E-TSL: A Continuous Educational Turkish Sign Language Dataset with Baseline Methods
2405.02984
0
0
Abstract
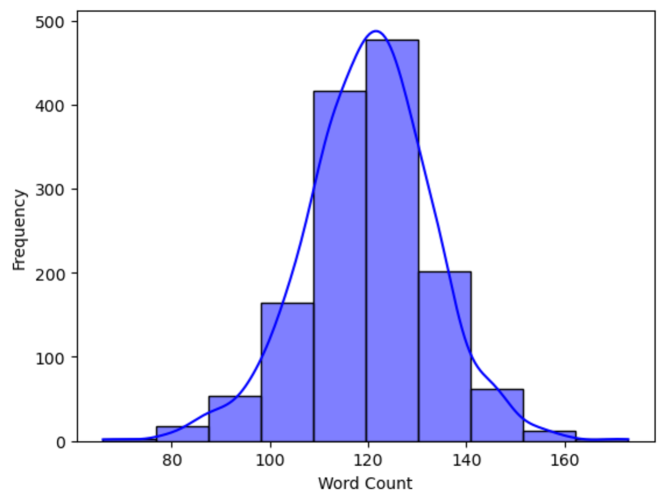
This study introduces the continuous Educational Turkish Sign Language (E-TSL) dataset, collected from online Turkish language lessons for 5th, 6th, and 8th grades. The dataset comprises 1,410 videos totaling nearly 24 hours and includes performances from 11 signers. Turkish, an agglutinative language, poses unique challenges for sign language translation, particularly with a vocabulary where 64% are singleton words and 85% are rare words, appearing less than five times. We developed two baseline models to address these challenges: the Pose to Text Transformer (P2T-T) and the Graph Neural Network based Transformer (GNN-T) models. The GNN-T model achieved 19.13% BLEU-1 score and 3.28% BLEU-4 score, presenting a significant challenge compared to existing benchmarks. The P2T-T model, while demonstrating slightly lower performance in BLEU scores, achieved a higher ROUGE-L score of 22.09%. Additionally, we benchmarked our model using the well-known PHOENIX-Weather 2014T dataset to validate our approach.
Create account to get full access
Overview
- This paper introduces E-TSL, a continuous educational Turkish Sign Language dataset with baseline methods.
- The dataset includes video recordings of native Turkish Sign Language signers performing various educational signs and sentences.
- The authors propose two baseline methods for continuous Turkish Sign Language recognition: a graph neural network and a transformer model.
- The paper aims to advance the field of sign language translation and recognition, particularly for the Turkish Sign Language.
Plain English Explanation
This research paper focuses on creating a new dataset for Turkish Sign Language (TSL) and developing methods to recognize continuous sign language gestures. The researchers compiled a dataset called E-TSL, which contains videos of native TSL signers performing educational signs and sentences.
To analyze this dataset, the researchers tested two different machine learning models: a graph neural network and a transformer model. These models are designed to take in the video data and learn to recognize the continuous sign language gestures being performed.
The significance of this work is that it helps advance the field of sign language translation and recognition, particularly for the Turkish language. By creating a high-quality dataset and benchmarking it with state-of-the-art models, the researchers are providing valuable resources and insights that can aid the development of better sign language technology. This can ultimately improve accessibility and communication for the Deaf and hard-of-hearing Turkish community.
Technical Explanation
The authors introduce the E-TSL dataset, a continuous educational Turkish Sign Language dataset. It contains video recordings of native Turkish Sign Language signers performing a variety of educational signs and sentences. The dataset is designed to support research in continuous sign language recognition and translation.
To establish baseline methods for E-TSL, the authors propose two models:
-
Graph Neural Network: This model represents the signer's hand and body movements as a dynamic graph, with the graph nodes corresponding to key body joints. The graph neural network is then used to learn patterns in the joint trajectories and recognize the sign language gestures.
-
Transformer Model: The authors also explore using a transformer-based architecture, which has shown success in various sequence-to-sequence tasks. The transformer model takes the video frames as input and learns to map them to the corresponding sign language sequences.
The authors evaluate the performance of these two baseline methods on the E-TSL dataset and report their findings. The results demonstrate the challenges of continuous sign language recognition and provide a starting point for future research in this area.
Critical Analysis
The E-TSL dataset and the proposed baseline methods represent a valuable contribution to the field of sign language recognition. By focusing on the underrepresented Turkish Sign Language, the authors are addressing an important gap in the research landscape.
One potential limitation of the work is the size and diversity of the E-TSL dataset. While the authors have made efforts to collect a continuous sign language dataset, it may not be large or varied enough to fully capture the complexity of real-world sign language usage. Further expanding the dataset with more signers, sign types, and contextual scenarios could enhance the generalizability of the baseline methods.
Additionally, the paper does not provide a detailed analysis of the challenges and trade-offs between the graph neural network and transformer-based approaches. A more in-depth comparison of the model architectures, their strengths, and their weaknesses could offer greater insights for future researchers.
Finally, the authors could have explored the potential of transfer learning techniques, such as leveraging cross-dataset knowledge or using skeleton-based sign language recognition, to further improve the performance of the baseline methods on the E-TSL dataset.
Conclusion
This paper presents the E-TSL dataset, a valuable resource for continuous Turkish Sign Language recognition research. The authors also propose two baseline methods, a graph neural network and a transformer model, to serve as starting points for future work in this area.
The significance of this research lies in its potential to advance the field of sign language translation and recognition, particularly for the underserved Turkish Deaf community. By providing a high-quality dataset and establishing initial benchmark methods, the authors have laid the foundation for further developments in improving continuous sign language recognition and expanding language models for Turkish. This work can ultimately enhance accessibility and communication for Deaf and hard-of-hearing individuals in Turkey.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Charles Raude, K R Prajwal, Liliane Momeni, Hannah Bull, Samuel Albanie, Andrew Zisserman, Gul Varol
0
0
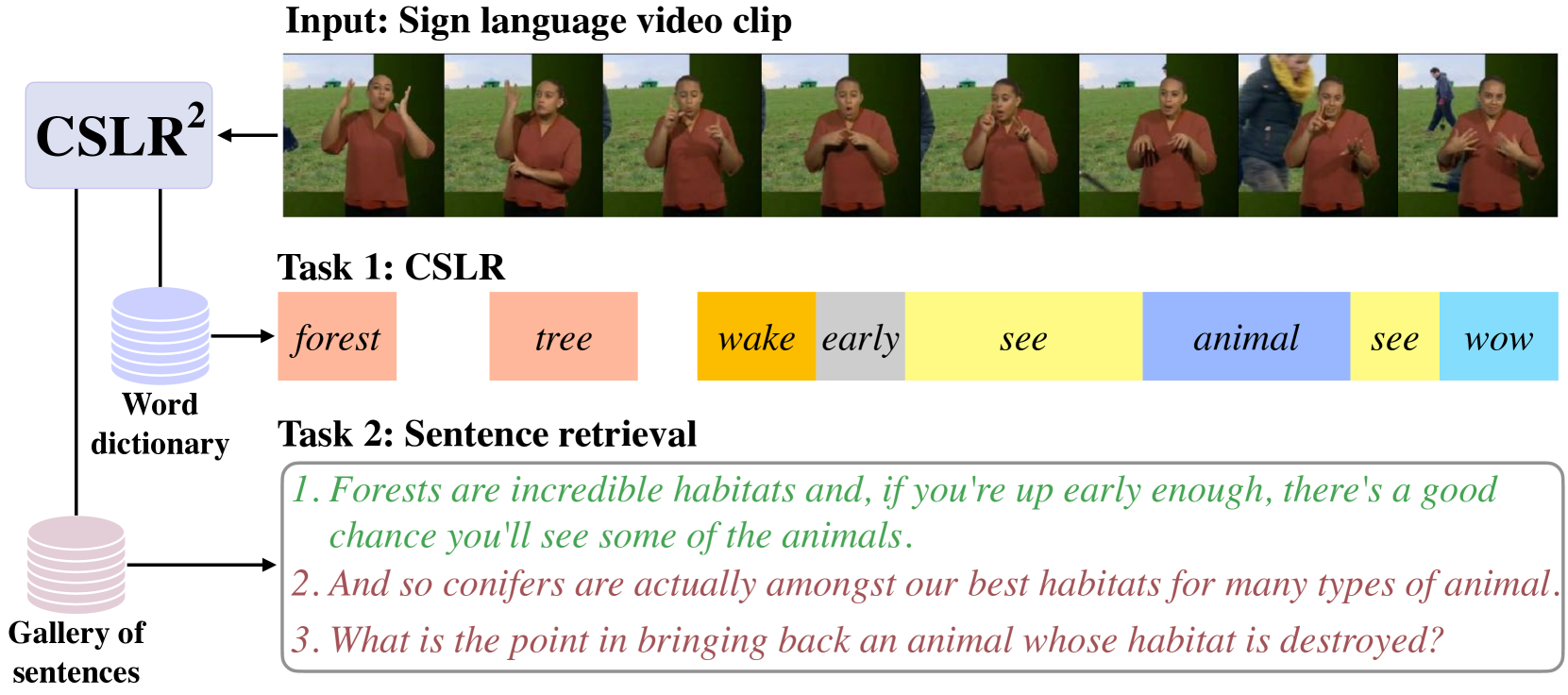
In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
5/17/2024

A Comparative Study of Continuous Sign Language Recognition Techniques
Sarah Alyami, Hamzah Luqman
0
0
Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.
6/19/2024

A Hong Kong Sign Language Corpus Collected from Sign-interpreted TV News
Zhe Niu, Ronglai Zuo, Brian Mak, Fangyun Wei
0
0
This paper introduces TVB-HKSL-News, a new Hong Kong sign language (HKSL) dataset collected from a TV news program over a period of 7 months. The dataset is collected to enrich resources for HKSL and support research in large-vocabulary continuous sign language recognition (SLR) and translation (SLT). It consists of 16.07 hours of sign videos of two signers with a vocabulary of 6,515 glosses (for SLR) and 2,850 Chinese characters or 18K Chinese words (for SLT). One signer has 11.66 hours of sign videos and the other has 4.41 hours. One objective in building the dataset is to support the investigation of how well large-vocabulary continuous sign language recognition/translation can be done for a single signer given a (relatively) large amount of his/her training data, which could potentially lead to the development of new modeling methods. Besides, most parts of the data collection pipeline are automated with little human intervention; we believe that our collection method can be scaled up to collect more sign language data easily for SLT in the future for any sign languages if such sign-interpreted videos are available. We also run a SOTA SLR/SLT model on the dataset and get a baseline SLR word error rate of 34.08% and a baseline SLT BLEU-4 score of 23.58 for benchmarking future research on the dataset.
5/3/2024
Transfer Learning for Cross-dataset Isolated Sign Language Recognition in Under-Resourced Datasets
Ahmet Alp Kindiroglu, Ozgur Kara, Ogulcan Ozdemir, Lale Akarun
0
0
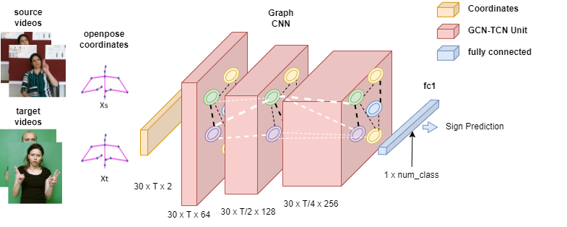
Sign language recognition (SLR) has recently achieved a breakthrough in performance thanks to deep neural networks trained on large annotated sign datasets. Of the many different sign languages, these annotated datasets are only available for a select few. Since acquiring gloss-level labels on sign language videos is difficult, learning by transferring knowledge from existing annotated sources is useful for recognition in under-resourced sign languages. This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. We use a temporal graph convolution-based sign language recognition approach to evaluate five supervised transfer learning approaches and experiment with closed-set and partial-set cross-dataset transfer learning. Experiments demonstrate that improvement over finetuning based transfer learning is possible with specialized supervised transfer learning methods.
4/16/2024