Ecosystem-level Analysis of Deployed Machine Learning Reveals Homogeneous Outcomes

0

Sign in to get full access
Overview
- This paper presents an ecosystem-level analysis of deployed machine learning (ML) models, investigating the homogeneity of their outcomes across different applications and domains.
- The researchers examined a large-scale dataset of deployed ML models in production, aiming to understand the diversity (or lack thereof) in the real-world impacts of these models.
- The findings suggest that despite the increasing complexity and variety of ML models being developed, the outcomes they produce tend to be relatively homogeneous at the ecosystem level.
Plain English Explanation
The paper looks at how machine learning (ML) models are being used in the real world, across different applications and industries. The researchers gathered data on a large number of ML models that have been deployed and are actively being used, rather than just studying them in a lab setting.
The key finding is that even though there is a lot of diversity in the types of ML models being developed, the actual results and impacts of these models tend to be quite similar when you look at the big picture. In other words, the real-world outcomes of ML models are more homogeneous than you might expect.
The researchers wanted to understand why this is the case. Is it because the ML models themselves are becoming more standardized, or is it due to the way these models are being applied and integrated into different systems and workflows? The paper dives into these questions, providing insights into the ecosystem-level dynamics of deployed ML.
This research is important because it challenges the common perception that the growth of ML will lead to drastically different and unpredictable impacts across various domains. Instead, the findings suggest there may be some underlying patterns or trends in how ML is being used and deployed in practice.
Technical Explanation
The researchers analyzed a large dataset of real-world ML models that have been deployed in production environments, across a diverse range of applications and industries. They examined the inputs, architectures, and outputs of these models to assess the level of homogeneity or heterogeneity in the resulting outcomes.
The study used a combination of qualitative and quantitative methods to characterize the ecosystem of deployed ML models. This included analyzing the model architectures, the data sources and preprocessing steps, and the downstream tasks and applications. The researchers also looked at the performance metrics and overall impacts of the models.
The key finding was that despite the growing complexity and diversity of ML models being developed, the real-world outcomes tended to be relatively homogeneous. This suggests that there may be common patterns or constraints in how these models are being integrated and applied in practice, leading to more standardized results than one might expect.
The paper explores several potential drivers of this homogeneity, such as the influence of common datasets, the reuse of pre-trained model components, and the tendency for organizations to adopt similar best practices and guidelines when deploying ML systems. The researchers also discuss the implications of this finding for the future development and impact of ML technologies.
Critical Analysis
The paper provides a valuable ecosystem-level perspective on the real-world deployment of machine learning models, which is an important complement to the more common focus on individual model performance and architecture.
One limitation of the study is the reliance on a specific dataset of deployed ML models, which may not be fully representative of the broader landscape. The researchers acknowledge this and encourage further research to validate and extend the findings across a wider range of applications and domains.
Additionally, the paper does not delve deeply into the potential societal and ethical implications of the observed homogeneity in ML outcomes. As these models become more pervasive, it will be critical to understand how this lack of diversity may impact different populations and exacerbate existing biases or inequities.
Overall, this research raises important questions about the factors driving the standardization of ML impacts and the need for a more nuanced understanding of how these technologies are being integrated into real-world systems and workflows. Encouraging a broader, ecosystem-level perspective on ML development and deployment is a valuable contribution to the ongoing discussion around the responsible and equitable use of these powerful technologies.
Conclusion
This paper presents a novel ecosystem-level analysis of deployed machine learning models, revealing a surprising degree of homogeneity in the real-world outcomes of these technologies. The findings challenge the common perception of ML as a source of disruptive and unpredictable change, and instead suggest that there may be underlying patterns and constraints shaping the practical impacts of these models.
The research provides important insights into the dynamics of ML deployment, highlighting the need for a more holistic understanding of how these technologies are being integrated into various systems and workflows. As machine learning becomes increasingly ubiquitous, this work underscores the importance of considering the broader ecosystem-level effects, rather than focusing solely on individual model performance.
By shedding light on the homogeneity of ML outcomes, this paper lays the groundwork for further investigation into the drivers and implications of this phenomenon. Ultimately, this research contributes to the ongoing dialogue around the responsible development and deployment of machine learning, with the goal of ensuring these powerful technologies are leveraged in ways that promote diversity, equity, and positive societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ecosystem-level Analysis of Deployed Machine Learning Reveals Homogeneous Outcomes
Connor Toups, Rishi Bommasani, Kathleen A. Creel, Sarah H. Bana, Dan Jurafsky, Percy Liang
Machine learning is traditionally studied at the model level: researchers measure and improve the accuracy, robustness, bias, efficiency, and other dimensions of specific models. In practice, the societal impact of machine learning is determined by the surrounding context of machine learning deployments. To capture this, we introduce ecosystem-level analysis: rather than analyzing a single model, we consider the collection of models that are deployed in a given context. For example, ecosystem-level analysis in hiring recognizes that a job candidate's outcomes are not only determined by a single hiring algorithm or firm but instead by the collective decisions of all the firms they applied to. Across three modalities (text, images, speech) and 11 datasets, we establish a clear trend: deployed machine learning is prone to systemic failure, meaning some users are exclusively misclassified by all models available. Even when individual models improve at the population level over time, we find these improvements rarely reduce the prevalence of systemic failure. Instead, the benefits of these improvements predominantly accrue to individuals who are already correctly classified by other models. In light of these trends, we consider medical imaging for dermatology where the costs of systemic failure are especially high. While traditional analyses reveal racial performance disparities for both models and humans, ecosystem-level analysis reveals new forms of racial disparity in model predictions that do not present in human predictions. These examples demonstrate ecosystem-level analysis has unique strengths for characterizing the societal impact of machine learning.
Read more4/4/2024

0
A Large-Scale Study of Model Integration in ML-Enabled Software Systems
Yorick Sens, Henriette Knopp, Sven Peldszus, Thorsten Berger
The rise of machine learning (ML) and its embedding in systems has drastically changed the engineering of software-intensive systems. Traditionally, software engineering focuses on manually created artifacts such as source code and the process of creating them, as well as best practices for integrating them, i.e., software architectures. In contrast, the development of ML artifacts, i.e. ML models, comes from data science and focuses on the ML models and their training data. However, to deliver value to end users, these ML models must be embedded in traditional software, often forming complex topologies. In fact, ML-enabled software can easily incorporate many different ML models. While the challenges and practices of building ML-enabled systems have been studied to some extent, beyond isolated examples, little is known about the characteristics of real-world ML-enabled systems. Properly embedding ML models in systems so that they can be easily maintained or reused is far from trivial. We need to improve our empirical understanding of such systems, which we address by presenting the first large-scale study of real ML-enabled software systems, covering over 2,928 open source systems on GitHub. We classified and analyzed them to determine their characteristics, as well as their practices for reusing ML models and related code, and the architecture of these systems. Our findings provide practitioners and researchers with insight into practices for embedding and integrating ML models, bringing data science and software engineering closer together.
Read more8/13/2024

0
Deep learning-based ecological analysis of camera trap images is impacted by training data quality and size
Omiros Pantazis, Peggy Bevan, Holly Pringle, Guilherme Braga Ferreira, Daniel J. Ingram, Emily Madsen, Liam Thomas, Dol Raj Thanet, Thakur Silwal, Santosh Rayamajhi, Gabriel Brostow, Oisin Mac Aodha, Kate E. Jones
Large wildlife image collections from camera traps are crucial for biodiversity monitoring, offering insights into species richness, occupancy, and activity patterns. However, manual processing of these data is time-consuming, hindering analytical processes. To address this, deep neural networks have been widely adopted to automate image analysis. Despite their growing use, the impact of model training decisions on downstream ecological metrics remains unclear. Here, we analyse camera trap data from an African savannah and an Asian sub-tropical dry forest to compare key ecological metrics derived from expert-generated species identifications with those generated from deep neural networks. We assess the impact of model architecture, training data noise, and dataset size on ecological metrics, including species richness, occupancy, and activity patterns. Our results show that while model architecture has minimal impact, large amounts of noise and reduced dataset size significantly affect these metrics. Nonetheless, estimated ecological metrics are resilient to considerable noise, tolerating up to 10% error in species labels and a 50% reduction in training set size without changing significantly. We also highlight that conventional metrics like classification error may not always be representative of a model's ability to accurately measure ecological metrics. We conclude that ecological metrics derived from deep neural network predictions closely match those calculated from expert labels and remain robust to variations in the factors explored. However, training decisions for deep neural networks can impact downstream ecological analysis. Therefore, practitioners should prioritize creating large, clean training sets and evaluate deep neural network solutions based on their ability to measure the ecological metrics of interest.
Read more8/27/2024
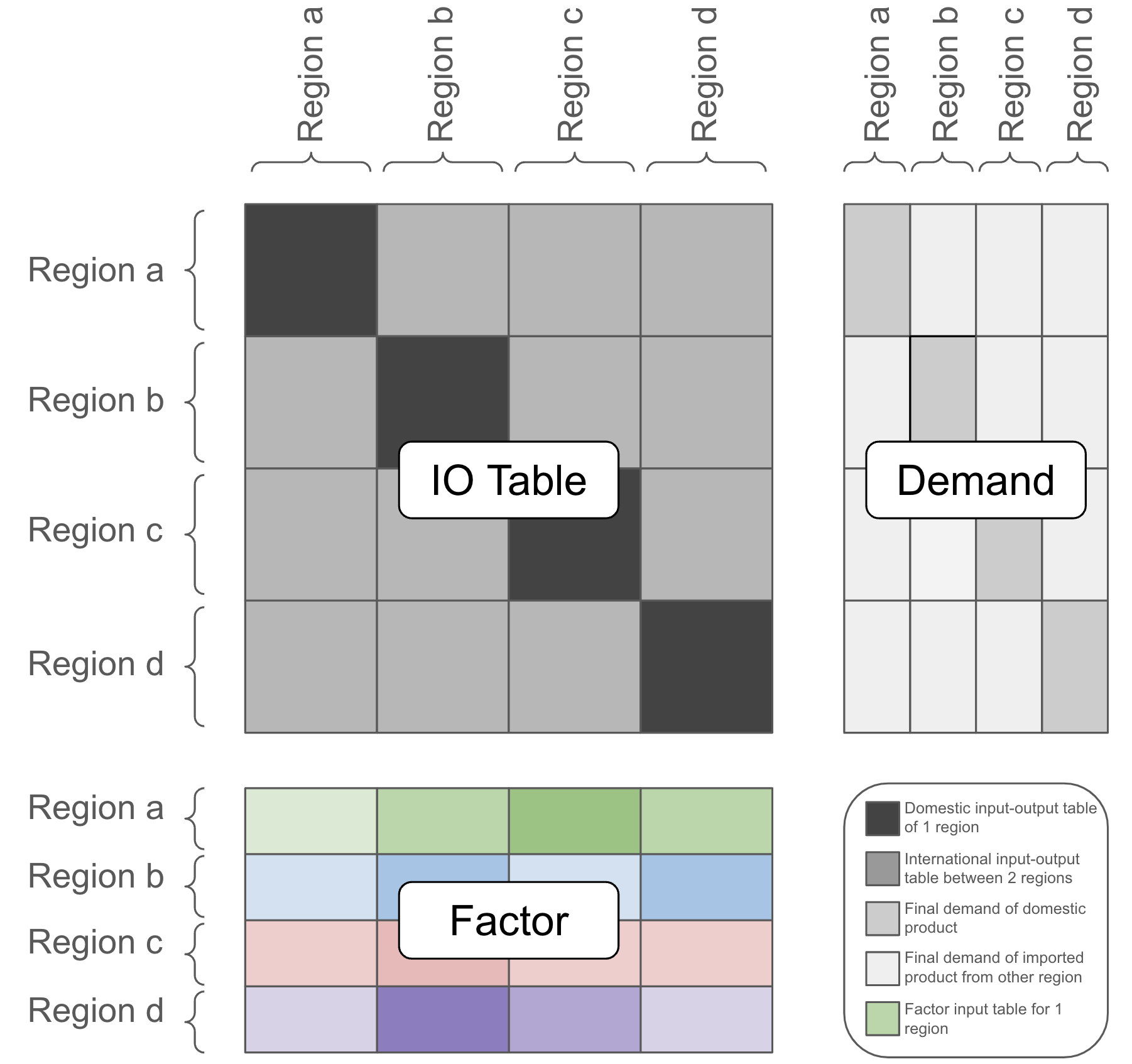
0
ExioML: Eco-economic dataset for Machine Learning in Global Sectoral Sustainability
Yanming Guo, Charles Guan, Jin Ma
The Environmental Extended Multi-Regional Input-Output analysis is the predominant framework in Ecological Economics for assessing the environmental impact of economic activities. This paper introduces ExioML, the first Machine Learning benchmark dataset designed for sustainability analysis, aimed at lowering barriers and fostering collaboration between Machine Learning and Ecological Economics research. A crucial greenhouse gas emission regression task was conducted to evaluate sectoral sustainability and demonstrate the usability of the dataset. We compared the performance of traditional shallow models with deep learning models, utilizing a diverse Factor Accounting table and incorporating various categorical and numerical features. Our findings reveal that ExioML, with its high usability, enables deep and ensemble models to achieve low mean square errors, establishing a baseline for future Machine Learning research. Through ExioML, we aim to build a foundational dataset supporting various Machine Learning applications and promote climate actions and sustainable investment decisions.
Read more7/9/2024