Improving Continuous Sign Language Recognition with Adapted Image Models
2404.08226
0
0
Abstract
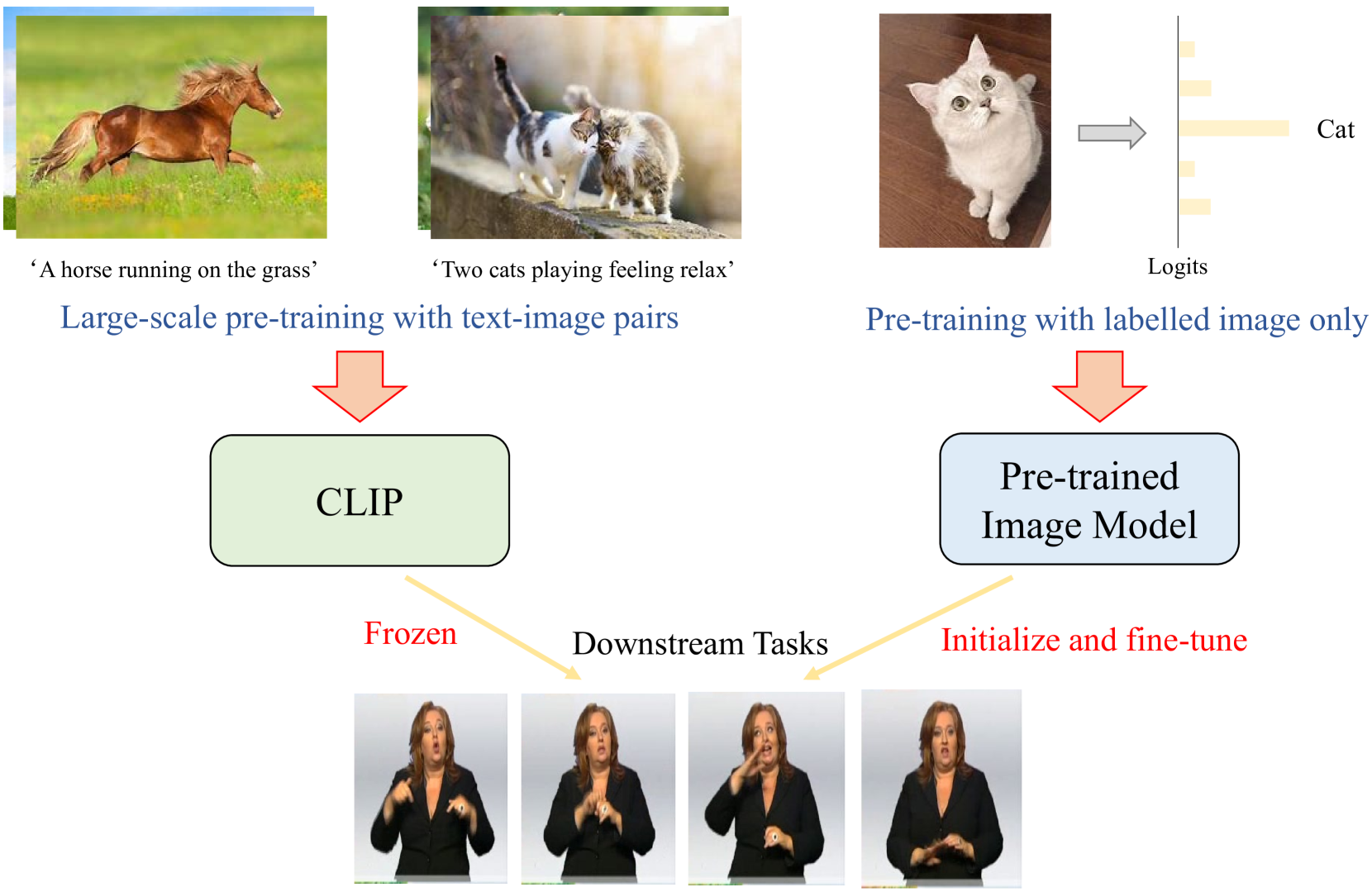
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper focuses on improving continuous sign language recognition by adapting existing image models to the task.
- The researchers explore different techniques for leveraging pre-trained image models like StepNet and CLIP for continuous sign language recognition.
- The paper provides a comprehensive analysis of the data and architectural considerations needed to effectively adapt these models.
Plain English Explanation
Sign language recognition is the task of automatically interpreting the hand gestures, facial expressions, and body movements that make up sign language. This is an important technology for improving accessibility and communication for the Deaf and hard-of-hearing community.
Continuous sign language recognition, where the model must recognize an ongoing sequence of signs rather than isolated gestures, is particularly challenging. This paper explores techniques for adapting powerful computer vision models that were originally designed for general image recognition tasks, such as StepNet and CLIP, to work effectively for continuous sign language recognition.
The key insights are around carefully curating the training data, designing the model architecture to capture both spatial and temporal information, and fine-tuning the pre-trained models to specialize in the unique characteristics of sign language. The researchers provide a detailed analysis of the data and modeling considerations to help others build more accurate and robust continuous sign language recognition systems.
Technical Explanation
The paper begins by surveying the related work in continuous sign language recognition and the various techniques that have been explored, such as using recurrent neural networks and 3D convolutional models.
The core contribution of this work is adapting powerful image recognition models like CLIP and analyzing the data and architectural considerations needed to make them effective for continuous sign language recognition. The researchers carefully curate the training data, leveraging both isolated sign samples and continuous signing sequences to capture the full range of sign language vocabulary and dynamics.
In terms of the model architecture, the authors experiment with different approaches for fusing spatial and temporal information, such as combining 2D and 3D convolutional layers. They also explore techniques for adapting the pre-trained models, including fine-tuning the model weights and incorporating modular experts to specialize different aspects of the task.
Through extensive experiments, the researchers demonstrate that their adapted models can significantly outperform previous state-of-the-art approaches for continuous sign language recognition on benchmark datasets.
Critical Analysis
The paper provides a thoughtful and comprehensive analysis of the data and architectural considerations for adapting image recognition models to continuous sign language recognition. The researchers clearly articulate the key challenges in this domain and propose innovative solutions backed by rigorous experimentation.
However, the paper does note some limitations of the current approach. For example, the models may still struggle with rare or unseen signs, and the performance on longer, more complex sign language sequences could be improved. Additionally, the paper does not explore the potential bias or fairness issues that could arise from the training data or model design.
Further research could investigate more advanced techniques for cross-modal and few-shot learning to enhance the models' ability to generalize. Exploring the integration of linguistic and contextual information could also be a promising direction for improving continuous sign language recognition in real-world applications.
Overall, this paper makes a significant contribution to the field of sign language recognition and provides a solid foundation for future work in this important area of accessible technology.
Conclusion
This paper presents an effective approach for adapting powerful image recognition models like CLIP and StepNet to the task of continuous sign language recognition. The researchers' detailed analysis of the data and architectural considerations provides valuable insights for others working to build more accurate and robust sign language recognition systems.
While the current approach has some limitations, the paper demonstrates the potential of leveraging state-of-the-art computer vision models to advance the field of sign language technology, ultimately improving accessibility and communication for the Deaf and hard-of-hearing community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
4/16/2024
💬
Sign2GPT: Leveraging Large Language Models for Gloss-Free Sign Language Translation
Ryan Wong, Necati Cihan Camgoz, Richard Bowden
0
0
Automatic Sign Language Translation requires the integration of both computer vision and natural language processing to effectively bridge the communication gap between sign and spoken languages. However, the deficiency in large-scale training data to support sign language translation means we need to leverage resources from spoken language. We introduce, Sign2GPT, a novel framework for sign language translation that utilizes large-scale pretrained vision and language models via lightweight adapters for gloss-free sign language translation. The lightweight adapters are crucial for sign language translation, due to the constraints imposed by limited dataset sizes and the computational requirements when training with long sign videos. We also propose a novel pretraining strategy that directs our encoder to learn sign representations from automatically extracted pseudo-glosses without requiring gloss order information or annotations. We evaluate our approach on two public benchmark sign language translation datasets, namely RWTH-PHOENIX-Weather 2014T and CSL-Daily, and improve on state-of-the-art gloss-free translation performance with a significant margin.
5/8/2024
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
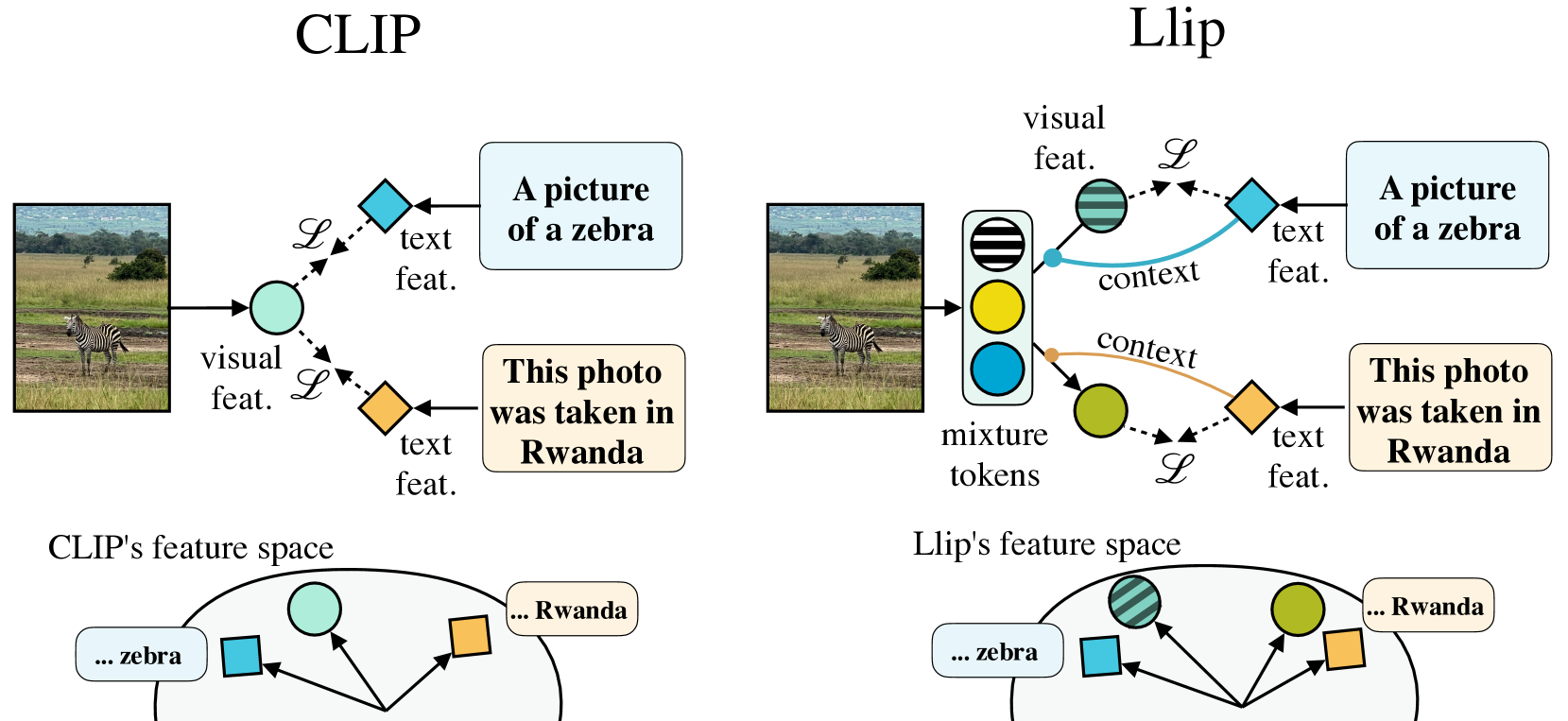
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, Jun Zhou
0
0
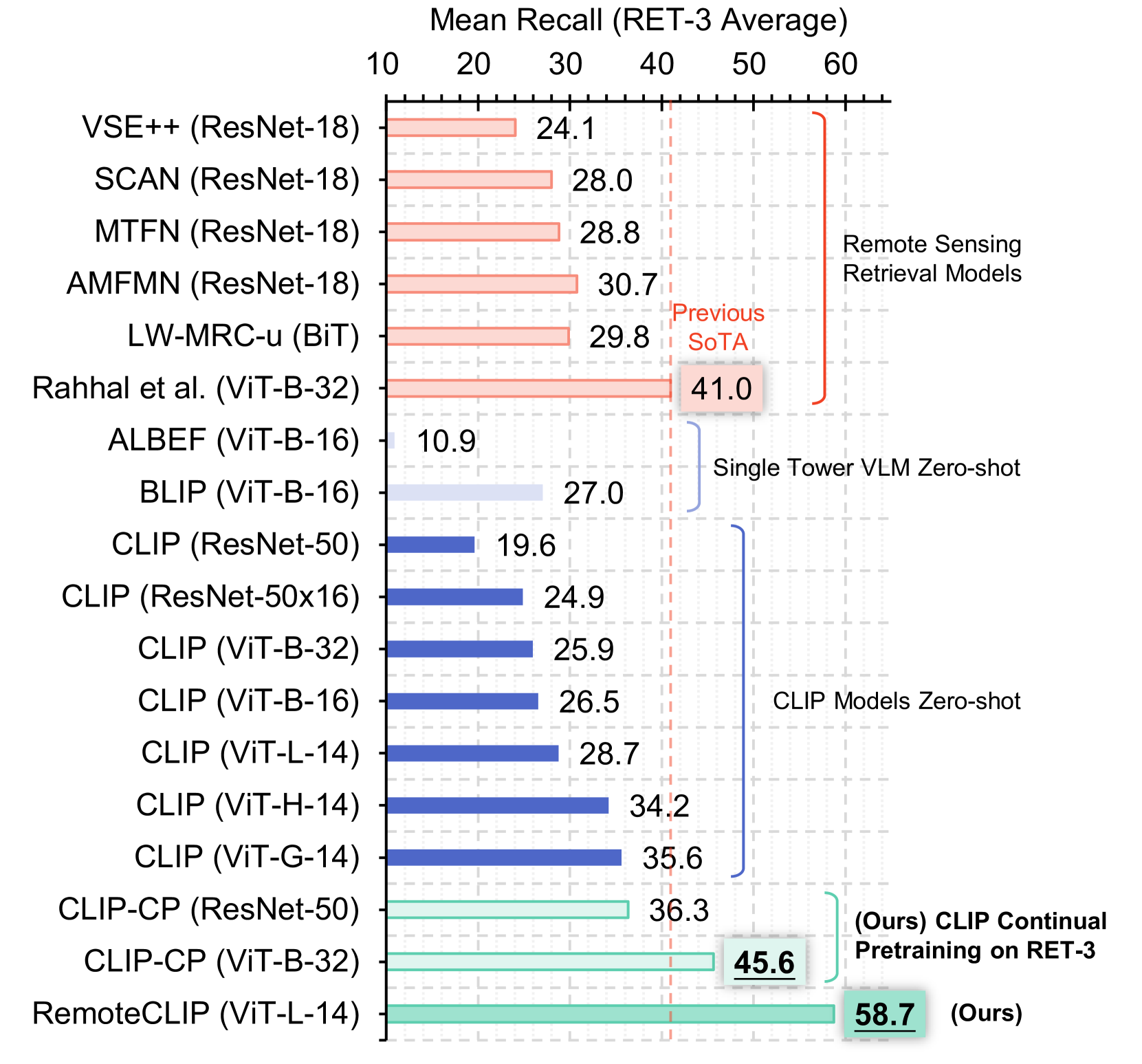
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $times$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $textit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
4/17/2024