Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models
2404.09732
0
0
Abstract
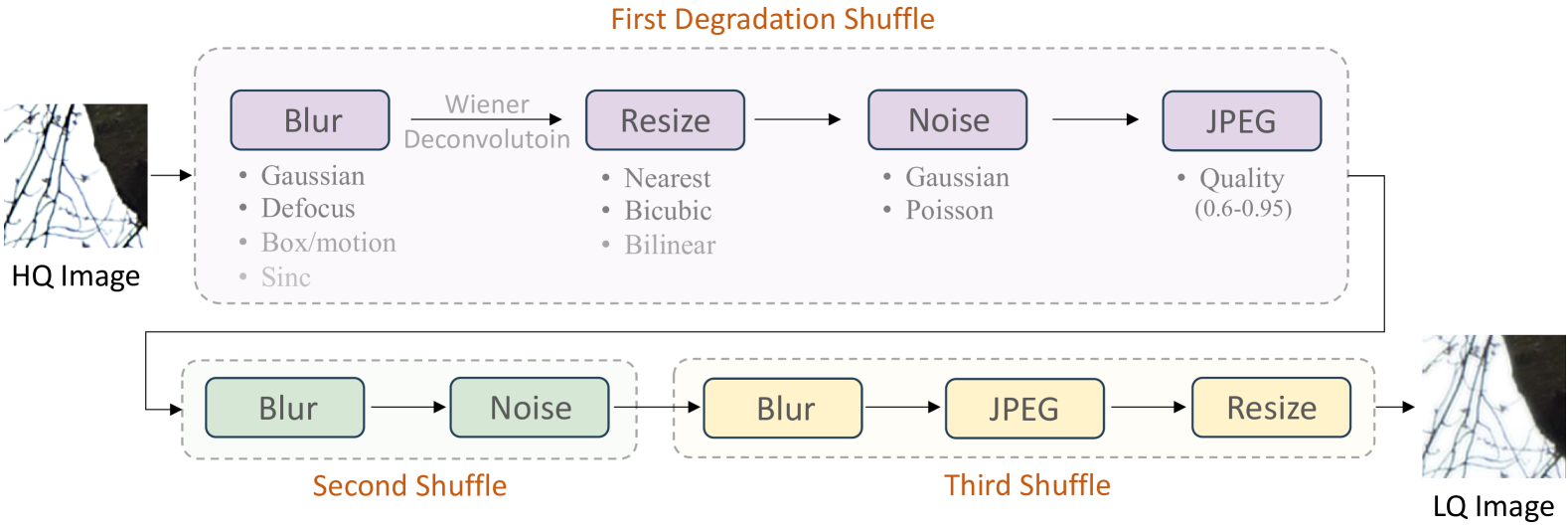
Though diffusion models have been successfully applied to various image restoration (IR) tasks, their performance is sensitive to the choice of training datasets. Typically, diffusion models trained in specific datasets fail to recover images that have out-of-distribution degradations. To address this problem, this work leverages a capable vision-language model and a synthetic degradation pipeline to learn image restoration in the wild (wild IR). More specifically, all low-quality images are simulated with a synthetic degradation pipeline that contains multiple common degradations such as blur, resize, noise, and JPEG compression. Then we introduce robust training for a degradation-aware CLIP model to extract enriched image content features to assist high-quality image restoration. Our base diffusion model is the image restoration SDE (IR-SDE). Built upon it, we further present a posterior sampling strategy for fast noise-free image generation. We evaluate our model on both synthetic and real-world degradation datasets. Moreover, experiments on the unified image restoration task illustrate that the proposed posterior sampling improves image generation quality for various degradations.
Create account to get full access
Overview
- This paper presents a novel approach to photo-realistic image restoration using controlled vision-language models.
- The method leverages the powerful capabilities of large-scale vision-language models to generate high-quality, semantically-consistent restored images from degraded inputs.
- The key innovations include a novel training procedure that enables the model to effectively perform blind restoration tasks and a controlled generation mechanism that allows for fine-tuned restoration results.
Plain English Explanation
The researchers have developed a new way to fix up low-quality or damaged images and make them look like high-quality, realistic photos. They use large AI models that can understand both images and language to achieve this.
Typically, image restoration is a challenging task as it involves undoing various types of degradation, like blurriness or missing parts. The researchers' approach is innovative because it taps into the impressive abilities of vision-language models, which have been trained on massive amounts of image and text data.
The model can understand the semantic content and context of an image, and then generate a new, restored version that looks natural and true-to-life. Importantly, the researchers developed special training methods to enable the model to handle a wide range of restoration tasks, not just specific types of damage.
Additionally, the model allows for fine-tuned control over the restoration process. Users can provide text descriptions or other guidance to shape the final output and get the exact look they want. This level of control is a key advantage over previous image restoration techniques.
Overall, this work demonstrates how powerful AI models can be leveraged to tackle challenging image processing problems in a flexible and high-quality way. The resulting restored images are remarkably realistic and natural-looking.
Technical Explanation
The paper introduces a novel approach for photo-realistic image restoration using controlled vision-language models. The key innovation is the ability to leverage large-scale pretrained vision-language models, such as DALL-E, to effectively perform blind image restoration tasks.
The proposed method consists of two main components:
- A blind restoration module that can handle diverse types of image degradation, trained using a novel loss function and data augmentation techniques.
- A controlled generation mechanism that allows users to provide textual guidance to shape the final restored image, similar to DriftRec.
The blind restoration module is trained using a combination of supervised and unsupervised learning. The supervised component leverages pairs of degraded and ground-truth images, while the unsupervised aspect employs self-supervised techniques to learn general image restoration capabilities.
To enable controlled generation, the model is further fine-tuned using a joint vision-language objective, where the model is trained to generate images that match provided textual descriptions. This allows users to specify desired attributes or semantic properties of the restored image, leading to personalized and visually compelling results.
The researchers evaluate their approach on a range of real-world image restoration benchmarks, demonstrating significant improvements over state-of-the-art methods, particularly in terms of semantic consistency and photo-realism.
Critical Analysis
The paper presents a promising approach to photo-realistic image restoration that leverages the strengths of large vision-language models. The authors have developed innovative training techniques to enable these models to effectively handle diverse restoration tasks, going beyond previous work that focused on specific degradation types.
One potential limitation is the reliance on paired training data, which may not always be available in real-world scenarios. The authors acknowledge this and suggest exploring unsupervised or self-supervised techniques to further improve the model's generalization capabilities.
Additionally, while the controlled generation mechanism is a valuable feature, it would be interesting to see how the model performs in scenarios where users provide more complex or open-ended textual guidance. The current evaluation focuses on relatively simple prompts, and it's unclear how the model would handle more nuanced or ambiguous instructions.
Finally, the paper does not provide a detailed analysis of the computational and memory requirements of the proposed method, which could be an important consideration for practical applications, especially on resource-constrained devices.
Overall, this work represents a significant advancement in the field of image restoration and demonstrates the potential of leveraging large vision-language models for this task. Further research and development in this direction could lead to even more powerful and versatile image restoration tools.
Conclusion
The presented research introduces a novel approach to photo-realistic image restoration that leverages controlled vision-language models. By tapping into the impressive capabilities of large-scale pretrained models, the method can generate high-quality, semantically-consistent restored images from degraded inputs.
The key innovations include a blind restoration module that can handle diverse types of degradation and a controlled generation mechanism that allows users to shape the final output through textual guidance. Evaluation results showcase significant improvements over state-of-the-art methods, particularly in terms of semantic consistency and visual realism.
This work represents an important step forward in the field of image restoration and highlights the potential of combining powerful vision-language models with specialized training techniques to tackle complex image processing challenges. As the research in this area continues to evolve, we can expect to see even more advanced and versatile image restoration tools that can handle a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Using diffusion model as constraint: Empower Image Restoration Network Training with Diffusion Model
Jiangtong Tan, Feng Zhao
0
0
Image restoration has made marvelous progress with the advent of deep learning. Previous methods usually rely on designing powerful network architecture to elevate performance, however, the natural visual effect of the restored results is limited by color and texture distortions. Besides the visual perceptual quality, the semantic perception recovery is an important but often overlooked perspective of restored image, which is crucial for the deployment in high-level tasks. In this paper, we propose a new perspective to resort these issues by introducing a naturalness-oriented and semantic-aware optimization mechanism, dubbed DiffLoss. Specifically, inspired by the powerful distribution coverage capability of the diffusion model for natural image generation, we exploit the Markov chain sampling property of diffusion model and project the restored results of existing networks into the sampling space. Besides, we reveal that the bottleneck feature of diffusion models, also dubbed h-space feature, is a natural high-level semantic space. We delve into this property and propose a semantic-aware loss to further unlock its potential of semantic perception recovery, which paves the way to connect image restoration task and downstream high-level recognition task. With these two strategies, the DiffLoss can endow existing restoration methods with both more natural and semantic-aware results. We verify the effectiveness of our method on substantial common image restoration tasks and benchmarks. Code will be available at https://github.com/JosephTiTan/DiffLoss.
6/28/2024

DaLPSR: Leverage Degradation-Aligned Language Prompt for Real-World Image Super-Resolution
Aiwen Jiang, Zhi Wei, Long Peng, Feiqiang Liu, Wenbo Li, Mingwen Wang
0
0
Image super-resolution pursuits reconstructing high-fidelity high-resolution counterpart for low-resolution image. In recent years, diffusion-based models have garnered significant attention due to their capabilities with rich prior knowledge. The success of diffusion models based on general text prompts has validated the effectiveness of textual control in the field of text2image. However, given the severe degradation commonly presented in low-resolution images, coupled with the randomness characteristics of diffusion models, current models struggle to adequately discern semantic and degradation information within severely degraded images. This often leads to obstacles such as semantic loss, visual artifacts, and visual hallucinations, which pose substantial challenges for practical use. To address these challenges, this paper proposes to leverage degradation-aligned language prompt for accurate, fine-grained, and high-fidelity image restoration. Complementary priors including semantic content descriptions and degradation prompts are explored. Specifically, on one hand, image-restoration prompt alignment decoder is proposed to automatically discern the degradation degree of LR images, thereby generating beneficial degradation priors for image restoration. On the other hand, much richly tailored descriptions from pretrained multimodal large language model elicit high-level semantic priors closely aligned with human perception, ensuring fidelity control for image restoration. Comprehensive comparisons with state-of-the-art methods have been done on several popular synthetic and real-world benchmark datasets. The quantitative and qualitative analysis have demonstrated that the proposed method achieves a new state-of-the-art perceptual quality level, especially in real-world cases based on reference-free metrics.
6/26/2024

Joint Conditional Diffusion Model for Image Restoration with Mixed Degradations
Yufeng Yue, Meng Yu, Luojie Yang, Yi Yang
0
0
Image restoration is rather challenging in adverse weather conditions, especially when multiple degradations occur simultaneously. Blind image decomposition was proposed to tackle this issue, however, its effectiveness heavily relies on the accurate estimation of each component. Although diffusion-based models exhibit strong generative abilities in image restoration tasks, they may generate irrelevant contents when the degraded images are severely corrupted. To address these issues, we leverage physical constraints to guide the whole restoration process, where a mixed degradation model based on atmosphere scattering model is constructed. Then we formulate our Joint Conditional Diffusion Model (JCDM) by incorporating the degraded image and degradation mask to provide precise guidance. To achieve better color and detail recovery results, we further integrate a refinement network to reconstruct the restored image, where Uncertainty Estimation Block (UEB) is employed to enhance the features. Extensive experiments performed on both multi-weather and weather-specific datasets demonstrate the superiority of our method over state-of-the-art competing methods.
4/12/2024

Referring Flexible Image Restoration
Runwei Guan, Rongsheng Hu, Zhuhao Zhou, Tianlang Xue, Ka Lok Man, Jeremy Smith, Eng Gee Lim, Weiping Ding, Yutao Yue
0
0
In reality, images often exhibit multiple degradations, such as rain and fog at night (triple degradations). However, in many cases, individuals may not want to remove all degradations, for instance, a blurry lens revealing a beautiful snowy landscape (double degradations). In such scenarios, people may only desire to deblur. These situations and requirements shed light on a new challenge in image restoration, where a model must perceive and remove specific degradation types specified by human commands in images with multiple degradations. We term this task Referring Flexible Image Restoration (RFIR). To address this, we first construct a large-scale synthetic dataset called RFIR, comprising 153,423 samples with the degraded image, text prompt for specific degradation removal and restored image. RFIR consists of five basic degradation types: blur, rain, haze, low light and snow while six main sub-categories are included for varying degrees of degradation removal. To tackle the challenge, we propose a novel transformer-based multi-task model named TransRFIR, which simultaneously perceives degradation types in the degraded image and removes specific degradation upon text prompt. TransRFIR is based on two devised attention modules, Multi-Head Agent Self-Attention (MHASA) and Multi-Head Agent Cross Attention (MHACA), where MHASA and MHACA introduce the agent token and reach the linear complexity, achieving lower computation cost than vanilla self-attention and cross-attention and obtaining competitive performances. Our TransRFIR achieves state-of-the-art performances compared with other counterparts and is proven as an effective architecture for image restoration. We release our project at https://github.com/GuanRunwei/FIR-CP.
4/17/2024