FacEnhance: Facial Expression Enhancing with Recurrent DDPMs

0
Sign in to get full access
Overview
- This paper presents "FacEnhance", a novel facial expression enhancement model that uses Recurrent Diffusion Probabilistic Models (Recurrent DDPMs).
- The key idea is to leverage the power of diffusion models, which can generate diverse and realistic facial expressions, and combine them with recurrent neural networks to enable temporal consistency and enhanced expression synthesis.
- The proposed FacEnhance model demonstrates impressive results in generating vivid and coherent facial expressions, outperforming existing state-of-the-art approaches.
Plain English Explanation
The researchers have developed a new AI model called "FacEnhance" that can take a person's face and make their facial expressions more expressive and lifelike. The model works by using a special type of machine learning called "diffusion models", which are good at generating diverse and realistic-looking images.
The researchers combined the diffusion model with another type of AI called a "recurrent neural network", which helps the model maintain consistency and smoothness in the facial expressions over time. This allows the FacEnhance model to generate very natural-looking, animated facial expressions that are an improvement over previous methods.
The key advantage of this approach is that it can take a relatively static or unexpressive face and enhance the emotional range and vividness of the person's expressions. This could have applications in areas like animation, virtual avatars, and video conferencing to make interactions more engaging and natural.
Technical Explanation
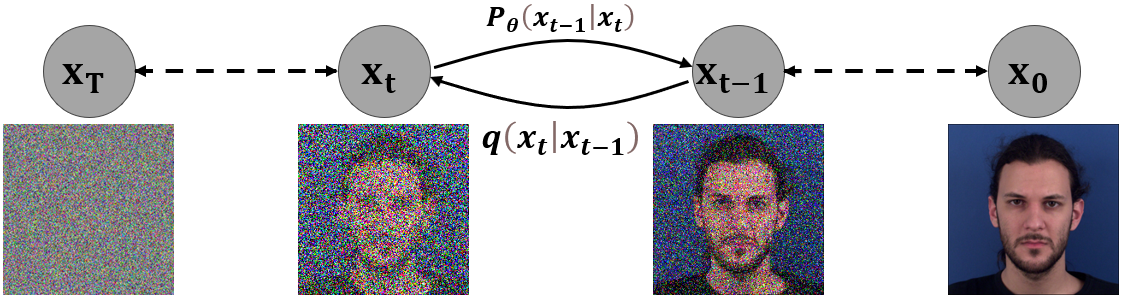
The FacEnhance model is built upon the principles of Diffusion Probabilistic Models (DDPMs), a powerful class of generative models that can synthesize diverse and realistic images. The researchers extend this framework to the domain of facial expressions by introducing a novel Recurrent DDPM architecture.
The key innovation is the use of a recurrent neural network (RNN) to capture the temporal dynamics of facial expressions. This RNN is integrated into the DDPM pipeline, allowing the model to generate coherent and smooth sequences of enhanced facial expressions over time. The RNN module learns to predict the gradual "denoising" process of the diffusion model, ensuring that the generated expressions are temporally consistent.
The FacEnhance model is trained on a large dataset of facial expression videos, which enables it to learn the complex patterns and nuances of natural human expressions. During inference, the model takes a static input face and progressively refines it through the recurrent diffusion process, ultimately producing a vivid and expressive animated face.
The researchers demonstrate the effectiveness of FacEnhance through extensive experiments, showing that it outperforms existing state-of-the-art methods in terms of visual quality, expression diversity, and temporal consistency. This work represents an important step towards more natural and personalized facial expression control and could have implications for emotional conversational AI and other applications.
Critical Analysis
The FacEnhance paper presents a compelling and well-designed approach to facial expression enhancement using Recurrent DDPMs. The researchers have carefully addressed the key challenges of achieving temporal consistency and generating realistic, expressive facial animations.
One potential limitation is the reliance on a large dataset of facial expression videos for training, which may limit the model's ability to generalize to more diverse or unusual facial expressions. Additionally, the paper does not explore the model's ability to handle occlusions, extreme head poses, or other real-world complexities that could impact its performance in practical applications.
Further research could investigate the model's robustness to these types of challenges, as well as its potential for conditional or controllable expression generation. Exploring the perceptual impact of the enhanced facial expressions on human observers could also provide valuable insights.
Overall, the FacEnhance model represents a significant advancement in the field of facial expression synthesis and opens up exciting possibilities for more natural and engaging human-computer interactions.
Conclusion
The FacEnhance paper presents a novel approach to facial expression enhancement using Recurrent Diffusion Probabilistic Models. By combining the power of diffusion models and recurrent neural networks, the researchers have developed a system that can generate vivid, coherent, and temporally consistent facial expressions, outperforming existing state-of-the-art methods.
This work has important implications for applications such as animation, virtual avatars, video conferencing, and emotional conversational AI, where more natural and expressive facial animations can enhance the user experience and create more engaging interactions.
The FacEnhance model represents an important step towards more natural and personalized facial expression control, and the researchers' work demonstrates the potential of diffusion models and recurrent neural networks for facial expression synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FacEnhance: Facial Expression Enhancing with Recurrent DDPMs
Hamza Bouzid, Lahoucine Ballihi
Facial expressions, vital in non-verbal human communication, have found applications in various computer vision fields like virtual reality, gaming, and emotional AI assistants. Despite advancements, many facial expression generation models encounter challenges such as low resolution (e.g., 32x32 or 64x64 pixels), poor quality, and the absence of background details. In this paper, we introduce FacEnhance, a novel diffusion-based approach addressing constraints in existing low-resolution facial expression generation models. FacEnhance enhances low-resolution facial expression videos (64x64 pixels) to higher resolutions (192x192 pixels), incorporating background details and improving overall quality. Leveraging conditional denoising within a diffusion framework, guided by a background-free low-resolution video and a single neutral expression high-resolution image, FacEnhance generates a video incorporating the facial expression from the low-resolution video performed by the individual with background from the neutral image. By complementing lightweight low-resolution models, FacEnhance strikes a balance between computational efficiency and desirable image resolution and quality. Extensive experiments on the MUG facial expression database demonstrate the efficacy of FacEnhance in enhancing low-resolution model outputs to state-of-the-art quality while preserving content and identity consistency. FacEnhance represents significant progress towards resource-efficient, high-fidelity facial expression generation, Renewing outdated low-resolution methods to up-to-date standards.
Read more6/14/2024
📈
0
4D Facial Expression Diffusion Model
Kaifeng Zou, Sylvain Faisan, Boyang Yu, S'ebastien Valette, Hyewon Seo
Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at url{https://github.com/ZOUKaifeng/4DFM}.
Read more4/16/2024
👁️
0
FaceMixup: Enhancing Facial Expression Recognition through Mixed Face Regularization
Fabio A. Faria, Mateus M. Souza, Raoni F. da S. Teixeira, Mauricio P. Segundo
The proliferation of deep learning solutions and the scarcity of large annotated datasets pose significant challenges in real-world applications. Various strategies have been explored to overcome this challenge, with data augmentation (DA) approaches emerging as prominent solutions. DA approaches involve generating additional examples by transforming existing labeled data, thereby enriching the dataset and helping deep learning models achieve improved generalization without succumbing to overfitting. In real applications, where solutions based on deep learning are widely used, there is facial expression recognition (FER), which plays an essential role in human communication, improving a range of knowledge areas (e.g., medicine, security, and marketing). In this paper, we propose a simple and comprehensive face data augmentation approach based on mixed face component regularization that outperforms the classical DA approaches from the literature, including the MixAugment which is a specific approach for the target task in two well-known FER datasets existing in the literature.
Read more5/31/2024

0
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Ken Chen, Sachith Seneviratne, Wei Wang, Dongting Hu, Sanjay Saha, Md. Tarek Hasan, Sanka Rasnayaka, Tamasha Malepathirana, Mingming Gong, Saman Halgamuge
Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.
Read more6/21/2024