An Effective, Robust and Fairness-aware Hate Speech Detection Framework

0

Sign in to get full access
Overview
- Presents an effective, robust, and fair hate speech detection framework
- Aims to improve upon existing hate speech detection models
- Focuses on enhancing fairness and robustness in addition to detection accuracy
Plain English Explanation
This paper introduces a new hate speech detection framework that is designed to be more effective, robust, and fair than previous models. The goal is to create a system that can accurately identify hate speech while also ensuring that the detection process is unbiased and resilient to various challenges.
The key aspects of this framework include:
- Improved Accuracy: The model is trained to achieve high performance in accurately detecting hate speech.
- Enhanced Robustness: The framework is designed to be resilient to factors like text perturbations, which can help maintain performance in real-world settings.
- Increased Fairness: The approach aims to ensure that the hate speech detection process is fair and not biased against certain groups or individuals.
By addressing these three important factors - effectiveness, robustness, and fairness - the researchers hope to develop a more comprehensive and reliable hate speech detection solution that can be widely deployed and trusted.
Technical Explanation
The researchers propose a hate speech detection framework that consists of several key components:
- Backbone Model: The framework utilizes a pre-trained language model as the backbone, which is then fine-tuned on the hate speech detection task.
- Robust Text Augmentation: To enhance robustness, the researchers apply various text perturbation techniques, such as word substitution and sentence reordering, to generate augmented examples during training.
- Fairness-aware Regularization: To address fairness concerns, the framework incorporates a fairness-aware regularization term in the training objective, which encourages the model to learn representations that are less biased towards protected attributes (e.g., gender, race).
- Debiased Attention Mechanism: The model also employs a debiased attention mechanism that aims to reduce the impact of biased features on the hate speech predictions.
The researchers evaluate their framework on multiple hate speech datasets and demonstrate its effectiveness in terms of hate speech detection accuracy, robustness to text perturbations, and fairness across different demographic groups.
Critical Analysis
The paper presents a comprehensive and well-designed framework for hate speech detection that addresses important challenges related to effectiveness, robustness, and fairness. The authors' approach to incorporating robust text augmentation and fairness-aware regularization is particularly noteworthy, as it represents a significant advancement in the field.
However, the paper does not provide a thorough discussion of the potential limitations of the proposed framework. For instance, the authors do not address the computational complexity of the debiased attention mechanism or the potential impact of the fairness-aware regularization on overall detection performance.
Additionally, the paper could have benefited from a more in-depth discussion of the ethical considerations surrounding hate speech detection, such as the potential for misuse or unintended consequences of such systems. While the authors emphasize the importance of fairness, a more comprehensive exploration of these issues would have strengthened the paper's overall contribution.
Conclusion
This paper introduces an effective, robust, and fairness-aware hate speech detection framework that represents a significant advancement in the field. By addressing key challenges related to accuracy, robustness, and fairness, the researchers have developed a more comprehensive and reliable solution for identifying and addressing hate speech in online platforms and social media. While the paper could have delved deeper into certain limitations and ethical considerations, the overall contribution is valuable and will likely inspire further research in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Effective, Robust and Fairness-aware Hate Speech Detection Framework
Guanyi Mou, Kyumin Lee
With the widespread online social networks, hate speeches are spreading faster and causing more damage than ever before. Existing hate speech detection methods have limitations in several aspects, such as handling data insufficiency, estimating model uncertainty, improving robustness against malicious attacks, and handling unintended bias (i.e., fairness). There is an urgent need for accurate, robust, and fair hate speech classification in online social networks. To bridge the gap, we design a data-augmented, fairness addressed, and uncertainty estimated novel framework. As parts of the framework, we propose Bidirectional Quaternion-Quasi-LSTM layers to balance effectiveness and efficiency. To build a generalized model, we combine five datasets collected from three platforms. Experiment results show that our model outperforms eight state-of-the-art methods under both no attack scenario and various attack scenarios, indicating the effectiveness and robustness of our model. We share our code along with combined dataset for better future research
Read more9/27/2024
0
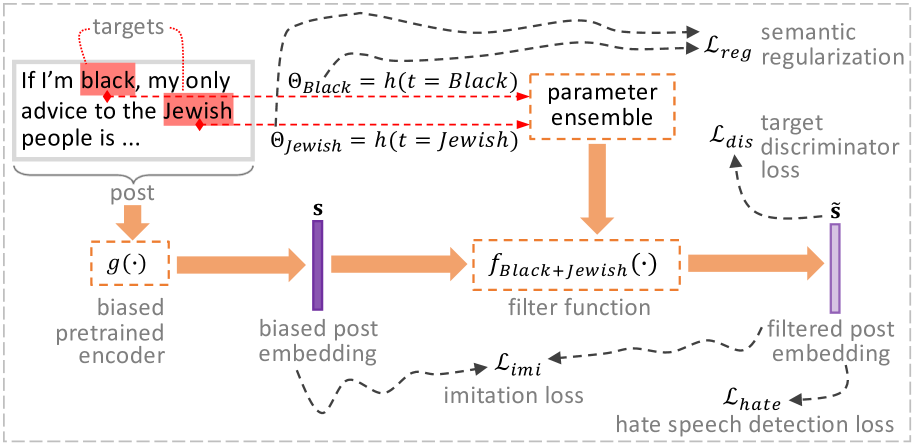
Hate Speech Detection with Generalizable Target-aware Fairness
Tong Chen, Danny Wang, Xurong Liang, Marten Risius, Gianluca Demartini, Hongzhi Yin
To counter the side effect brought by the proliferation of social media platforms, hate speech detection (HSD) plays a vital role in halting the dissemination of toxic online posts at an early stage. However, given the ubiquitous topical communities on social media, a trained HSD classifier easily becomes biased towards specific targeted groups (e.g., female and black people), where a high rate of false positive/negative results can significantly impair public trust in the fairness of content moderation mechanisms, and eventually harm the diversity of online society. Although existing fairness-aware HSD methods can smooth out some discrepancies across targeted groups, they are mostly specific to a narrow selection of targets that are assumed to be known and fixed. This inevitably prevents those methods from generalizing to real-world use cases where new targeted groups constantly emerge over time. To tackle this defect, we propose Generalizable target-aware Fairness (GetFair), a new method for fairly classifying each post that contains diverse and even unseen targets during inference. To remove the HSD classifier's spurious dependence on target-related features, GetFair trains a series of filter functions in an adversarial pipeline, so as to deceive the discriminator that recovers the targeted group from filtered post embeddings. To maintain scalability and generalizability, we innovatively parameterize all filter functions via a hypernetwork that is regularized by the semantic affinity among targets. Taking a target's pretrained word embedding as input, the hypernetwork generates the weights used by each target-specific filter on-the-fly without storing dedicated filter parameters. Finally, comparative experiments on two HSD datasets have shown advantageous performance of GetFair on out-of-sample targets.
Read more6/12/2024

0
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Nankai Lin, Hongyan Wu, Zhengming Chen, Zijian Li, Lianxi Wang, Shengyi Jiang, Dong Zhou, Aimin Yang
Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
Read more6/10/2024
0
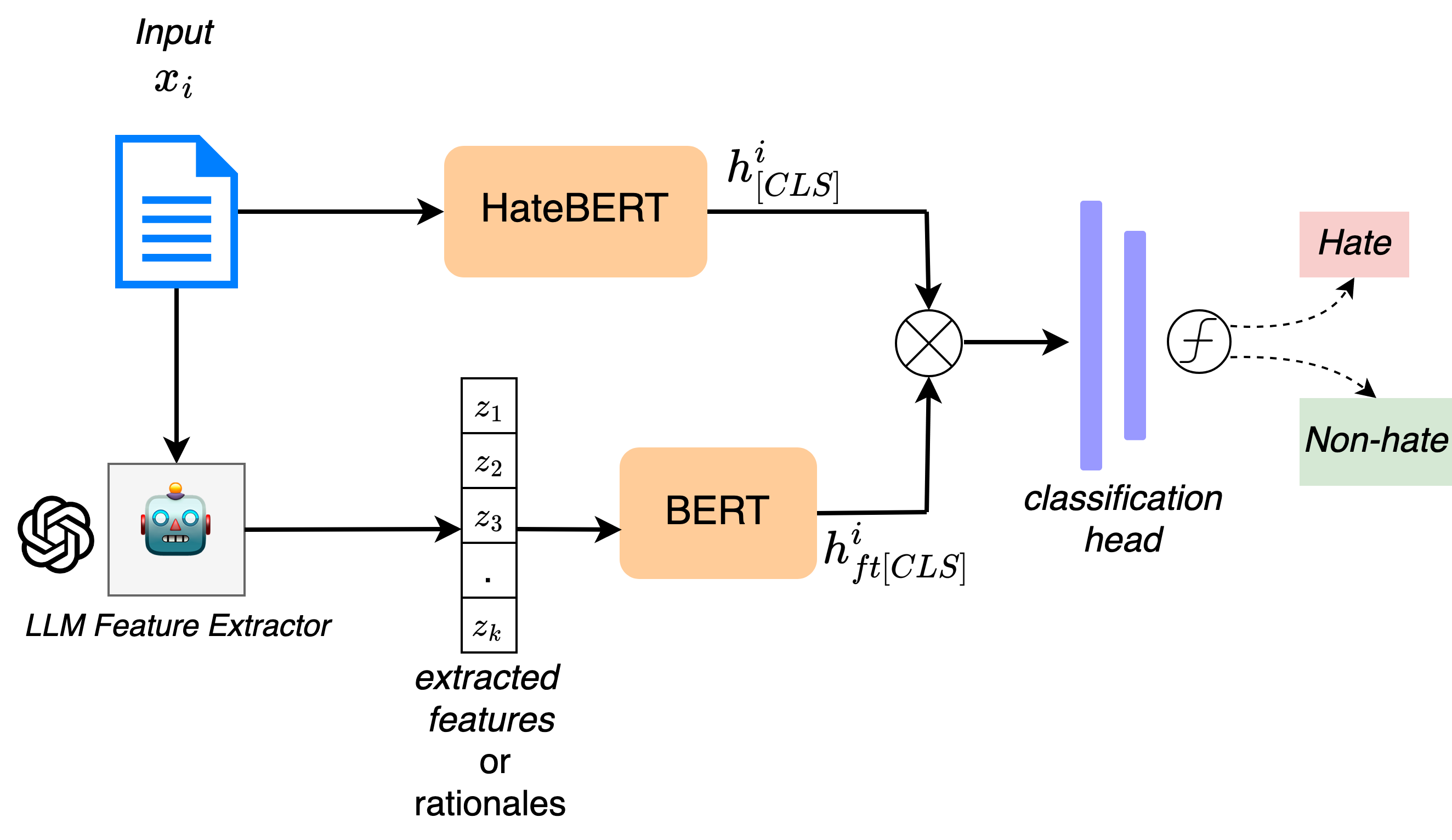
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Ayushi Nirmal, Amrita Bhattacharjee, Paras Sheth, Huan Liu
Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of English language social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability. All code and data will be made available at https://github.com/AmritaBh/shield.
Read more5/9/2024