EdgeNAT: Transformer for Efficient Edge Detection

0

Sign in to get full access
Overview
- EdgeNAT is a novel transformer-based model for efficient edge detection.
- The paper introduces a lightweight and effective architecture that outperforms existing edge detection methods.
- Key contributions include a novel transformer-based encoder-decoder design and efficient attention mechanisms.
Plain English Explanation
The paper presents EdgeNAT, a new approach to edge detection using transformer models. Edge detection is an important task in computer vision that involves identifying the boundaries or edges in an image. This is a fundamental step for many higher-level vision tasks like object recognition, scene understanding, and image segmentation.
Existing edge detection methods often rely on convolutional neural networks (CNNs), which can be computationally expensive and struggle with capturing long-range dependencies. EdgeNAT introduces a more efficient transformer-based architecture that is able to effectively model these long-range interactions.
The key idea is to use a transformer-based encoder-decoder design, where the encoder learns powerful visual representations and the decoder efficiently generates the final edge map. The model also incorporates several innovative attention mechanisms to further improve performance and efficiency.
Overall, EdgeNAT is shown to outperform state-of-the-art edge detection methods in terms of both accuracy and inference speed, making it a promising approach for real-world applications that require fast and reliable edge detection.
Technical Explanation
The EdgeNAT model consists of a transformer-based encoder-decoder architecture. The encoder takes an input image and learns rich visual representations using a series of transformer blocks. This allows the model to effectively capture long-range dependencies, which is crucial for accurate edge detection.
The decoder then takes these high-level features and progressively refines them to generate the final edge map. A key innovation is the use of several specialized attention mechanisms within the transformer blocks. This includes:
- Spatial Attention: This guides the model to focus on spatial regions that are more relevant for edge detection.
- Channel Attention: This helps the model selectively emphasize informative feature channels.
- Positional Attention: This allows the model to better incorporate positional information, which is important for accurately locating edges.
These attention mechanisms work together to make the overall architecture more efficient and effective for the edge detection task.
The paper also introduces several other design choices, such as a lightweight token mixer and an efficient decoder structure, which further contribute to the model's strong performance.
Critical Analysis
The paper provides a thorough evaluation of EdgeNAT, demonstrating its superiority over a range of existing edge detection methods on several benchmark datasets. The authors also discuss potential limitations and future research directions.
One caveat is that the model's performance may be sensitive to the specific dataset and task at hand. While it excels on the tested benchmarks, its generalization to other edge detection scenarios remains to be seen.
Additionally, the authors do not provide extensive analysis on the computational and memory efficiency of EdgeNAT compared to other transformer-based models. This information would be valuable for understanding the practical implications of the proposed approach.
Further research could also explore ways to make the model even more efficient, such as through model compression or knowledge distillation techniques. Investigating the interpretability of the learned attention mechanisms could also yield interesting insights.
Conclusion
The EdgeNAT paper presents a novel transformer-based approach for efficient edge detection. By leveraging a carefully designed encoder-decoder architecture and specialized attention mechanisms, the model is able to outperform state-of-the-art methods in terms of both accuracy and inference speed.
This work demonstrates the potential of transformers for low-level computer vision tasks, which have traditionally been dominated by convolutional neural networks. The insights and techniques developed in this paper could inspire further research into applying transformers to a wider range of vision problems, with the goal of creating more powerful and efficient models.
Overall, EdgeNAT represents an important step forward in the field of edge detection and has the potential to significantly impact applications that rely on fast and accurate edge extraction, such as autonomous driving, medical image analysis, and augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EdgeNAT: Transformer for Efficient Edge Detection
Jinghuai Jie, Yan Guo, Guixing Wu, Junmin Wu, Baojian Hua
Transformers, renowned for their powerful feature extraction capabilities, have played an increasingly prominent role in various vision tasks. Especially, recent advancements present transformer with hierarchical structures such as Dilated Neighborhood Attention Transformer (DiNAT), demonstrating outstanding ability to efficiently capture both global and local features. However, transformers' application in edge detection has not been fully exploited. In this paper, we propose EdgeNAT, a one-stage transformer-based edge detector with DiNAT as the encoder, capable of extracting object boundaries and meaningful edges both accurately and efficiently. On the one hand, EdgeNAT captures global contextual information and detailed local cues with DiNAT, on the other hand, it enhances feature representation with a novel SCAF-MLA decoder by utilizing both inter-spatial and inter-channel relationships of feature maps. Extensive experiments on multiple datasets show that our method achieves state-of-the-art performance on both RGB and depth images. Notably, on the widely used BSDS500 dataset, our L model achieves impressive performances, with ODS F-measure and OIS F-measure of 86.0%, 87.6% for multi-scale input,and 84.9%, and 86.3% for single-scale input, surpassing the current state-of-the-art EDTER by 1.2%, 1.1%, 1.7%, and 1.6%, respectively. Moreover, as for throughput, our approach runs at 20.87 FPS on RTX 4090 GPU with single-scale input. The code for our method will be released soon.
Read more8/21/2024
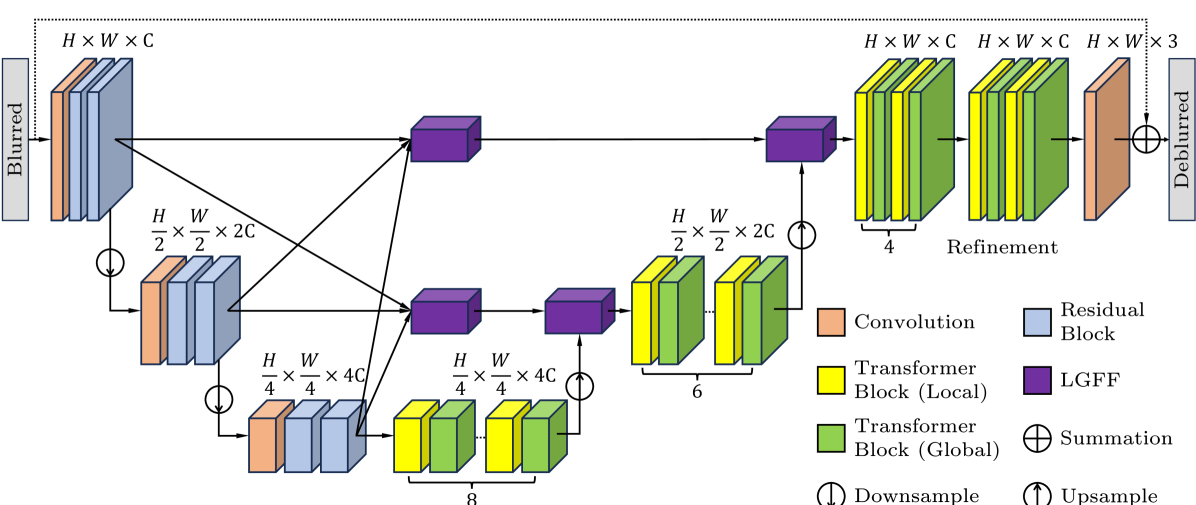
0
DeblurDiNAT: A Lightweight and Effective Transformer for Image Deblurring
Hanzhou Liu, Binghan Li, Chengkai Liu, Mi Lu
Although prior state-of-the-art (SOTA) deblurring networks achieve high metric scores on synthetic datasets, there are two challenges which prevent them from perceptual image deblurring. First, a deblurring model overtrained on synthetic datasets may collapse in a broad range of unseen real-world scenarios. Second, the conventional metrics PSNR and SSIM may not correctly reflect the perceptual quality observed by human eyes. To this end, we propose DeblurDiNAT, a generalizable and efficient encoder-decoder Transformer which restores clean images visually close to the ground truth. We adopt an alternating dilation factor structure to capture local and global blur patterns. We propose a local cross-channel learner to assist self-attention layers to learn short-range cross-channel relationships. In addition, we present a linear feed-forward network and a non-linear dual-stage feature fusion module for faster feature propagation across the network. Compared to nearest competitors, our model demonstrates the strongest generalization ability and achieves the best perceptual quality on mainstream image deblurring datasets with 3%-68% fewer parameters.
Read more7/12/2024

0
Revisiting Non-Autoregressive Transformers for Efficient Image Synthesis
Zanlin Ni, Yulin Wang, Renping Zhou, Jiayi Guo, Jinyi Hu, Zhiyuan Liu, Shiji Song, Yuan Yao, Gao Huang
The field of image synthesis is currently flourishing due to the advancements in diffusion models. While diffusion models have been successful, their computational intensity has prompted the pursuit of more efficient alternatives. As a representative work, non-autoregressive Transformers (NATs) have been recognized for their rapid generation. However, a major drawback of these models is their inferior performance compared to diffusion models. In this paper, we aim to re-evaluate the full potential of NATs by revisiting the design of their training and inference strategies. Specifically, we identify the complexities in properly configuring these strategies and indicate the possible sub-optimality in existing heuristic-driven designs. Recognizing this, we propose to go beyond existing methods by directly solving the optimal strategies in an automatic framework. The resulting method, named AutoNAT, advances the performance boundaries of NATs notably, and is able to perform comparably with the latest diffusion models at a significantly reduced inference cost. The effectiveness of AutoNAT is validated on four benchmark datasets, i.e., ImageNet-256 & 512, MS-COCO, and CC3M. Our code is available at https://github.com/LeapLabTHU/ImprovedNAT.
Read more6/11/2024
✨
0
WiTUnet: A U-Shaped Architecture Integrating CNN and Transformer for Improved Feature Alignment and Local Information Fusion
Bin Wang, Fei Deng, Peifan Jiang, Shuang Wang, Xiao Han, Zhixuan Zhang
Low-dose computed tomography (LDCT) has become the technology of choice for diagnostic medical imaging, given its lower radiation dose compared to standard CT, despite increasing image noise and potentially affecting diagnostic accuracy. To address this, advanced deep learning-based LDCT denoising algorithms have been developed, primarily using Convolutional Neural Networks (CNNs) or Transformer Networks with the Unet architecture. This architecture enhances image detail by integrating feature maps from the encoder and decoder via skip connections. However, current methods often overlook enhancements to the Unet architecture itself, focusing instead on optimizing encoder and decoder structures. This approach can be problematic due to the significant differences in feature map characteristics between the encoder and decoder, where simple fusion strategies may not effectively reconstruct images.In this paper, we introduce WiTUnet, a novel LDCT image denoising method that utilizes nested, dense skip pathways instead of traditional skip connections to improve feature integration. WiTUnet also incorporates a windowed Transformer structure to process images in smaller, non-overlapping segments, reducing computational load. Additionally, the integration of a Local Image Perception Enhancement (LiPe) module in both the encoder and decoder replaces the standard multi-layer perceptron (MLP) in Transformers, enhancing local feature capture and representation. Through extensive experimental comparisons, WiTUnet has demonstrated superior performance over existing methods in key metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), and Root Mean Square Error (RMSE), significantly improving noise removal and image quality.
Read more4/30/2024