Edge AI as a Service with Coordinated Deep Neural Networks

0

Sign in to get full access
Overview
- This paper presents a novel approach called Coordinated Deep Neural Networks (CDNN) for efficient edge offloading of deep neural network (DNN) inference tasks.
- CDNN leverages multi-task DNNs to enable coordinated computation offloading between edge devices and cloud servers, optimizing for low latency and high accuracy.
- The authors demonstrate the effectiveness of CDNN through extensive simulations and real-world experiments.
Plain English Explanation
The research paper introduces a new technique called Coordinated Deep Neural Networks (CDNN) that aims to improve the efficiency of running deep learning models on edge devices, such as smartphones or Internet of Things (IoT) gadgets.
The key idea behind CDNN is to leverage multi-task deep neural networks - a single DNN model that can perform multiple related tasks. This allows the system to offload computationally intensive parts of the inference process to more powerful cloud servers, while still keeping latency-sensitive tasks running on the edge device.
The offloading decisions are coordinated between the edge device and the cloud, optimizing for both low latency and high accuracy. This is important because edge devices often have limited compute power, while cloud servers have more resources but higher network latency.
By using this coordinated approach, CDNN can adaptively split the DNN inference workload between the edge and the cloud, depending on the specific task and the available resources. This helps to improve the overall performance and efficiency of the system.
The authors of the paper demonstrate the effectiveness of CDNN through extensive simulations and real-world experiments, showing that it can outperform traditional edge offloading approaches in terms of latency, accuracy, and energy efficiency.
Technical Explanation
The core idea behind Coordinated Deep Neural Networks (CDNN) is to leverage multi-task deep neural networks to enable efficient edge offloading of DNN inference tasks.
In a multi-task DNN, a single model is trained to perform multiple related tasks. CDNN exploits this property to split the DNN inference workload between the edge device and the cloud server. The edge device runs the latency-sensitive tasks, while the computationally intensive tasks are offloaded to the cloud.
The offloading decisions are coordinated between the edge and the cloud, taking into account factors such as task complexity, available resources, and network conditions. This coordination is crucial to optimize for both low latency and high accuracy, as edge devices often have limited compute power, while cloud servers have higher network latency.
CDNN uses an adaptive offloading mechanism that dynamically adjusts the offloading decisions based on the current system state. This allows the system to adapt to changes in the environment and optimize its performance.
The authors evaluate CDNN through extensive simulations and real-world experiments, comparing it to traditional edge offloading approaches. The results demonstrate that CDNN can significantly improve the latency, accuracy, and energy efficiency of the system, making it a promising approach for enabling efficient edge AI in a variety of applications.
Critical Analysis
The paper presents a comprehensive evaluation of the CDNN approach, including both simulation-based and real-world experiments. The authors have carefully designed their experiments to assess the performance of CDNN under various conditions, such as different task complexities, network latencies, and resource constraints.
One potential limitation of the CDNN approach is the complexity of the coordination mechanism between the edge and the cloud. The authors acknowledge that this coordination might introduce additional overhead and require careful system design. Further research could explore ways to simplify the coordination process or make it more scalable.
Additionally, the paper does not address the security and privacy implications of offloading sensitive data to the cloud. This is an important consideration, especially in applications where the data might be confidential or personal.
Overall, the CDNN approach represents a promising step towards efficient edge AI and opens up new avenues for research in this area. The authors have demonstrated the potential of coordinated deep neural networks and laid the groundwork for further developments and improvements in this field.
Conclusion
The paper introduces a novel approach called Coordinated Deep Neural Networks (CDNN) that leverages multi-task deep neural networks to enable efficient edge offloading of DNN inference tasks. CDNN coordinates the offloading decisions between the edge device and the cloud server, optimizing for both low latency and high accuracy.
The authors have conducted a thorough evaluation of CDNN through simulations and real-world experiments, demonstrating its effectiveness in improving the overall performance and efficiency of edge AI systems. While the coordination mechanism might introduce additional complexity, the CDNN approach represents a promising step towards enabling efficient and robust edge AI in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Edge AI as a Service with Coordinated Deep Neural Networks
Alireza Maleki, Hamed Shah-Mansouri, Babak H. Khalaj
As artificial intelligence (AI) applications continue to expand in next-generation networks, there is a growing need for deep neural network (DNN) models. Although DNN models deployed at the edge are promising for providing AI as a service with low latency, their cooperation is yet to be explored. In this paper, we consider that DNN service providers share their computing resources as well as their models' parameters and allow other DNNs to offload their computations without mirroring. We propose a novel algorithm called coordinated DNNs on edge (textbf{CoDE}) that facilitates coordination among DNN services by establishing new inference paths. CoDE aims to find the optimal path, which is the path with the highest possible reward, by creating multi-task DNNs from individual models. The reward reflects the inference throughput and model accuracy. With CoDE, DNN models can make new paths for inference by using their own or other models' parameters. We then evaluate the performance of CoDE through numerical experiments. The results demonstrate a $40%$ increase in the inference throughput while degrading the average accuracy by only $2.3%$. Experiments show that CoDE enhances the inference throughput and, achieves higher precision compared to a state-of-the-art existing method.
Read more8/22/2024

0
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Ao Zhou, Jianlei Yang, Tong Qiao, Yingjie Qi, Zhi Yang, Weisheng Zhao, Chunming Hu
The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9times$ speedup and $98.2%$ energy reduction compared to existing approaches across various applications and system configurations.
Read more4/9/2024

0
Adaptive Device-Edge Collaboration on DNN Inference in AIoT: A Digital Twin-Assisted Approach
Shisheng Hu, Mushu Li, Jie Gao, Conghao Zhou, Xuemin Shen
Device-edge collaboration on deep neural network (DNN) inference is a promising approach to efficiently utilizing network resources for supporting artificial intelligence of things (AIoT) applications. In this paper, we propose a novel digital twin (DT)-assisted approach to device-edge collaboration on DNN inference that determines whether and when to stop local inference at a device and upload the intermediate results to complete the inference on an edge server. Instead of determining the collaboration for each DNN inference task only upon its generation, multi-step decision-making is performed during the on-device inference to adapt to the dynamic computing workload status at the device and the edge server. To enhance the adaptivity, a DT is constructed to evaluate all potential offloading decisions for each DNN inference task, which provides augmented training data for a machine learning-assisted decision-making algorithm. Then, another DT is constructed to estimate the inference status at the device to avoid frequently fetching the status information from the device, thus reducing the signaling overhead. We also derive necessary conditions for optimal offloading decisions to reduce the offloading decision space. Simulation results demon-strate the outstanding performance of our DT-assisted approach in terms of balancing the tradeoff among inference accuracy, delay, and energy consumption.
Read more5/29/2024
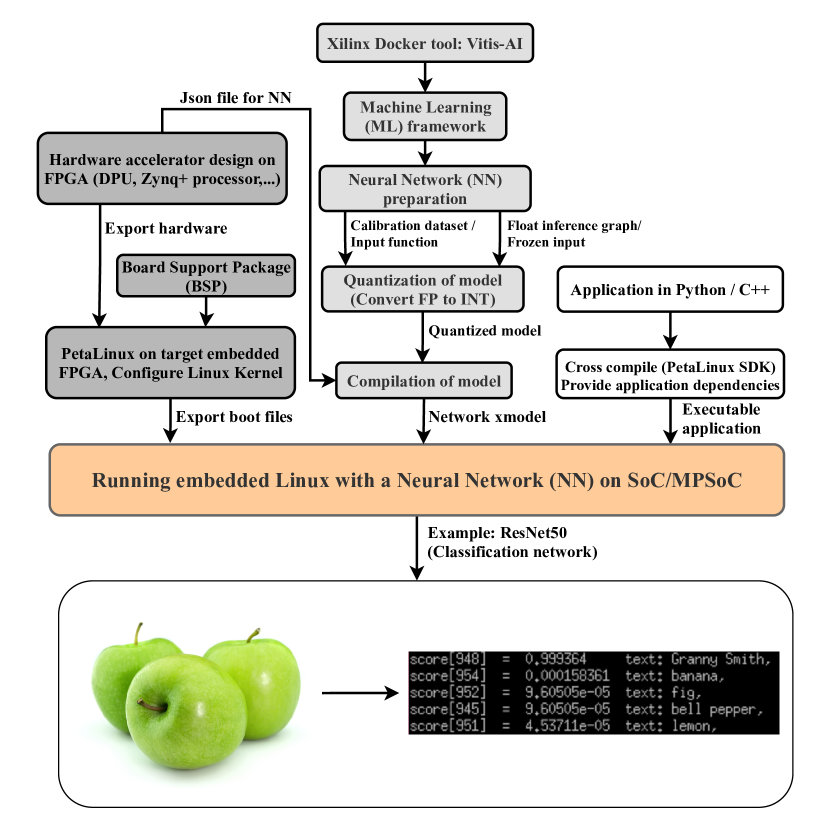
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024