Dynamic Resolution Guidance for Facial Expression Recognition
2404.06365
0
0

Abstract
Facial expression recognition (FER) is vital for human-computer interaction and emotion analysis, yet recognizing expressions in low-resolution images remains challenging. This paper introduces a practical method called Dynamic Resolution Guidance for Facial Expression Recognition (DRGFER) to effectively recognize facial expressions in images with varying resolutions without compromising FER model accuracy. Our framework comprises two main components: the Resolution Recognition Network (RRN) and the Multi-Resolution Adaptation Facial Expression Recognition Network (MRAFER). The RRN determines image resolution, outputs a binary vector, and the MRAFER assigns images to suitable facial expression recognition networks based on resolution. We evaluated DRGFER on widely-used datasets RAFDB and FERPlus, demonstrating that our method retains optimal model performance at each resolution and outperforms alternative resolution approaches. The proposed framework exhibits robustness against resolution variations and facial expressions, offering a promising solution for real-world applications.
Create account to get full access
Overview
- This paper presents a novel approach for facial expression recognition that dynamically adjusts the image resolution during the recognition process.
- The proposed method, called Dynamic Resolution Guidance (DRG), aims to improve the accuracy and efficiency of facial expression recognition by adaptively selecting the optimal resolution for different facial regions.
- DRG is designed to work with existing facial expression recognition models, making it a flexible and complementary solution.
Plain English Explanation
The paper describes a new way to recognize facial expressions more accurately and efficiently. The key idea is to adjust the image resolution [link to "effective-adapter-face-recognition-wild"] dynamically during the recognition process, instead of using a fixed resolution.
The method, called Dynamic Resolution Guidance (DRG), analyzes different parts of the face and selects the optimal resolution for each region. For example, the mouth area might need a higher resolution to capture subtle expressions, while the forehead area could be analyzed at a lower resolution.
By adapting the resolution to the specific needs of each facial region, DRG can achieve better recognition accuracy compared to using a single, fixed resolution for the entire face. It also helps to reduce the computational cost, as lower resolutions require less processing power.
The key advantage of DRG is that it can be used in combination with existing facial expression recognition models. This makes it a flexible and complementary solution that can be easily integrated into various applications, such as [link to "music-recommendation-based-facial-emotion-recognition"] emotion-based music recommendation or [link to "real-gdsr-real-world-guided-dsm-super"] real-world scene understanding.
Technical Explanation
The paper proposes a Dynamic Resolution Guidance (DRG) method for facial expression recognition. The core idea is to adaptively select the optimal resolution for different facial regions during the recognition process, rather than using a fixed resolution for the entire face.
The DRG approach consists of two main components:
-
Resolution Guidance Module: This module analyzes the input face image and generates a "resolution guidance map" that indicates the optimal resolution for each facial region. The guidance map is produced using a lightweight convolutional neural network.
-
Single Model Adaptation: The resolution guidance map is then used to adaptively adjust the resolution of the input image before feeding it into the facial expression recognition model. This allows the model to focus on the most informative facial regions at higher resolutions, while processing less critical areas at lower resolutions.
The authors evaluate the DRG method on several benchmark datasets for facial expression recognition and show that it can achieve superior performance compared to using a fixed-resolution approach. The adaptive resolution strategy also leads to a reduction in computational cost, as lower resolutions require less processing power.
The DRG method is designed to be a flexible and complementary solution that can be easily integrated with existing facial expression recognition models. This makes it a promising approach for improving the accuracy and efficiency of facial analysis systems, with potential applications in areas like [link to "csr-dmri-continuous-super-resolution-diffusion-mri"] medical imaging, [link to "music-recommendation-based-facial-emotion-recognition"] human-computer interaction, and [link to "hdr-imaging-dynamic-scenes-events"] real-world scene understanding.
Critical Analysis
The paper presents a well-designed and empirically validated approach for improving facial expression recognition through dynamic resolution guidance. The key strengths of the DRG method include:
- Adaptive Resolution: The ability to dynamically adjust the resolution of different facial regions is a novel and effective strategy for improving recognition accuracy.
- Flexibility: DRG is designed to be a complementary solution that can be integrated with existing facial expression recognition models, making it a versatile and practical approach.
- Efficiency: The reduction in computational cost due to the adaptive resolution strategy is a valuable benefit, especially for real-time applications.
However, the paper also acknowledges some limitations and areas for further research:
- Dataset Bias: The evaluation was conducted on standard facial expression recognition datasets, which may not fully represent the diversity and complexity of real-world scenarios. [link to "effective-adapter-face-recognition-wild"]
- Task-specific Optimization: The DRG method is general and can be applied to various facial analysis tasks, but further optimization may be needed for specific applications, such as [link to "music-recommendation-based-facial-emotion-recognition"] emotion recognition or [link to "real-gdsr-real-world-guided-dsm-super"] facial landmark detection.
- Hardware Considerations: The authors note that the computational efficiency of DRG may depend on the specific hardware and GPU resources available, which could impact its real-world deployment.
Overall, the Dynamic Resolution Guidance approach presented in this paper is a promising contribution to the field of facial expression recognition. The authors have demonstrated the effectiveness of their method and highlighted potential areas for further research and development.
Conclusion
The Dynamic Resolution Guidance (DRG) method proposed in this paper offers a novel and effective way to improve the accuracy and efficiency of facial expression recognition. By adaptively selecting the optimal resolution for different facial regions, DRG can outperform traditional fixed-resolution approaches while also reducing computational costs.
The flexibility of DRG, which allows it to be integrated with existing facial analysis models, makes it a valuable and complementary solution for a wide range of applications, from [link to "music-recommendation-based-facial-emotion-recognition"] emotion-based music recommendation to [link to "hdr-imaging-dynamic-scenes-events"] real-world scene understanding. As the authors note, further research is needed to address dataset biases and task-specific optimization, but the DRG method represents an important step forward in enhancing the performance and practicality of facial expression recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
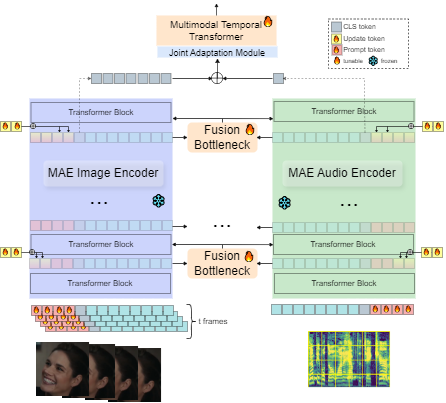
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
0
0
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
4/16/2024
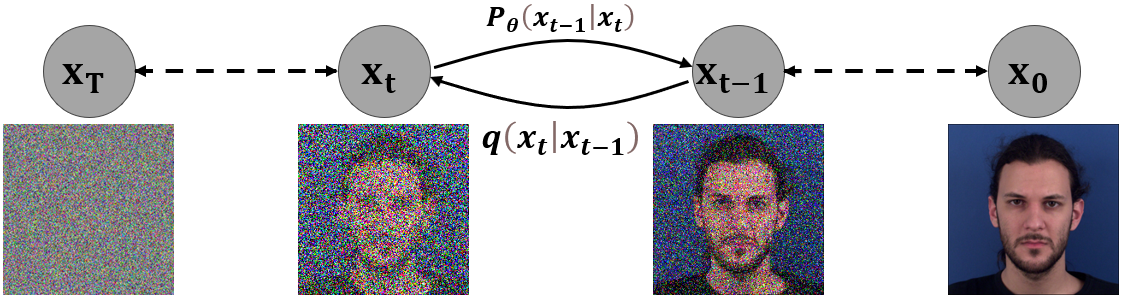
FacEnhance: Facial Expression Enhancing with Recurrent DDPMs
Hamza Bouzid, Lahoucine Ballihi
0
0
Facial expressions, vital in non-verbal human communication, have found applications in various computer vision fields like virtual reality, gaming, and emotional AI assistants. Despite advancements, many facial expression generation models encounter challenges such as low resolution (e.g., 32x32 or 64x64 pixels), poor quality, and the absence of background details. In this paper, we introduce FacEnhance, a novel diffusion-based approach addressing constraints in existing low-resolution facial expression generation models. FacEnhance enhances low-resolution facial expression videos (64x64 pixels) to higher resolutions (192x192 pixels), incorporating background details and improving overall quality. Leveraging conditional denoising within a diffusion framework, guided by a background-free low-resolution video and a single neutral expression high-resolution image, FacEnhance generates a video incorporating the facial expression from the low-resolution video performed by the individual with background from the neutral image. By complementing lightweight low-resolution models, FacEnhance strikes a balance between computational efficiency and desirable image resolution and quality. Extensive experiments on the MUG facial expression database demonstrate the efficacy of FacEnhance in enhancing low-resolution model outputs to state-of-the-art quality while preserving content and identity consistency. FacEnhance represents significant progress towards resource-efficient, high-fidelity facial expression generation, Renewing outdated low-resolution methods to up-to-date standards.
6/14/2024

Seeking Certainty In Uncertainty: Dual-Stage Unified Framework Solving Uncertainty in Dynamic Facial Expression Recognition
Haoran Wang, Xinji Mai, Zeng Tao, Xuan Tong, Junxiong Lin, Yan Wang, Jiawen Yu, Boyang Wang, Shaoqi Yan, Qing Zhao, Ziheng Zhou, Shuyong Gao, Wenqiang Zhang
0
0
The contemporary state-of-the-art of Dynamic Facial Expression Recognition (DFER) technology facilitates remarkable progress by deriving emotional mappings of facial expressions from video content, underpinned by training on voluminous datasets. Yet, the DFER datasets encompass a substantial volume of noise data. Noise arises from low-quality captures that defy logical labeling, and instances that suffer from mislabeling due to annotation bias, engendering two principal types of uncertainty: the uncertainty regarding data usability and the uncertainty concerning label reliability. Addressing the two types of uncertainty, we have meticulously crafted a two-stage framework aiming at textbf{S}eeking textbf{C}ertain data textbf{I}n extensive textbf{U}ncertain data (SCIU). This initiative aims to purge the DFER datasets of these uncertainties, thereby ensuring that only clean, verified data is employed in training processes. To mitigate the issue of low-quality samples, we introduce the Coarse-Grained Pruning (CGP) stage, which assesses sample weights and prunes those deemed unusable due to their low weight. For samples with incorrect annotations, the Fine-Grained Correction (FGC) stage evaluates prediction stability to rectify mislabeled data. Moreover, SCIU is conceived as a universally compatible, plug-and-play framework, tailored to integrate seamlessly with prevailing DFER methodologies. Rigorous experiments across prevalent DFER datasets and against numerous benchmark methods substantiates SCIU's capacity to markedly elevate performance metrics.
6/26/2024

OUS: Scene-Guided Dynamic Facial Expression Recognition
Xinji Mai, Haoran Wang, Zeng Tao, Junxiong Lin, Shaoqi Yan, Yan Wang, Jing Liu, Jiawen Yu, Xuan Tong, Yating Li, Wenqiang Zhang
0
0
Dynamic Facial Expression Recognition (DFER) is crucial for affective computing but often overlooks the impact of scene context. We have identified a significant issue in current DFER tasks: human annotators typically integrate emotions from various angles, including environmental cues and body language, whereas existing DFER methods tend to consider the scene as noise that needs to be filtered out, focusing solely on facial information. We refer to this as the Rigid Cognitive Problem. The Rigid Cognitive Problem can lead to discrepancies between the cognition of annotators and models in some samples. To align more closely with the human cognitive paradigm of emotions, we propose an Overall Understanding of the Scene DFER method (OUS). OUS effectively integrates scene and facial features, combining scene-specific emotional knowledge for DFER. Extensive experiments on the two largest datasets in the DFER field, DFEW and FERV39k, demonstrate that OUS significantly outperforms existing methods. By analyzing the Rigid Cognitive Problem, OUS successfully understands the complex relationship between scene context and emotional expression, closely aligning with human emotional understanding in real-world scenarios.
5/30/2024