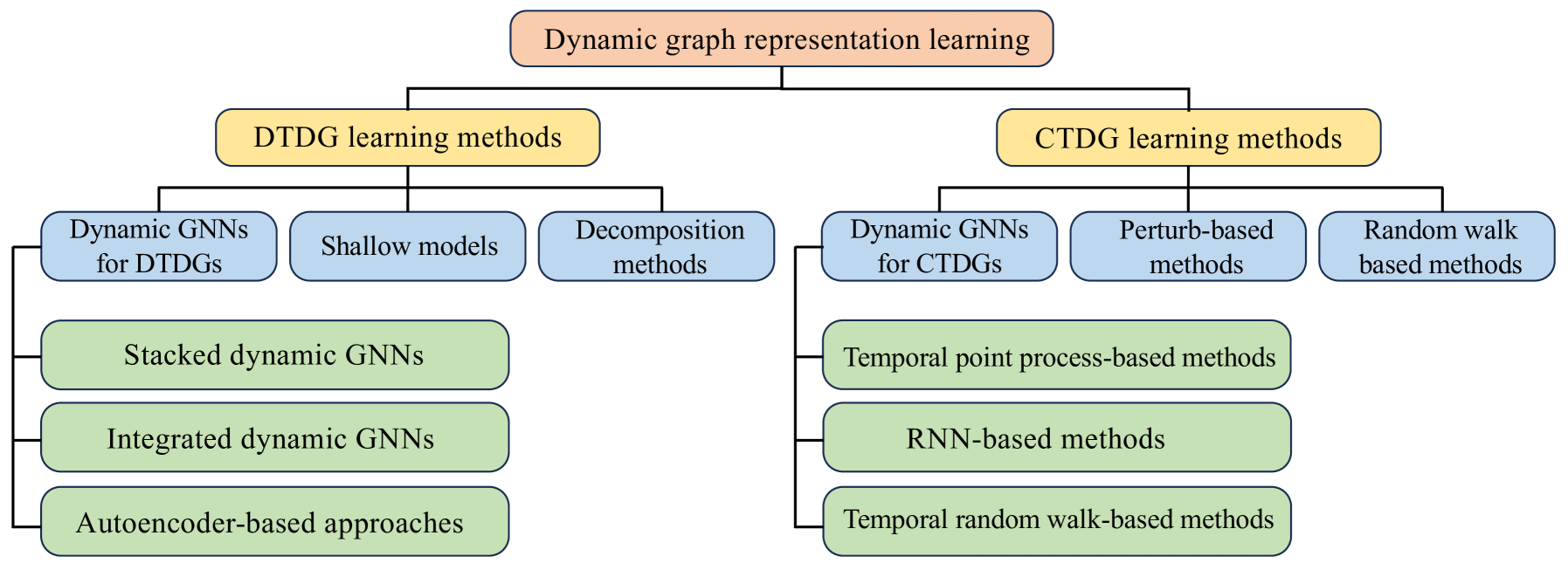
A survey of dynamic graph neural networks
Yanping Zheng, Lu Yi, Zhewei Wei
Graph neural networks (GNNs) have emerged as a powerful tool for effectively mining and learning from graph-structured data, with applications spanning numerous domains. However, most research focuses on static graphs, neglecting the dynamic nature of real-world networks where topologies and attributes evolve over time. By integrating sequence modeling modules into traditional GNN architectures, dynamic GNNs aim to bridge this gap, capturing the inherent temporal dependencies of dynamic graphs for a more authentic depiction of complex networks. This paper provides a comprehensive review of the fundamental concepts, key techniques, and state-of-the-art dynamic GNN models. We present the mainstream dynamic GNN models in detail and categorize models based on how temporal information is incorporated. We also discuss large-scale dynamic GNNs and pre-training techniques. Although dynamic GNNs have shown superior performance, challenges remain in scalability, handling heterogeneous information, and lack of diverse graph datasets. The paper also discusses possible future directions, such as adaptive and memory-enhanced models, inductive learning, and theoretical analysis.
Read more4/30/2024
0
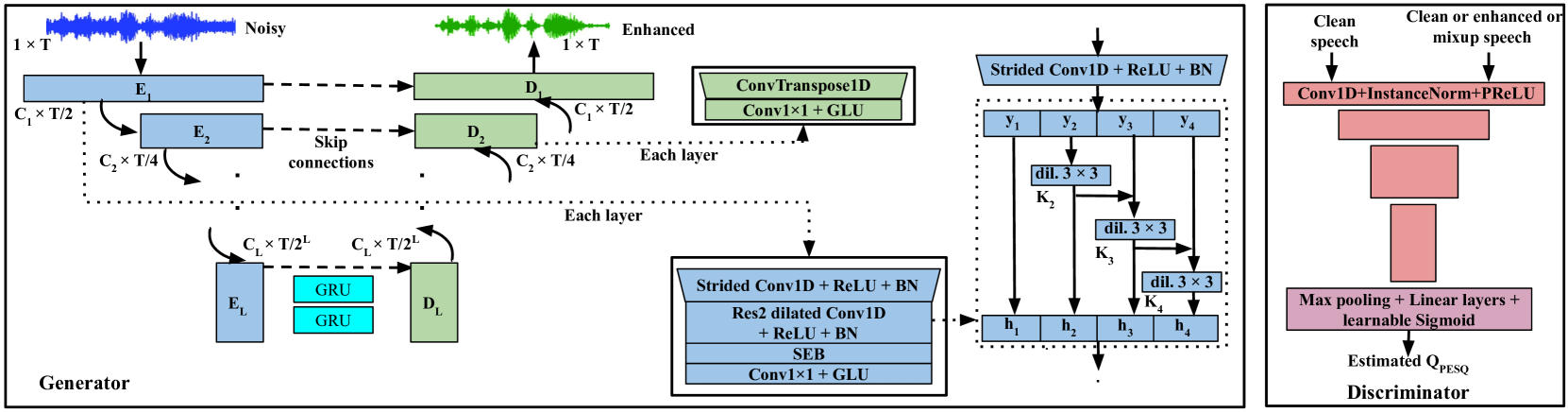
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
Read more5/28/2024