Effective Pre-Training of Audio Transformers for Sound Event Detection

0

Sign in to get full access
Overview
- This paper focuses on pre-training audio transformers for sound event detection.
- The computational results were achieved using the Linz Institute of Technology (LIT) AI Lab Cluster, which is supported by the Federal State of Upper Austria.
- The research was funded by the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme.
Plain English Explanation
In this paper, the researchers explored ways to effectively pre-train audio transformers, which are a type of machine learning model, to improve their performance on the task of sound event detection. Sound event detection involves identifying and locating different types of sounds, such as a car horn, a dog barking, or a person speaking, within an audio recording.
The researchers used a dataset called AudioSet, which contains a large and diverse collection of audio clips and their corresponding labels, to pre-train the audio transformers. This pre-training process helps the model learn general audio features and patterns that can then be fine-tuned for the specific task of sound event detection.
The researchers experimented with different pre-training techniques, including knowledge distillation, which involves training a smaller, more efficient model to mimic the behavior of a larger, more complex model. They also explored the use of temporally-strong labels, which provide more detailed information about the temporal location of sound events within the audio clips.
By optimizing the pre-training process, the researchers were able to significantly improve the performance of the audio transformers on sound event detection tasks, demonstrating the importance of effective pre-training for this type of model.
Technical Explanation
The paper presents a study on the pre-training of audio transformers for the task of sound event detection. The researchers used the AudioSet dataset, which contains over 2 million audio clips labeled with sound event categories, to pre-train the audio transformer models.
They explored several techniques to improve the pre-training process, including knowledge distillation and the use of temporally-strong labels. Knowledge distillation involves training a smaller, more efficient model to mimic the behavior of a larger, more complex model, while temporally-strong labels provide more detailed information about the temporal location of sound events within the audio clips.
The researchers found that these techniques helped to significantly improve the performance of the audio transformers on sound event detection tasks, demonstrating the importance of effective pre-training for this type of model.
Critical Analysis
The paper presents a thorough and well-designed study on the pre-training of audio transformers for sound event detection. The researchers have clearly put a lot of effort into exploring different pre-training techniques and evaluating their effectiveness.
One potential limitation of the study is that it focuses solely on the AudioSet dataset, which may not be representative of all sound event detection scenarios. It would be interesting to see how the pre-training techniques perform on other datasets or in real-world applications.
Additionally, the paper does not provide much discussion on the computational resources and training time required for the pre-training process. This information could be useful for researchers and practitioners who are considering adopting these techniques in their own work.
Overall, the paper makes a valuable contribution to the field of audio AI and provides a solid foundation for further research and development in this area.
Conclusion
This paper presents an effective approach for pre-training audio transformers to improve their performance on sound event detection tasks. By exploring techniques like knowledge distillation and the use of temporally-strong labels, the researchers were able to significantly enhance the capabilities of these models.
The findings of this study have important implications for the development of advanced audio AI systems, which can be used in a wide range of applications, from smart home assistants to autonomous vehicles. By optimizing the pre-training process, researchers and practitioners can build more accurate and efficient sound event detection models, paving the way for more sophisticated and user-friendly audio-based technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Effective Pre-Training of Audio Transformers for Sound Event Detection
Florian Schmid, Tobias Morocutti, Francesco Foscarin, Jan Schluter, Paul Primus, Gerhard Widmer
We propose a pre-training pipeline for audio spectrogram transformers for frame-level sound event detection tasks. On top of common pre-training steps, we add a meticulously designed training routine on AudioSet frame-level annotations. This includes a balanced sampler, aggressive data augmentation, and ensemble knowledge distillation. For five transformers, we obtain a substantial performance improvement over previously available checkpoints both on AudioSet frame-level predictions and on frame-level sound event detection downstream tasks, confirming our pipeline's effectiveness. We publish the resulting checkpoints that researchers can directly fine-tune to build high-performance models for sound event detection tasks.
Read more9/17/2024
0
Improving Audio Spectrogram Transformers for Sound Event Detection Through Multi-Stage Training
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
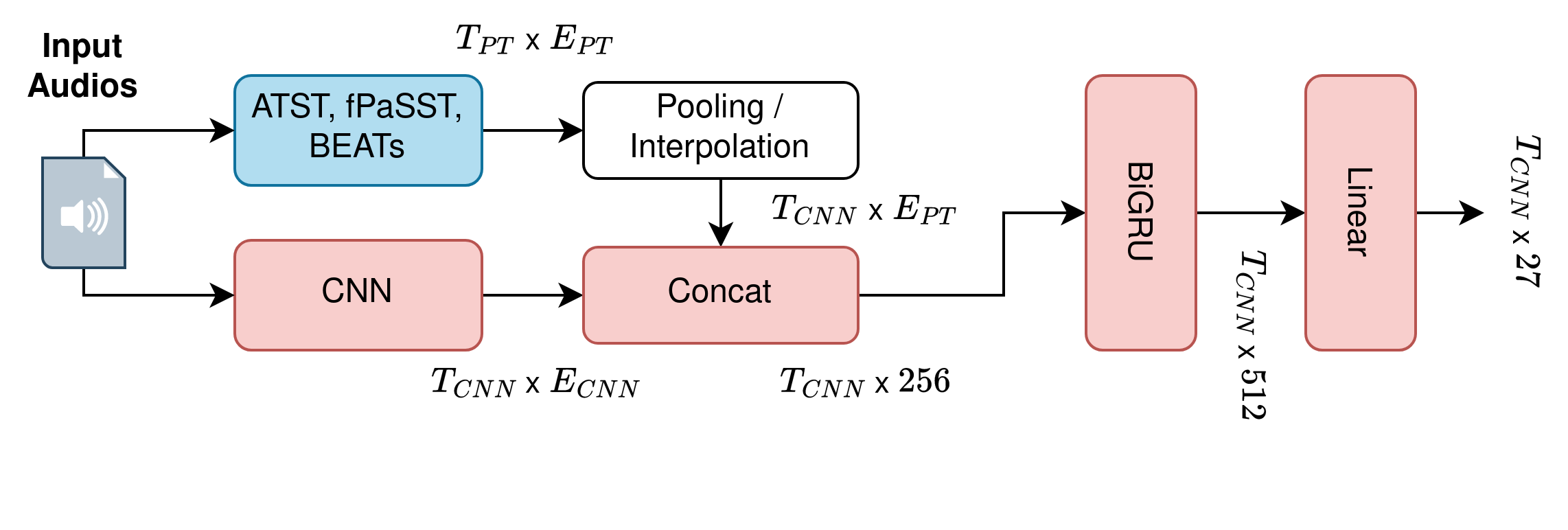
This technical report describes the CP-JKU team's submission for Task 4 Sound Event Detection with Heterogeneous Training Datasets and Potentially Missing Labels of the DCASE 24 Challenge. We fine-tune three large Audio Spectrogram Transformers, PaSST, BEATs, and ATST, on the joint DESED and MAESTRO datasets in a two-stage training procedure. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the large pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of all three fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, boosting single-model performance substantially. Additionally, we pre-train PaSST and ATST on the subset of AudioSet that comes with strong temporal labels, before fine-tuning them on the Task 4 datasets.
Read more8/6/2024
0
Multi-Iteration Multi-Stage Fine-Tuning of Transformers for Sound Event Detection with Heterogeneous Datasets
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
A central problem in building effective sound event detection systems is the lack of high-quality, strongly annotated sound event datasets. For this reason, Task 4 of the DCASE 2024 challenge proposes learning from two heterogeneous datasets, including audio clips labeled with varying annotation granularity and with different sets of possible events. We propose a multi-iteration, multi-stage procedure for fine-tuning Audio Spectrogram Transformers on the joint DESED and MAESTRO Real datasets. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, achieving a new single-model, state-of-the-art performance on the public evaluation set of DESED with a PSDS1 of 0.692. A single model and an ensemble, both based on our proposed training procedure, ranked first in Task 4 of the DCASE Challenge 2024.
Read more7/19/2024

0
Self Training and Ensembling Frequency Dependent Networks with Coarse Prediction Pooling and Sound Event Bounding Boxes
Hyeonuk Nam, Deokki Min, Seungdeok Choi, Inhan Choi, Yong-Hwa Park
To tackle sound event detection (SED) task, we propose frequency dependent networks (FreDNets), which heavily leverage frequency-dependent methods. We apply frequency warping and FilterAugment, which are frequency-dependent data augmentation methods. The model architecture consists of 3 branches: audio teacher-student transformer (ATST) branch, BEATs branch and CNN branch including either partial dilated frequency dynamic convolution (PDFD) or squeeze-and-Excitation (SE) with time-frame frequency-wise SE (tfwSE). To train MAESTRO labels with coarse temporal resolution, we apply max pooling on prediction for the MAESTRO dataset. Using best ensemble model, we apply self training to obtain pseudo label from DESED weak set, DESED unlabeled set and AudioSet. AudioSet labels are filtered to focus on high-confidence pseudo labels and AudioSet pseudo labels are used to train on DESED labels only. We used change-detection-based sound event bounding boxes (cSEBBs) as post processing for ensemble models on self training and submission models.
Read more6/26/2024