AniTalker: Animate Vivid and Diverse Talking Faces through Identity-Decoupled Facial Motion Encoding
2405.03121
0
0
🤿
Abstract
The paper introduces AniTalker, an innovative framework designed to generate lifelike talking faces from a single portrait. Unlike existing models that primarily focus on verbal cues such as lip synchronization and fail to capture the complex dynamics of facial expressions and nonverbal cues, AniTalker employs a universal motion representation. This innovative representation effectively captures a wide range of facial dynamics, including subtle expressions and head movements. AniTalker enhances motion depiction through two self-supervised learning strategies: the first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations, and the second develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This approach ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data. Additionally, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This method not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also underscores its potential in crafting dynamic avatars for real-world applications. Synthetic results can be viewed at https://github.com/X-LANCE/AniTalker.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- AniTalker is a new framework that can generate lifelike talking faces from a single portrait image.
- Unlike existing models that focus mainly on lip synchronization, AniTalker captures a wider range of facial dynamics, including subtle expressions and head movements.
- AniTalker uses a universal motion representation and self-supervised learning strategies to effectively depict facial animations without relying heavily on labeled data.
- The integration of a diffusion model and a variance adapter allows for diverse and controllable facial animations to be generated.
Plain English Explanation
AniTalker is an innovative system that can bring portraits to life by generating realistic animated faces. Unlike other approaches that mainly focus on making sure the lips match the speech, AniTalker is able to capture a much broader range of facial movements, including small expressions and head motions. This is accomplished through a novel way of representing facial motion that is not tied to the specific identity of the person.
AniTalker learns this universal motion representation in a self-supervised way, meaning it can learn how faces move without needing a lot of labeled training data. One strategy involves reconstructing target video frames from source frames of the same person, allowing the system to learn subtle motion details. Another strategy is to train an encoder to represent a person's identity separately from the motion, ensuring the motion representation is dynamic and not tied to a specific identity.
This flexible motion modeling, combined with a diffusion-based generation approach, enables AniTalker to produce diverse and controllable facial animations. Rather than just a static, lip-synced character, AniTalker can create animated avatars with nuanced, lifelike expressions and movements. This makes it a powerful tool for applications like virtual avatars, digital assistants, and augmented reality experiences.
Technical Explanation
AniTalker introduces a novel framework for generating animated talking faces from a single portrait image. Unlike previous approaches that primarily focus on verbal cues such as lip synchronization, AniTalker employs a universal motion representation to effectively capture a wide range of facial dynamics, including subtle expressions and head movements.
AniTalker's motion depiction is enhanced through two self-supervised learning strategies. The first involves reconstructing target video frames from source frames within the same identity to learn subtle motion representations. The second strategy develops an identity encoder using metric learning while actively minimizing mutual information between the identity and motion encoders. This ensures that the motion representation is dynamic and devoid of identity-specific details, significantly reducing the need for labeled data.
Furthermore, the integration of a diffusion model with a variance adapter allows for the generation of diverse and controllable facial animations. This approach not only demonstrates AniTalker's capability to create detailed and realistic facial movements but also highlights its potential in crafting dynamic avatars for real-world applications, such as virtual assistants and augmented reality experiences.
Critical Analysis
The paper introduces several innovative strategies employed by AniTalker, such as the use of a universal motion representation and self-supervised learning techniques, which collectively reduce the need for labeled data and enable the generation of diverse and controllable facial animations.
However, the paper does not extensively discuss the limitations of the proposed approach. For example, it is unclear how AniTalker would perform on a wider range of facial expressions, head poses, and viewing angles, or how it would handle occlusions or dynamic backgrounds. Additionally, the paper does not provide a comparative analysis with other state-of-the-art talking face generation models, which would help contextualize the performance and capabilities of AniTalker.
While the synthetic results demonstrate the system's ability to create lifelike facial animations, further evaluation on real-world applications and user studies would be valuable to assess the practical usability and acceptance of the generated avatars. Exploring the potential biases or ethical implications of such a technology would also be an important consideration for future research.
Conclusion
AniTalker represents a significant advancement in the field of talking face generation by introducing a novel framework that can create lifelike animated faces from a single portrait image. The core innovation lies in the use of a universal motion representation and self-supervised learning strategies, which enable the system to capture a wide range of facial dynamics without relying heavily on labeled data.
The integration of a diffusion model and a variance adapter further enhances the diversity and controllability of the generated facial animations, making AniTalker a promising tool for applications such as virtual assistants, digital avatars, and augmented reality experiences. As the research in this area continues to progress, addressing the identified limitations and exploring the ethical implications of such technologies will be crucial to ensure the responsible development and deployment of these innovative systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
0
0
Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
5/10/2024
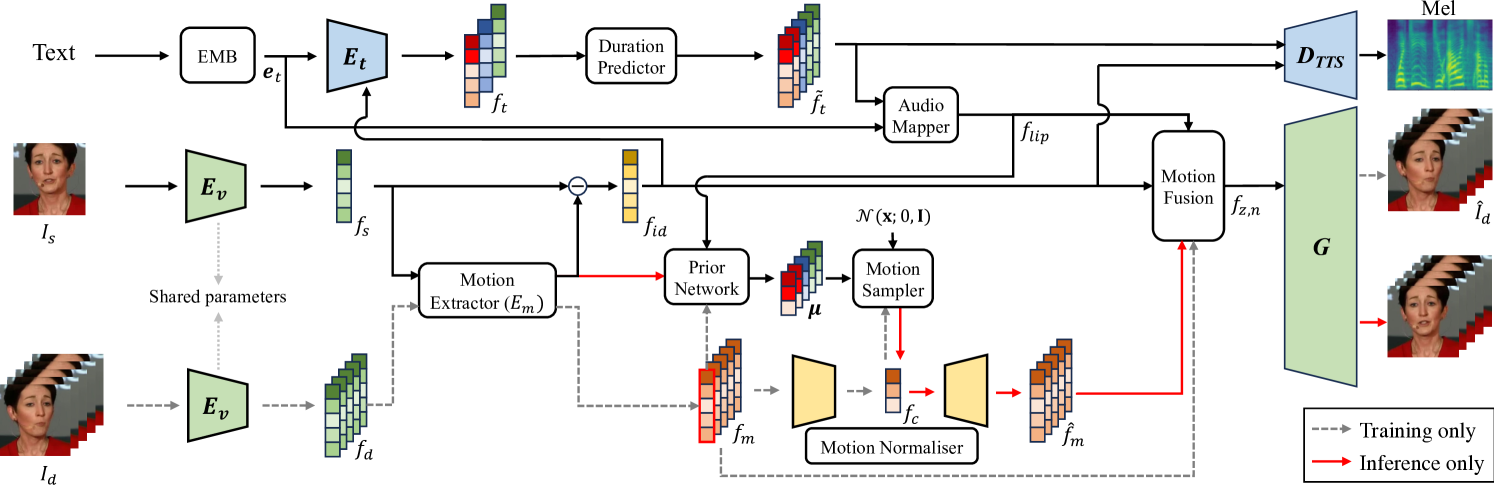
New!Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
0
0
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
5/17/2024

Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
0
0
Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
4/22/2024
🛸
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
0
0
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
5/14/2024