ExioML: Eco-economic dataset for Machine Learning in Global Sectoral Sustainability

0
Sign in to get full access
Overview
- The paper presents ExioML, an eco-economic dataset for machine learning in global sectoral sustainability.
- ExioML combines economic and environmental data from multiple sources to provide a comprehensive dataset for sustainability-focused machine learning research.
- The dataset covers a wide range of sectors and environmental indicators, making it a valuable resource for researchers and policymakers working on sustainability challenges.
Plain English Explanation
The ExioML paper introduces a new dataset called ExioML that combines economic and environmental data from various sources. This dataset is designed to support machine learning research on global sustainability issues.
Sustainability is a complex challenge that requires understanding the interconnections between economic activities and their environmental impacts. ExioML aims to provide researchers with a comprehensive dataset to explore these relationships using advanced machine learning techniques.
The dataset covers a broad range of economic sectors and includes information on things like carbon emissions, resource use, and other environmental indicators. By bringing together all this data in a standardized format, ExioML makes it easier for researchers to develop and test new machine learning models that can help policymakers and businesses make more informed decisions about sustainability.
For example, the dataset could be used to train models that predict the environmental impact of changes in economic activity or identify the most effective interventions for reducing a sector's environmental footprint. The researchers behind ExioML hope that making this valuable data available will accelerate progress in the field of sustainable machine learning.
Technical Explanation
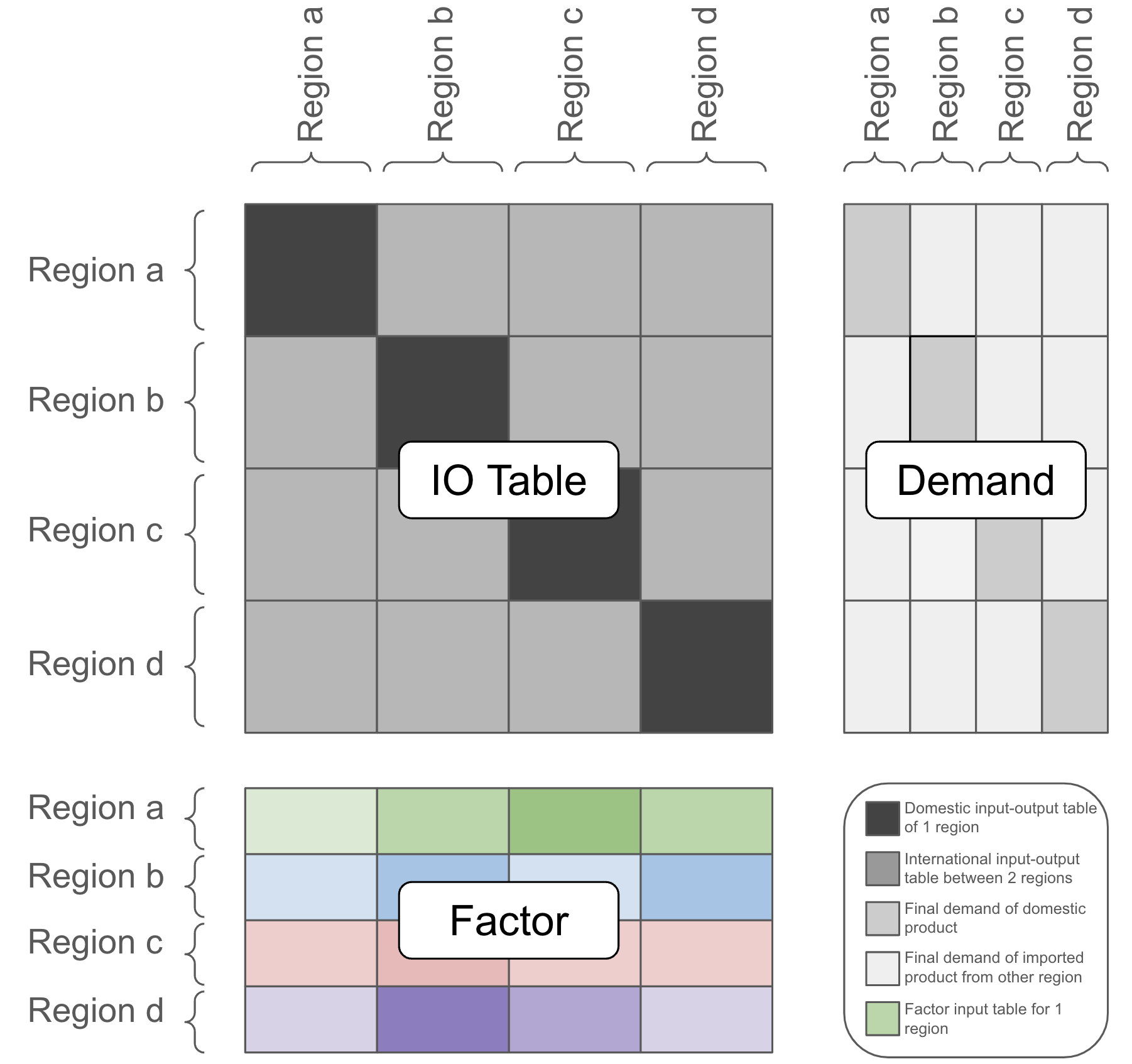
The ExioML paper introduces a new eco-economic dataset designed to support machine learning research on global sustainability challenges. The dataset combines data from multiple sources, including input-output tables, emissions inventories, and resource use statistics, to provide a comprehensive view of the environmental impacts associated with economic activities across different sectors.
The key features of the ExioML dataset include:
- Global coverage: The dataset includes data for multiple countries and regions, allowing researchers to study sustainability issues from a global perspective.
- Sectoral detail: The data is organized by economic sector, enabling researchers to analyze the environmental performance of specific industries.
- Environmental indicators: The dataset includes a wide range of environmental metrics, such as greenhouse gas emissions, water use, and land use, providing a multifaceted view of sustainability.
- Time series data: The dataset includes historical data, allowing researchers to investigate trends and changes over time.
The researchers who developed ExioML believe that this comprehensive dataset will enable more advanced machine learning models for sustainability research. By training models on the ExioML data, researchers can develop tools to predict the environmental impacts of economic activities, identify the most effective sustainability interventions, and inform policymaking and business decisions.
Critical Analysis
The ExioML dataset represents a significant advancement in the availability of eco-economic data for sustainability research. By bringing together data from multiple sources, the researchers have created a valuable resource for the research community.
However, the paper does acknowledge some limitations of the dataset. For example, the data may not be fully harmonized across all sources, and there may be gaps or inconsistencies in the coverage of certain countries or sectors. Additionally, the researchers note that the dataset does not include some emerging environmental indicators, such as biodiversity metrics, which could be important for a more holistic understanding of sustainability.
Further, while the dataset is designed to support machine learning research, the paper does not provide a detailed evaluation of the dataset's suitability for different machine learning tasks or the types of insights that can be derived from it. Researchers may need to carefully assess the dataset's capabilities and limitations in the context of their specific research questions and methods.
Despite these caveats, the ExioML dataset represents a significant step forward in the field of sustainable machine learning. As the research community continues to explore the intersection of environmental and economic systems, resources like ExioML will be essential for developing the data-driven tools and insights needed to address global sustainability challenges.
Conclusion
The ExioML dataset introduced in this paper provides a valuable resource for researchers and policymakers working on sustainability issues. By combining economic and environmental data from multiple sources, the dataset offers a comprehensive view of the eco-economic system, enabling the development of more advanced machine learning models for sustainability research.
The availability of this dataset has the potential to accelerate progress in sustainable machine learning, helping researchers and decision-makers better understand the complex relationships between economic activities and environmental impacts. As the world faces growing sustainability challenges, tools and insights derived from the ExioML dataset can contribute to the development of more effective policies and business strategies for a more sustainable future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ExioML: Eco-economic dataset for Machine Learning in Global Sectoral Sustainability
Yanming Guo, Charles Guan, Jin Ma
The Environmental Extended Multi-Regional Input-Output analysis is the predominant framework in Ecological Economics for assessing the environmental impact of economic activities. This paper introduces ExioML, the first Machine Learning benchmark dataset designed for sustainability analysis, aimed at lowering barriers and fostering collaboration between Machine Learning and Ecological Economics research. A crucial greenhouse gas emission regression task was conducted to evaluate sectoral sustainability and demonstrate the usability of the dataset. We compared the performance of traditional shallow models with deep learning models, utilizing a diverse Factor Accounting table and incorporating various categorical and numerical features. Our findings reveal that ExioML, with its high usability, enables deep and ensemble models to achieve low mean square errors, establishing a baseline for future Machine Learning research. Through ExioML, we aim to build a foundational dataset supporting various Machine Learning applications and promote climate actions and sustainable investment decisions.
Read more7/9/2024

0
DeepExtremeCubes: Integrating Earth system spatio-temporal data for impact assessment of climate extremes
Chaonan Ji, Tonio Fincke, Vitus Benson, Gustau Camps-Valls, Miguel-Angel Fernandez-Torres, Fabian Gans, Guido Kraemer, Francesco Martinuzzi, David Montero, Karin Mora, Oscar J. Pellicer-Valero, Claire Robin, Maximilian Soechting, Melanie Weynants, Miguel D. Mahecha
With climate extremes' rising frequency and intensity, robust analytical tools are crucial to predict their impacts on terrestrial ecosystems. Machine learning techniques show promise but require well-structured, high-quality, and curated analysis-ready datasets. Earth observation datasets comprehensively monitor ecosystem dynamics and responses to climatic extremes, yet the data complexity can challenge the effectiveness of machine learning models. Despite recent progress in deep learning to ecosystem monitoring, there is a need for datasets specifically designed to analyse compound heatwave and drought extreme impact. Here, we introduce the DeepExtremeCubes database, tailored to map around these extremes, focusing on persistent natural vegetation. It comprises over 40,000 spatially sampled small data cubes (i.e. minicubes) globally, with a spatial coverage of 2.5 by 2.5 km. Each minicube includes (i) Sentinel-2 L2A images, (ii) ERA5-Land variables and generated extreme event cube covering 2016 to 2022, and (iii) ancillary land cover and topography maps. The paper aims to (1) streamline data accessibility, structuring, pre-processing, and enhance scientific reproducibility, and (2) facilitate biosphere dynamics forecasting in response to compound extremes.
Read more6/27/2024

0
Ecosystem-level Analysis of Deployed Machine Learning Reveals Homogeneous Outcomes
Connor Toups, Rishi Bommasani, Kathleen A. Creel, Sarah H. Bana, Dan Jurafsky, Percy Liang
Machine learning is traditionally studied at the model level: researchers measure and improve the accuracy, robustness, bias, efficiency, and other dimensions of specific models. In practice, the societal impact of machine learning is determined by the surrounding context of machine learning deployments. To capture this, we introduce ecosystem-level analysis: rather than analyzing a single model, we consider the collection of models that are deployed in a given context. For example, ecosystem-level analysis in hiring recognizes that a job candidate's outcomes are not only determined by a single hiring algorithm or firm but instead by the collective decisions of all the firms they applied to. Across three modalities (text, images, speech) and 11 datasets, we establish a clear trend: deployed machine learning is prone to systemic failure, meaning some users are exclusively misclassified by all models available. Even when individual models improve at the population level over time, we find these improvements rarely reduce the prevalence of systemic failure. Instead, the benefits of these improvements predominantly accrue to individuals who are already correctly classified by other models. In light of these trends, we consider medical imaging for dermatology where the costs of systemic failure are especially high. While traditional analyses reveal racial performance disparities for both models and humans, ecosystem-level analysis reveals new forms of racial disparity in model predictions that do not present in human predictions. These examples demonstrate ecosystem-level analysis has unique strengths for characterizing the societal impact of machine learning.
Read more4/4/2024
0
LITE: Modeling Environmental Ecosystems with Multimodal Large Language Models
Haoran Li, Junqi Liu, Zexian Wang, Shiyuan Luo, Xiaowei Jia, Huaxiu Yao
The modeling of environmental ecosystems plays a pivotal role in the sustainable management of our planet. Accurate prediction of key environmental variables over space and time can aid in informed policy and decision-making, thus improving people's livelihood. Recently, deep learning-based methods have shown promise in modeling the spatial-temporal relationships for predicting environmental variables. However, these approaches often fall short in handling incomplete features and distribution shifts, which are commonly observed in environmental data due to the substantial cost of data collection and malfunctions in measuring instruments. To address these issues, we propose LITE -- a multimodal large language model for environmental ecosystems modeling. Specifically, LITE unifies different environmental variables by transforming them into natural language descriptions and line graph images. Then, LITE utilizes unified encoders to capture spatial-temporal dynamics and correlations in different modalities. During this step, the incomplete features are imputed by a sparse Mixture-of-Experts framework, and the distribution shift is handled by incorporating multi-granularity information from past observations. Finally, guided by domain instructions, a language model is employed to fuse the multimodal representations for the prediction. Our experiments demonstrate that LITE significantly enhances performance in environmental spatial-temporal prediction across different domains compared to the best baseline, with a 41.25% reduction in prediction error. This justifies its effectiveness. Our data and code are available at https://github.com/hrlics/LITE.
Read more8/13/2024