E5-V: Universal Embeddings with Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper explores a new approach called E5-V for creating multimodal embeddings using large language models.
- Multimodal embeddings combine information from different modalities, such as text and images, to create more comprehensive representations.
- The E5-V approach leverages the capabilities of large language models like GPT-3 to generate these multimodal embeddings.
Plain English Explanation
E5-V: Multimodal Embedding with Large Language Models presents a novel way to combine information from different sources, like text and images, to create more complete and useful representations of data. This is known as creating "multimodal embeddings."
The key idea is to use powerful language models, like GPT-3, which have been trained on huge amounts of text data, to generate these multimodal embeddings. The language model can then leverage its deep understanding of language to make connections between the text and visual information.
For example, if you had an image of a dog and some text describing it, the E5-V approach could create a multimodal embedding that captures both the visual characteristics of the dog and the semantic information in the text. This could be useful for tasks like image classification, where the language model's knowledge helps improve the accuracy of the visual analysis.
The main benefit of this approach is that it allows you to get richer, more informative representations of data by combining multiple modalities, without needing to train an entirely new model from scratch. The existing large language models can be leveraged to do the heavy lifting.
Technical Explanation
The E5-V approach presented in this paper builds on the success of large language models like GPT-3 by using them as the foundation for generating multimodal embeddings.
The key steps are:
- Text Encoding: The language model is used to encode the text associated with an input, generating a text embedding.
- Visual Encoding: A separate visual encoder, such as a convolutional neural network, is used to generate an embedding from the input image.
- Multimodal Fusion: The text and visual embeddings are then combined, or "fused," using a learned transformation to create the final multimodal embedding.
This multimodal embedding can then be used for a variety of downstream tasks, such as image classification or retrieval, where the combined information from text and images can lead to better performance.
The paper describes experiments demonstrating the effectiveness of the E5-V approach on several benchmark datasets, showing improvements over previous multimodal embedding methods.
Critical Analysis
The E5-V approach presented in this paper offers a promising way to leverage the power of large language models for multimodal representation learning. By building on the rich contextual understanding captured by these models, the approach can create richer, more informative embeddings that combine information from text and visual sources.
However, the paper does not fully address some potential limitations and areas for further research. For example, the approach relies on a separate visual encoder, which may not fully exploit the language model's capabilities. Exploring ways to more tightly integrate the visual and language processing could lead to further improvements.
Additionally, the paper focuses on relatively simple benchmark tasks, and it's not clear how the E5-V approach would scale to more complex, real-world applications. Further research is needed to understand the limitations and potential challenges of applying this method in more diverse and demanding scenarios.
Overall, the E5-V paper presents an interesting and promising direction for multimodal representation learning, but there is still room for refinement and further exploration to unlock the full potential of this approach.
Conclusion
The E5-V paper introduces a novel method for creating multimodal embeddings by leveraging the power of large language models. This approach allows the rich contextual understanding captured by these models to be combined with visual information, resulting in more comprehensive representations that can benefit a variety of downstream tasks.
While the paper demonstrates the effectiveness of E5-V on benchmark datasets, there are still opportunities for further research to address potential limitations and explore the scalability of this approach in more complex, real-world scenarios. Nonetheless, the E5-V method represents an exciting development in the field of multimodal representation learning, with the potential to drive significant advancements in how we process and understand diverse types of data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
E5-V: Universal Embeddings with Multimodal Large Language Models
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, Fuzhen Zhuang
Multimodal large language models (MLLMs) have shown promising advancements in general visual and language understanding. However, the representation of multimodal information using MLLMs remains largely unexplored. In this work, we introduce a new framework, E5-V, designed to adapt MLLMs for achieving universal multimodal embeddings. Our findings highlight the significant potential of MLLMs in representing multimodal inputs compared to previous approaches. By leveraging MLLMs with prompts, E5-V effectively bridges the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. We propose a single modality training approach for E5-V, where the model is trained exclusively on text pairs. This method demonstrates significant improvements over traditional multimodal training on image-text pairs, while reducing training costs by approximately 95%. Additionally, this approach eliminates the need for costly multimodal training data collection. Extensive experiments across four types of tasks demonstrate the effectiveness of E5-V. As a universal multimodal model, E5-V not only achieves but often surpasses state-of-the-art performance in each task, despite being trained on a single modality.
Read more7/18/2024
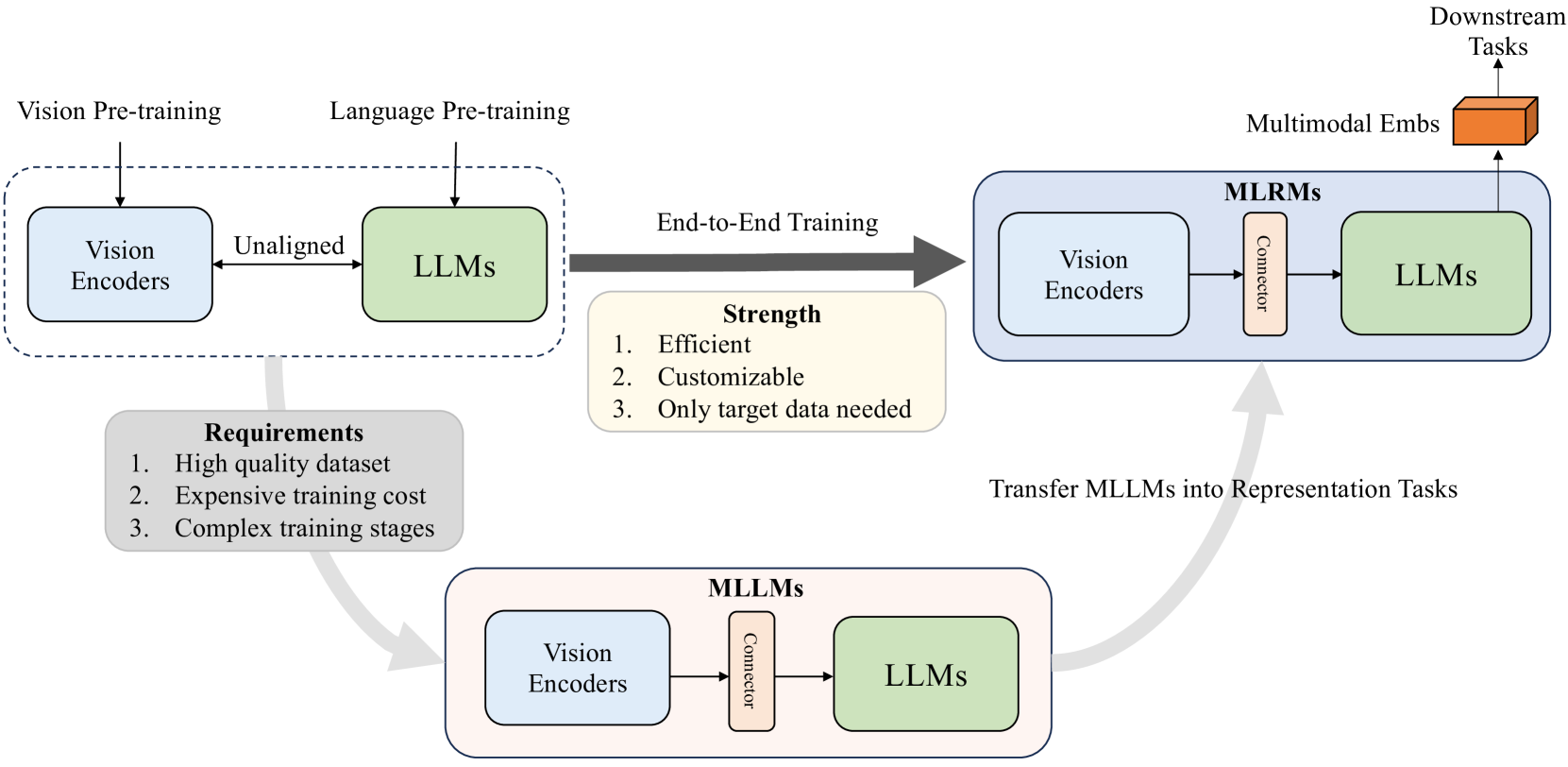
0
NoteLLM-2: Multimodal Large Representation Models for Recommendation
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Yan Gao, Yao Hu, Enhong Chen
Large Language Models (LLMs) have demonstrated exceptional text understanding. Existing works explore their application in text embedding tasks. However, there are few works utilizing LLMs to assist multimodal representation tasks. In this work, we investigate the potential of LLMs to enhance multimodal representation in multimodal item-to-item (I2I) recommendations. One feasible method is the transfer of Multimodal Large Language Models (MLLMs) for representation tasks. However, pre-training MLLMs usually requires collecting high-quality, web-scale multimodal data, resulting in complex training procedures and high costs. This leads the community to rely heavily on open-source MLLMs, hindering customized training for representation scenarios. Therefore, we aim to design an end-to-end training method that customizes the integration of any existing LLMs and vision encoders to construct efficient multimodal representation models. Preliminary experiments show that fine-tuned LLMs in this end-to-end method tend to overlook image content. To overcome this challenge, we propose a novel training framework, NoteLLM-2, specifically designed for multimodal representation. We propose two ways to enhance the focus on visual information. The first method is based on the prompt viewpoint, which separates multimodal content into visual content and textual content. NoteLLM-2 adopts the multimodal In-Content Learning method to teach LLMs to focus on both modalities and aggregate key information. The second method is from the model architecture, utilizing a late fusion mechanism to directly fuse visual information into textual information. Extensive experiments have been conducted to validate the effectiveness of our method.
Read more5/28/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024

0
UniMEL: A Unified Framework for Multimodal Entity Linking with Large Language Models
Liu Qi, He Yongyi, Lian Defu, Zheng Zhi, Xu Tong, Liu Che, Chen Enhong
Multimodal Entity Linking (MEL) is a crucial task that aims at linking ambiguous mentions within multimodal contexts to the referent entities in a multimodal knowledge base, such as Wikipedia. Existing methods focus heavily on using complex mechanisms and extensive model tuning methods to model the multimodal interaction on specific datasets. However, these methods overcomplicate the MEL task and overlook the visual semantic information, which makes them costly and hard to scale. Moreover, these methods can not solve the issues like textual ambiguity, redundancy, and noisy images, which severely degrade their performance. Fortunately, the advent of Large Language Models (LLMs) with robust capabilities in text understanding and reasoning, particularly Multimodal Large Language Models (MLLMs) that can process multimodal inputs, provides new insights into addressing this challenge. However, how to design a universally applicable LLMs-based MEL approach remains a pressing challenge. To this end, we propose UniMEL, a unified framework which establishes a new paradigm to process multimodal entity linking tasks using LLMs. In this framework, we employ LLMs to augment the representation of mentions and entities individually by integrating textual and visual information and refining textual information. Subsequently, we employ the embedding-based method for retrieving and re-ranking candidate entities. Then, with only ~0.26% of the model parameters fine-tuned, LLMs can make the final selection from the candidate entities. Extensive experiments on three public benchmark datasets demonstrate that our solution achieves state-of-the-art performance, and ablation studies verify the effectiveness of all modules. Our code is available at https://github.com/Javkonline/UniMEL.
Read more8/22/2024