Multi-Iteration Multi-Stage Fine-Tuning of Transformers for Sound Event Detection with Heterogeneous Datasets

0
Sign in to get full access
Overview
- This paper explores a multi-iteration, multi-stage fine-tuning approach for using transformer models to detect sound events, particularly in scenarios with heterogeneous datasets.
- The authors propose a technique that involves progressively fine-tuning a pre-trained transformer model on multiple diverse datasets, with the goal of improving performance on sound event detection tasks.
- The paper presents experimental results demonstrating the effectiveness of this approach compared to single-stage fine-tuning or training from scratch.
Plain English Explanation
The paper describes a new way to train transformer models to recognize different types of sounds, like sound event detection. The key idea is to take a pre-trained transformer model and fine-tune it, or adjust its internal parameters, on multiple datasets that have different types of sounds.
This multi-stage, multi-iteration fine-tuning process allows the model to gradually learn to recognize a wider variety of sounds, even if the original training data didn't cover all of them. The authors show that this approach works better than just fine-tuning the model on a single dataset or training it from scratch on all the data.
Imagine you're trying to teach a child to identify different animals. If you start by showing them only farm animals, they may struggle to recognize wild animals later on. But if you gradually introduce them to more and more animal types, they'll build a more robust understanding. Similarly, the multi-stage fine-tuning helps the transformer model build up its ability to recognize diverse sound events.
Technical Explanation
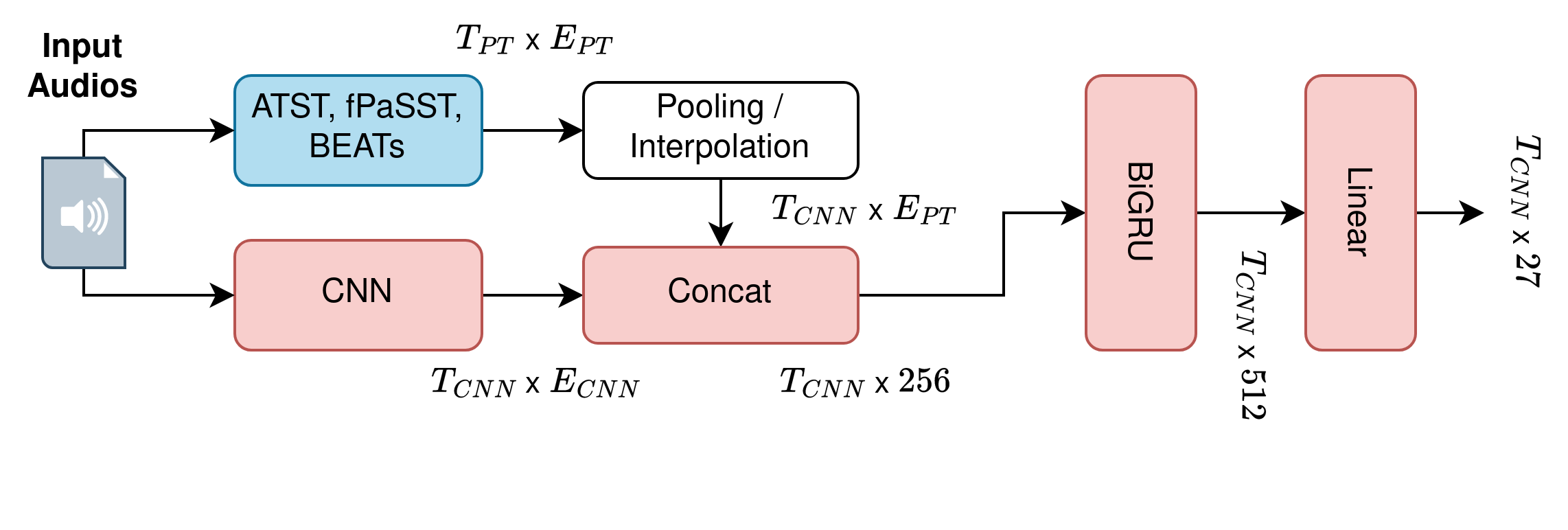
The paper proposes a "multi-iteration multi-stage fine-tuning" approach for training transformer models to perform sound event detection. The key elements of this approach are:
- Pre-training: The authors start with a pre-trained transformer model, such as BERT or ViT, that has been trained on a large general dataset.
- Fine-tuning Stages: They then fine-tune this pre-trained model on multiple diverse datasets in a step-wise fashion. Each fine-tuning stage focuses on a different dataset, allowing the model to gradually learn to recognize a wider range of sound events.
- Iterative Fine-tuning: After each fine-tuning stage, the model is evaluated on a validation set. If performance improves, the fine-tuning continues; otherwise, the model is reverted to the previous checkpoint and the fine-tuning process moves on to the next dataset.
The authors compare this approach to single-stage fine-tuning and training from scratch, and show that the multi-iteration, multi-stage fine-tuning leads to better performance on sound event detection tasks, particularly when dealing with heterogeneous datasets.
Critical Analysis
The paper provides a compelling approach to improving the performance of transformer models on sound event detection tasks, especially in scenarios with diverse or heterogeneous datasets. However, there are a few potential limitations and areas for further research:
-
Dataset Selection: The authors do not provide a clear methodology for selecting the datasets to be used in the fine-tuning stages. The choice of datasets could have a significant impact on the model's performance, and a more systematic approach to dataset selection may be warranted.
-
Computational Complexity: The multi-iteration, multi-stage fine-tuning process may be computationally intensive, as it requires training the model multiple times on different datasets. The authors do not provide a detailed analysis of the computational cost of their approach.
-
Generalization Capabilities: While the authors demonstrate improved performance on the datasets used in their experiments, it's unclear how well the trained models would generalize to completely novel sound event detection tasks or datasets. Further research is needed to assess the broader applicability of this approach.
Overall, the paper presents a promising technique for enhancing the performance of transformer models on sound event detection tasks, but additional research is needed to fully understand its limitations and potential for real-world applications.
Conclusion
This paper introduces a multi-iteration, multi-stage fine-tuning approach for using transformer models to detect sound events, particularly in scenarios with diverse or heterogeneous datasets. By progressively fine-tuning the model on multiple datasets, the authors demonstrate that this technique can outperform single-stage fine-tuning or training from scratch.
The key insights from this research are the potential benefits of a gradual, multi-stage fine-tuning process for building more robust and versatile sound event detection models. This approach could have important implications for a wide range of audio-based applications, from smart home assistants to wildlife monitoring systems.
While the paper presents promising results, further research is needed to fully understand the limitations and broader applicability of this technique. Nonetheless, this work represents an important step forward in the field of sound event detection and highlights the potential of transformer models to tackle complex audio processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Iteration Multi-Stage Fine-Tuning of Transformers for Sound Event Detection with Heterogeneous Datasets
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
A central problem in building effective sound event detection systems is the lack of high-quality, strongly annotated sound event datasets. For this reason, Task 4 of the DCASE 2024 challenge proposes learning from two heterogeneous datasets, including audio clips labeled with varying annotation granularity and with different sets of possible events. We propose a multi-iteration, multi-stage procedure for fine-tuning Audio Spectrogram Transformers on the joint DESED and MAESTRO Real datasets. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, achieving a new single-model, state-of-the-art performance on the public evaluation set of DESED with a PSDS1 of 0.692. A single model and an ensemble, both based on our proposed training procedure, ranked first in Task 4 of the DCASE Challenge 2024.
Read more7/19/2024
0
Improving Audio Spectrogram Transformers for Sound Event Detection Through Multi-Stage Training
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
This technical report describes the CP-JKU team's submission for Task 4 Sound Event Detection with Heterogeneous Training Datasets and Potentially Missing Labels of the DCASE 24 Challenge. We fine-tune three large Audio Spectrogram Transformers, PaSST, BEATs, and ATST, on the joint DESED and MAESTRO datasets in a two-stage training procedure. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the large pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of all three fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, boosting single-model performance substantially. Additionally, we pre-train PaSST and ATST on the subset of AudioSet that comes with strong temporal labels, before fine-tuning them on the Task 4 datasets.
Read more8/6/2024

0
FMSG-JLESS Submission for DCASE 2024 Task4 on Sound Event Detection with Heterogeneous Training Dataset and Potentially Missing Labels
Yang Xiao, Han Yin, Jisheng Bai, Rohan Kumar Das
This report presents the systems developed and submitted by Fortemedia Singapore (FMSG) and Joint Laboratory of Environmental Sound Sensing (JLESS) for DCASE 2024 Task 4. The task focuses on recognizing event classes and their time boundaries, given that multiple events can be present and may overlap in an audio recording. The novelty this year is a dataset with two sources, making it challenging to achieve good performance without knowing the source of the audio clips during evaluation. To address this, we propose a sound event detection method using domain generalization. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We focus on three main strategies to improve our method. First, we apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Second, we consider training loss of our model specific to each datasets for their corresponding classes. This independent learning framework helps the model extract domain-specific features effectively. Lastly, we use the sound event bounding boxes method for post-processing. Our proposed method shows superior macro-average pAUC and polyphonic SED score performance on the DCASE 2024 Challenge Task 4 validation dataset and public evaluation dataset.
Read more7/2/2024

0
Self Training and Ensembling Frequency Dependent Networks with Coarse Prediction Pooling and Sound Event Bounding Boxes
Hyeonuk Nam, Deokki Min, Seungdeok Choi, Inhan Choi, Yong-Hwa Park
To tackle sound event detection (SED) task, we propose frequency dependent networks (FreDNets), which heavily leverage frequency-dependent methods. We apply frequency warping and FilterAugment, which are frequency-dependent data augmentation methods. The model architecture consists of 3 branches: audio teacher-student transformer (ATST) branch, BEATs branch and CNN branch including either partial dilated frequency dynamic convolution (PDFD) or squeeze-and-Excitation (SE) with time-frame frequency-wise SE (tfwSE). To train MAESTRO labels with coarse temporal resolution, we apply max pooling on prediction for the MAESTRO dataset. Using best ensemble model, we apply self training to obtain pseudo label from DESED weak set, DESED unlabeled set and AudioSet. AudioSet labels are filtered to focus on high-confidence pseudo labels and AudioSet pseudo labels are used to train on DESED labels only. We used change-detection-based sound event bounding boxes (cSEBBs) as post processing for ensemble models on self training and submission models.
Read more6/26/2024