EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
2404.01647
0
0

Abstract
Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new method called EDTalk for efficiently disentangling and synthesizing emotional talking head videos.
- The key idea is to separate the facial expression, head pose, and speech features into distinct latent representations, allowing for more natural and expressive talking head animation.
- The authors demonstrate that EDTalk outperforms previous state-of-the-art methods on several benchmarks, producing more realistic and emotion-rich talking heads.
Plain English Explanation
Imagine you're watching a video of someone speaking, but their facial expressions and head movements don't quite match what they're saying. It can look a bit unnatural or robotic. The goal of this research is to create more lifelike and emotionally expressive talking head animations.
The core innovation is to break down the different elements that go into a talking head - things like the person's facial expressions, the way their head is moving, and the actual speech. By separating these components into distinct representations, the researchers can recombine them in more natural and compelling ways.
For example, the system might take the neutral facial expression from one person, combine it with the head movements of someone else, and then add the emotional tone from a third person's speech. This allows for a lot more flexibility and nuance compared to previous approaches that tried to model the whole talking head as a single unit.
The end result is an animated talking head that feels more lifelike and emotionally expressive, which could have applications in areas like virtual assistants, video games, and filmmaking.
Technical Explanation
The EDTalk model takes in a source video of a person speaking and disentangles it into three separate latent representations: facial expression, head pose, and speech features. These representations are then recombined with a target video to generate a new talking head animation.
The key innovation is in the neural network architecture, which uses a series of encoders and decoders to efficiently extract and recombine these distinct factors. For example, the facial expression encoder learns to capture the dynamic changes in facial landmarks, while the head pose encoder focuses on head orientation and movement.
Through extensive experiments on benchmark datasets, the authors demonstrate that EDTalk outperforms previous state-of-the-art methods in terms of both objective metrics (e.g. landmark reconstruction error) and human evaluation of realism and emotional expressiveness.
Critical Analysis
The paper provides a thorough technical evaluation of the EDTalk system, including comparisons to several baselines and ablation studies to understand the contributions of each component. However, the authors acknowledge some limitations, such as the need for further improvements in lip synchronization and handling of fast head motions.
Additionally, while the results are impressive, the dataset sizes and diversity of emotional expressions may limit the broader applicability of the system. More research is needed to understand how well EDTalk would generalize to real-world scenarios with a wider range of speakers and emotional states.
Another potential concern is the ethical implications of increasingly realistic and emotional talking head synthesis. As this technology becomes more advanced, there will be important questions around its use, potential misuse, and impact on society that warrant further discussion.
Conclusion
Overall, the EDTalk system represents a significant advance in the field of talking head synthesis, demonstrating the power of disentangling the underlying factors that contribute to expressive facial animation. By separating facial expression, head pose, and speech features, the system can generate more natural and emotionally compelling talking head videos.
This research has the potential to enable more immersive and engaging virtual experiences, from virtual assistants to cinematic visual effects. However, as the technology continues to evolve, it will be crucial to carefully consider the ethical implications and ensure that it is developed and deployed responsibly.
Related Papers
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024

Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
0
0
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
4/1/2024
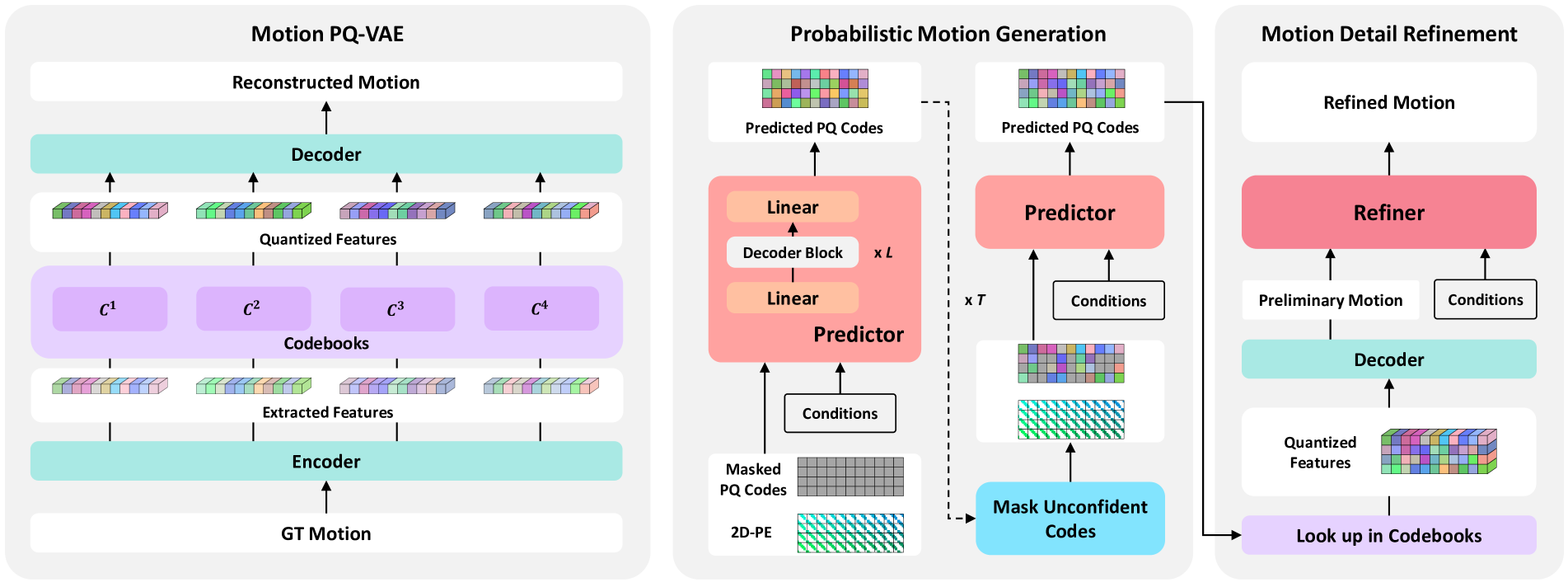
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
0
0
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
4/16/2024
🤿
AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, Kai Yu
0
0
The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
5/7/2024