Speech enhancement deep-learning architecture for efficient edge processing
2405.16834
0
0
Abstract
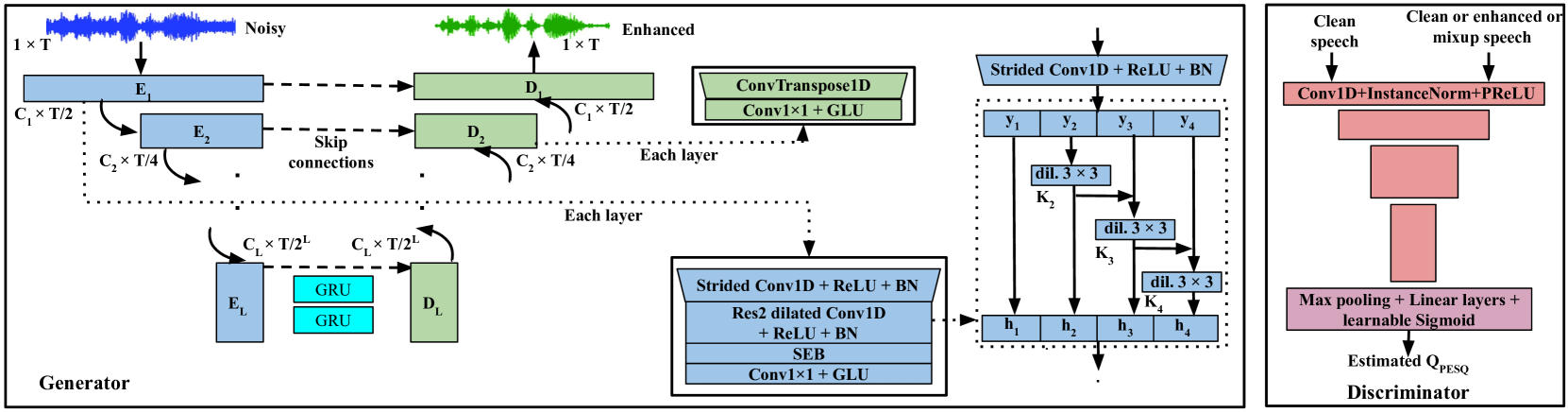
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
Create account to get full access
Overview
- This paper presents a deep learning architecture for efficient speech enhancement on edge devices.
- The proposed approach, called TRNet, leverages a two-stage refinement process to achieve high-quality speech enhancement with low computational cost.
- The architecture is designed to be lightweight and suitable for deployment on resource-constrained edge devices, making it applicable for a wide range of real-world applications.
Plain English Explanation
In this paper, the researchers developed a new deep learning model for enhancing speech quality. The key challenge they wanted to address is making this technology work well on small, low-power devices at the "edge" of a network, rather than requiring powerful cloud-based servers.
The core idea is to use a two-step process to refine the speech signal. First, a lightweight "coarse" model does an initial pass of noise reduction and enhancement. Then, a more complex "fine-tuning" model takes the output of the first step and applies additional processing to further improve the speech quality.
By splitting the task into two stages, the researchers were able to create an overall system that is computationally efficient enough to run on edge devices, while still achieving high-quality speech enhancement. This could enable new applications like real-time voice assistants or noise-cancelling headphones that don't require an internet connection.
The Conformer-based speech recognition for extreme edge computing and Lightweight dual-stage framework for personalized speech enhancement papers explore similar approaches to enable speech processing on resource-constrained devices.
Technical Explanation
The proposed TRNet architecture consists of two main components: a coarse model and a fine-tuning model.
The coarse model is a lightweight neural network designed for efficient inference on edge devices. It takes the noisy input speech signal and applies an initial round of noise reduction and enhancement.
The output of the coarse model is then fed into the fine-tuning model, which is a more complex neural network. This model performs additional processing to further improve the speech quality, leveraging the partial enhancement from the first stage.
The researchers evaluated the TRNet approach on several standard speech enhancement benchmarks and found that it achieved competitive performance compared to larger, more computationally-intensive models, while requiring significantly less memory and computational power.
This efficient design makes TRNet well-suited for deployment on edge devices like smartphones, earbuds, or smart home assistants, where low latency, low power consumption, and small model size are critical requirements.
The CMGAN and EfficientASR papers also explore techniques for building compact, efficient speech processing models for edge applications.
Critical Analysis
The researchers acknowledge several potential limitations and areas for future work:
- The performance of the fine-tuning model is still dependent on the quality of the coarse model's output, so further improvements to the coarse model could lead to better overall results.
- The paper only evaluates the approach on standard speech enhancement benchmarks, and real-world performance may differ, particularly for edge deployment scenarios with diverse acoustic conditions.
- The paper does not provide detailed analysis of the computational and memory footprint of the TRNet architecture, which would be important for assessing its suitability for different edge hardware platforms.
Additionally, it would be valuable to see comparisons to other state-of-the-art lightweight speech enhancement models, such as those mentioned in the related work, to better understand the relative strengths and weaknesses of the TRNet approach.
Overall, the TRNet architecture represents an interesting contribution to the field of efficient speech processing for edge devices, but further research and validation would be needed to fully assess its practical benefits and limitations.
Conclusion
This paper presents a novel deep learning architecture called TRNet that is designed for efficient speech enhancement on resource-constrained edge devices. By using a two-stage refinement process, the researchers were able to achieve high-quality speech output while keeping the computational and memory requirements low enough for deployment on smartphones, earbuds, and other edge hardware.
The key innovation of the TRNet approach is its ability to balance speech enhancement performance and inference efficiency, which could enable a new generation of real-time, low-latency audio processing applications that don't require a constant internet connection. As edge computing continues to advance, techniques like those explored in this paper will become increasingly important for bringing powerful AI capabilities to the devices we use every day.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Wangyou Zhang, Robin Scheibler, Kohei Saijo, Samuele Cornell, Chenda Li, Zhaoheng Ni, Anurag Kumar, Jan Pirklbauer, Marvin Sach, Shinji Watanabe, Tim Fingscheidt, Yanmin Qian
0
0
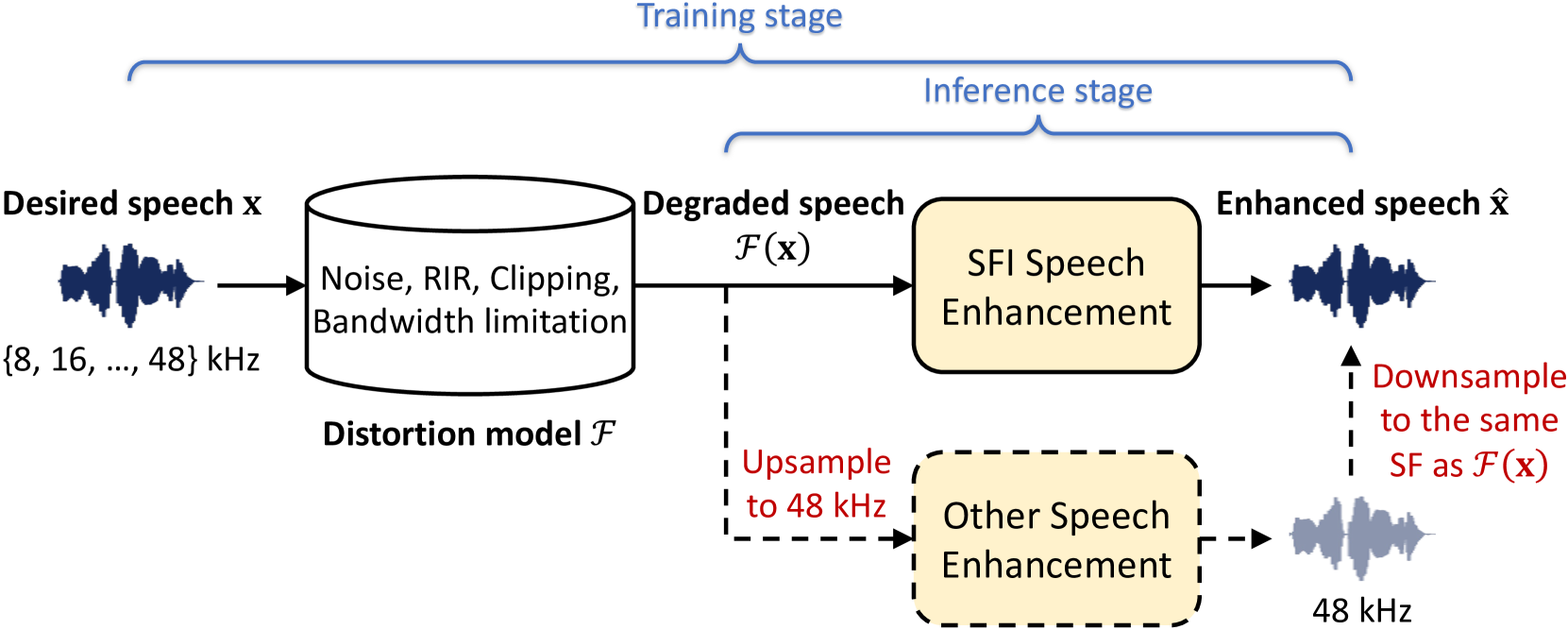
The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
6/10/2024
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
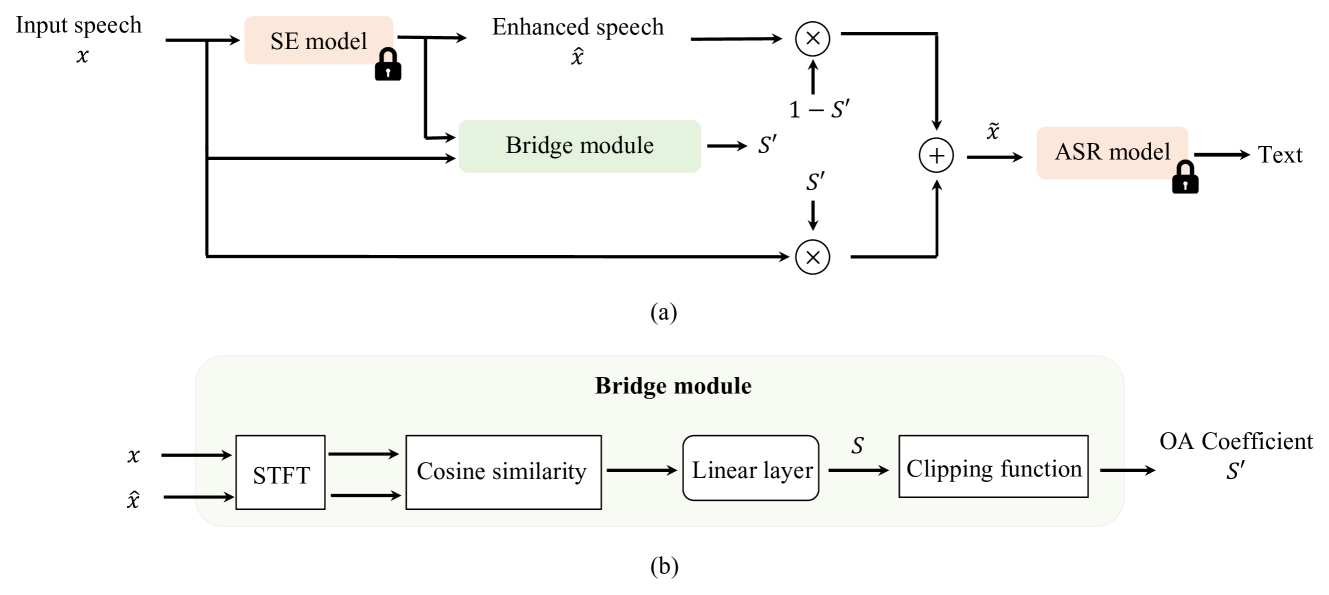
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024

Speech Emotion Recognition Via CNN-Transformer and Multidimensional Attention Mechanism
Xiaoyu Tang, Yixin Lin, Ting Dang, Yuanfang Zhang, Jintao Cheng
0
0
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods.
6/5/2024
🗣️
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Mingbin Xu, Alex Jin, Sicheng Wang, Mu Su, Tim Ng, Henry Mason, Shiyi Han, Zhihong Lei, Yaqiao Deng, Zhen Huang, Mahesh Krishnamoorthy
0
0
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other smart home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on smart wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
5/15/2024