EcoVerse: An Annotated Twitter Dataset for Eco-Relevance Classification, Environmental Impact Analysis, and Stance Detection

0

Sign in to get full access
Overview
- Presents EcoVerse, a new annotated Twitter dataset for studying environmental-related content
- Enables research on eco-relevance classification, environmental impact analysis, and stance detection
- Provides a valuable resource for understanding public discourse and attitudes around environmental issues
Plain English Explanation
The paper introduces a new dataset called EcoVerse, which is a collection of tweets annotated with information related to the environment. This dataset can be used by researchers to build and test machine learning models for a few different tasks:
- Eco-relevance classification: Determining whether a tweet is relevant to environmental topics or not.
- Environmental impact analysis: Analyzing the potential environmental impact discussed in a tweet, such as pollution, energy usage, or sustainability.
- Stance detection: Identifying the stance or opinion expressed in a tweet towards environmental issues, such as whether it is supportive, critical, or neutral.
Having a large, high-quality dataset like EcoVerse is important because it allows researchers to better understand how people discuss environmental topics on social media. This can provide insights into public perceptions, concerns, and behaviors related to the environment. The dataset can be used to develop AI models that can automatically analyze social media content and track trends over time, which could be valuable for policymakers, activists, and others working on environmental issues.
Technical Explanation
The EcoVerse dataset was constructed by crawling Twitter for relevant environmental keywords and hashtags, and then having human annotators label the tweets along the three dimensions mentioned above: eco-relevance, environmental impact, and stance. The dataset contains over 100,000 tweets, making it a sizable resource for training and evaluating machine learning models.
The authors provide baseline results for each of the three tasks using standard text classification approaches like logistic regression and support vector machines. They find that the eco-relevance and stance detection tasks are relatively easier, with F1 scores around 0.8, while the environmental impact analysis is more challenging, with F1 scores around 0.6.
The paper also includes an analysis of the dataset, looking at trends in tweet volume, sentiment, and topics over time. This provides useful context for understanding the nature of environmental discourse on Twitter.
Critical Analysis
The EcoVerse dataset represents a valuable contribution to the field, as it enables new avenues of research on a important societal issue. However, the paper does not address some potential limitations or biases in the dataset. For example, it is unclear how representative the tweets are of the broader population, as Twitter users may not be fully reflective of the general public. There are also challenges in accurately labeling the complex and nuanced concepts of environmental impact and stance.
Additionally, while the baseline results provide a useful starting point, the performance of the models, especially for environmental impact analysis, suggests there is significant room for improvement. Exploring more advanced natural language processing and machine learning techniques could lead to better performance and more meaningful insights.
Conclusion
Overall, the EcoVerse dataset represents an important step forward in enabling research on environmental discourse on social media. The ability to automatically classify tweets based on eco-relevance, environmental impact, and stance could lead to a better understanding of public attitudes and behaviors, which could in turn inform policymaking and advocacy efforts around environmental issues. As the field continues to evolve, further refinements to the dataset and modeling approaches will be crucial to extracting maximum value from this resource.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EcoVerse: An Annotated Twitter Dataset for Eco-Relevance Classification, Environmental Impact Analysis, and Stance Detection
Francesca Grasso, Stefano Locci, Giovanni Siragusa, Luigi Di Caro
Anthropogenic ecological crisis constitutes a significant challenge that all within the academy must urgently face, including the Natural Language Processing (NLP) community. While recent years have seen increasing work revolving around climate-centric discourse, crucial environmental and ecological topics outside of climate change remain largely unaddressed, despite their prominent importance. Mainstream NLP tasks, such as sentiment analysis, dominate the scene, but there remains an untouched space in the literature involving the analysis of environmental impacts of certain events and practices. To address this gap, this paper presents EcoVerse, an annotated English Twitter dataset of 3,023 tweets spanning a wide spectrum of environmental topics. We propose a three-level annotation scheme designed for Eco-Relevance Classification, Stance Detection, and introducing an original approach for Environmental Impact Analysis. We detail the data collection, filtering, and labeling process that led to the creation of the dataset. Remarkable Inter-Annotator Agreement indicates that the annotation scheme produces consistent annotations of high quality. Subsequent classification experiments using BERT-based models, including ClimateBERT, are presented. These yield encouraging results, while also indicating room for a model specifically tailored for environmental texts. The dataset is made freely available to stimulate further research.
Read more4/9/2024

0
Automating the Analysis of Public Saliency and Attitudes towards Biodiversity from Digital Media
Noah Giebink, Amrita Gupta, Diogo Ver`issimo, Charlotte H. Chang, Tony Chang, Angela Brennan, Brett Dickson, Alex Bowmer, Jonathan Baillie
Measuring public attitudes toward wildlife provides crucial insights into our relationship with nature and helps monitor progress toward Global Biodiversity Framework targets. Yet, conducting such assessments at a global scale is challenging. Manually curating search terms for querying news and social media is tedious, costly, and can lead to biased results. Raw news and social media data returned from queries are often cluttered with irrelevant content and syndicated articles. We aim to overcome these challenges by leveraging modern Natural Language Processing (NLP) tools. We introduce a folk taxonomy approach for improved search term generation and employ cosine similarity on Term Frequency-Inverse Document Frequency vectors to filter syndicated articles. We also introduce an extensible relevance filtering pipeline which uses unsupervised learning to reveal common topics, followed by an open-source zero-shot Large Language Model (LLM) to assign topics to news article titles, which are then used to assign relevance. Finally, we conduct sentiment, topic, and volume analyses on resulting data. We illustrate our methodology with a case study of news and X (formerly Twitter) data before and during the COVID-19 pandemic for various mammal taxa, including bats, pangolins, elephants, and gorillas. During the data collection period, up to 62% of articles including keywords pertaining to bats were deemed irrelevant to biodiversity, underscoring the importance of relevance filtering. At the pandemic's onset, we observed increased volume and a significant sentiment shift toward horseshoe bats, which were implicated in the pandemic, but not for other focal taxa. The proposed methods open the door to conservation practitioners applying modern and emerging NLP tools, including LLMs out of the box, to analyze public perceptions of biodiversity during current events or campaigns.
Read more5/6/2024
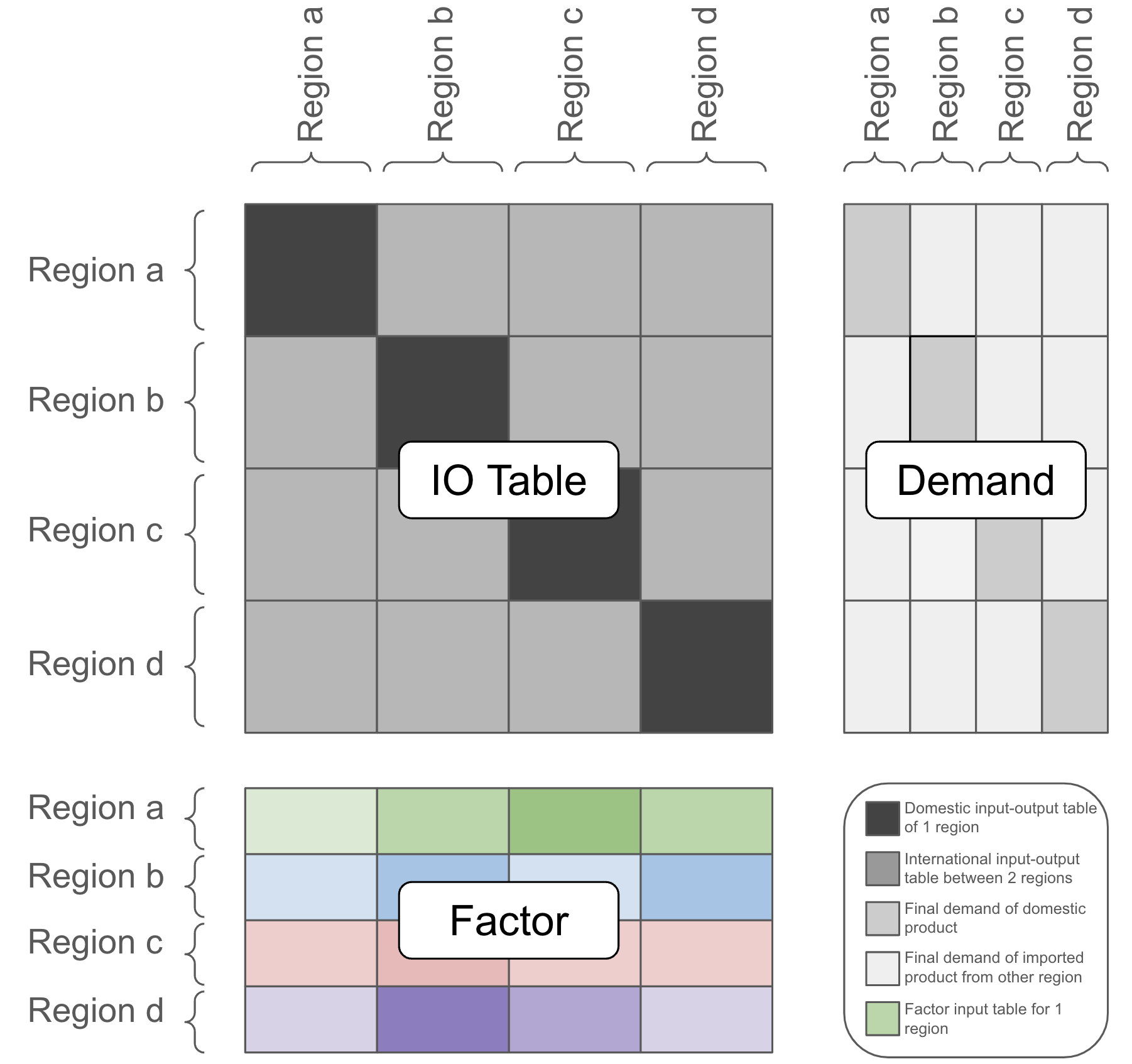
0
ExioML: Eco-economic dataset for Machine Learning in Global Sectoral Sustainability
Yanming Guo, Charles Guan, Jin Ma
The Environmental Extended Multi-Regional Input-Output analysis is the predominant framework in Ecological Economics for assessing the environmental impact of economic activities. This paper introduces ExioML, the first Machine Learning benchmark dataset designed for sustainability analysis, aimed at lowering barriers and fostering collaboration between Machine Learning and Ecological Economics research. A crucial greenhouse gas emission regression task was conducted to evaluate sectoral sustainability and demonstrate the usability of the dataset. We compared the performance of traditional shallow models with deep learning models, utilizing a diverse Factor Accounting table and incorporating various categorical and numerical features. Our findings reveal that ExioML, with its high usability, enables deep and ensemble models to achieve low mean square errors, establishing a baseline for future Machine Learning research. Through ExioML, we aim to build a foundational dataset supporting various Machine Learning applications and promote climate actions and sustainable investment decisions.
Read more7/9/2024
🔎
0
ESG-FTSE: A corpus of news articles with ESG relevance labels and use cases
Mariya Pavlova, Bernard Casey, Miaosen Wang
We present ESG-FTSE, the first corpus comprised of news articles with Environmental, Social and Governance (ESG) relevance annotations. In recent years, investors and regulators have pushed ESG investing to the mainstream due to the urgency of climate change. This has led to the rise of ESG scores to evaluate an investment's credentials as socially responsible. While demand for ESG scores is high, their quality varies wildly. Quantitative techniques can be applied to improve ESG scores, thus, responsible investing. To contribute to resource building for ESG and financial text mining, we pioneer the ESG-FTSE corpus. We further present the first of its kind ESG annotation schema. It has three levels: a binary classification (relevant versus irrelevant news articles), ESG classification (ESG-related news articles), and target company. Both supervised and unsupervised learning experiments for ESG relevance detection were conducted to demonstrate that the corpus can be used in different settings to derive accurate ESG predictions. Keywords: corpus annotation, ESG labels, annotation schema, news article, natural language processing
Read more5/31/2024