MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
2404.09010
0
0
Abstract
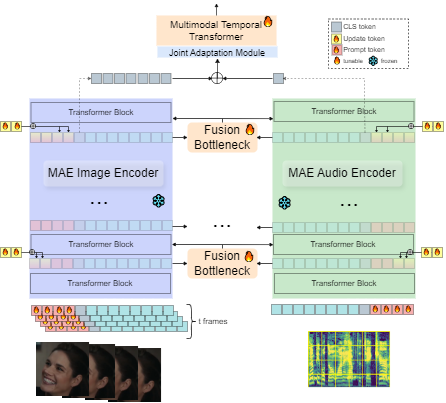
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
Create account to get full access
Overview
- This research paper presents a novel multimodal approach called MMA-DFER for dynamic facial expression recognition in the wild.
- The key idea is to adapt unimodal models (e.g., vision-only or audio-only) to a multimodal setting by leveraging complementary information from different modalities.
- The proposed method aims to improve the robustness and generalization of facial expression recognition in unconstrained, real-world scenarios.
Plain English Explanation
The paper focuses on the task of dynamic facial expression recognition in-the-wild, which means identifying the emotions expressed on a person's face in real-world, uncontrolled settings. This is a challenging problem because facial expressions can vary significantly based on factors like lighting, camera angle, and the person's natural movements.
To address this, the researchers developed a new technique called MMA-DFER, which stands for "MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition." The key idea is to take existing models that are trained on a single type of data (e.g., just video or just audio) and "adapt" them to work together in a multimodal setting. By combining information from multiple sources, like both video and audio, the model can become more robust and accurate at recognizing emotions in the real world.
The researchers show that their MMA-DFER approach outperforms previous methods for dynamic facial expression recognition, especially in challenging in-the-wild scenarios. This is an important advancement, as accurate facial expression recognition has many practical applications, such as in human-computer interaction, mental health monitoring, and entertainment analytics.
Technical Explanation
The paper first reviews the related work on dynamic facial expression recognition, noting the challenges of handling unconstrained, real-world data. It then presents the MMA-DFER framework, which consists of three key components:
-
Unimodal Feature Extraction: The method takes pre-trained unimodal feature extractors (e.g., vision-only or audio-only models) and fine-tunes them on the target facial expression dataset.
-
Multimodal Adaptation: A multimodal adaptation module is introduced to align and fuse the unimodal features, allowing the model to learn complementary information from different modalities.
-
Dynamic Facial Expression Recognition: The fused multimodal features are then used for the final facial expression recognition task, which can handle temporal dynamics in the input.
The authors evaluate their approach on several in-the-wild facial expression datasets and show that MMA-DFER outperforms previous state-of-the-art methods in terms of accuracy, robustness, and generalization. They also provide ablation studies to understand the contribution of each component of the framework.
Critical Analysis
The paper presents a well-designed and thorough approach to the challenging problem of dynamic facial expression recognition in unconstrained settings. The key strengths of the work include the novel multimodal adaptation strategy, the comprehensive evaluation on diverse in-the-wild datasets, and the detailed ablation studies.
However, the paper could have benefited from a more in-depth discussion of the limitations and potential issues with the proposed method. For example, the authors do not address how the approach would scale to real-world scenarios with a large number of facial expressions or how it might handle biases in the training data.
Additionally, the paper could have provided more insights into the types of errors the model makes and the specific scenarios where it struggles. This could have helped to identify areas for future research and improvement, such as addressing the challenges of multimodal fusion or leveraging additional modalities.
Conclusion
The MMA-DFER framework presented in this paper represents a significant advancement in the field of dynamic facial expression recognition in the wild. By adapting unimodal models to a multimodal setting, the researchers have developed a robust and generalizable approach that outperforms previous state-of-the-art methods.
This work has important implications for real-world applications that require accurate and reliable facial expression recognition, such as human-computer interaction, mental health monitoring, and entertainment analytics. The insights and techniques presented in this paper can also serve as a foundation for further research in multimodal perception and adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
MultiMAE-DER: Multimodal Masked Autoencoder for Dynamic Emotion Recognition
Peihao Xiang, Chaohao Lin, Kaida Wu, Ou Bai
0
0
This paper presents a novel approach to processing multimodal data for dynamic emotion recognition, named as the Multimodal Masked Autoencoder for Dynamic Emotion Recognition (MultiMAE-DER). The MultiMAE-DER leverages the closely correlated representation information within spatiotemporal sequences across visual and audio modalities. By utilizing a pre-trained masked autoencoder model, the MultiMAEDER is accomplished through simple, straightforward finetuning. The performance of the MultiMAE-DER is enhanced by optimizing six fusion strategies for multimodal input sequences. These strategies address dynamic feature correlations within cross-domain data across spatial, temporal, and spatiotemporal sequences. In comparison to state-of-the-art multimodal supervised learning models for dynamic emotion recognition, MultiMAE-DER enhances the weighted average recall (WAR) by 4.41% on the RAVDESS dataset and by 2.06% on the CREMAD. Furthermore, when compared with the state-of-the-art model of multimodal self-supervised learning, MultiMAE-DER achieves a 1.86% higher WAR on the IEMOCAP dataset.
5/17/2024
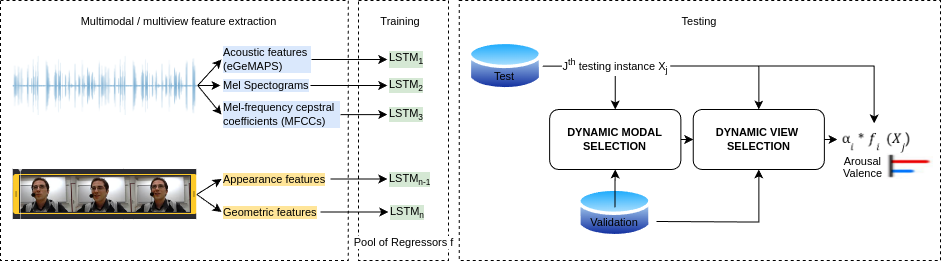
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024

Joint Multimodal Transformer for Emotion Recognition in the Wild
Paul Waligora, Haseeb Aslam, Osama Zeeshan, Soufiane Belharbi, Alessandro Lameiras Koerich, Marco Pedersoli, Simon Bacon, Eric Granger
0
0
Multimodal emotion recognition (MMER) systems typically outperform unimodal systems by leveraging the inter- and intra-modal relationships between, e.g., visual, textual, physiological, and auditory modalities. This paper proposes an MMER method that relies on a joint multimodal transformer (JMT) for fusion with key-based cross-attention. This framework can exploit the complementary nature of diverse modalities to improve predictive accuracy. Separate backbones capture intra-modal spatiotemporal dependencies within each modality over video sequences. Subsequently, our JMT fusion architecture integrates the individual modality embeddings, allowing the model to effectively capture inter- and intra-modal relationships. Extensive experiments on two challenging expression recognition tasks -- (1) dimensional emotion recognition on the Affwild2 dataset (with face and voice) and (2) pain estimation on the Biovid dataset (with face and biosensors) -- indicate that our JMT fusion can provide a cost-effective solution for MMER. Empirical results show that MMER systems with our proposed fusion allow us to outperform relevant baseline and state-of-the-art methods.
4/23/2024
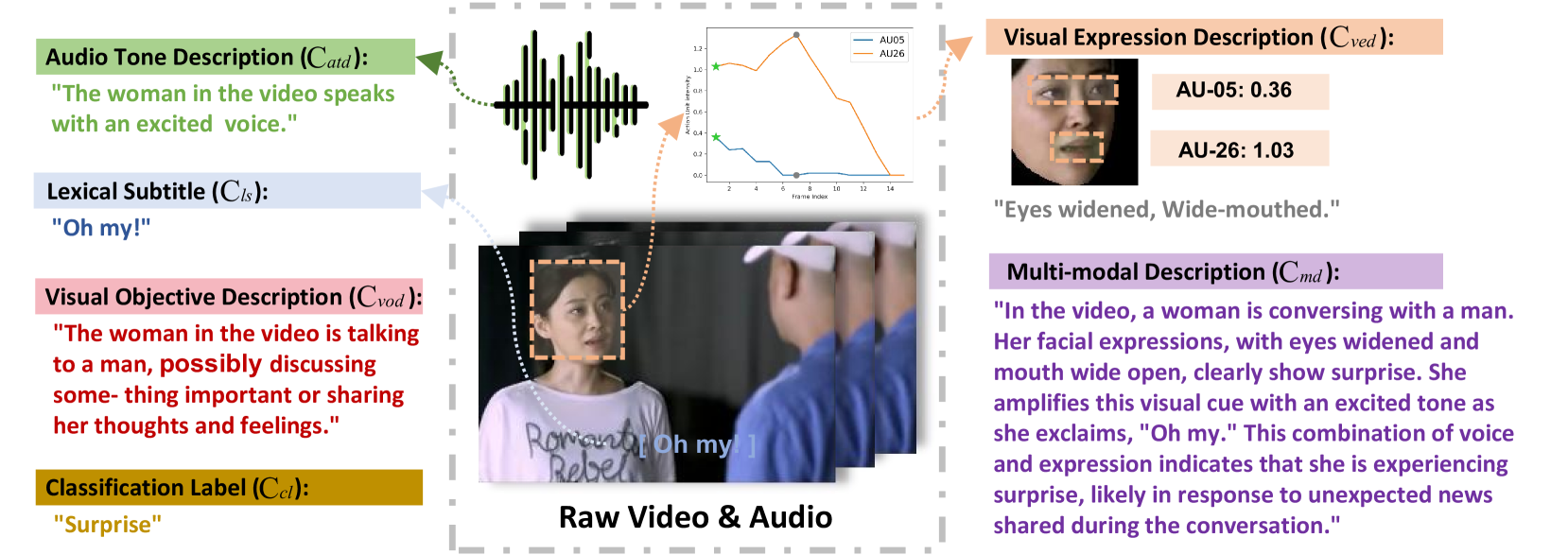
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024