Hate Speech Detection with Generalizable Target-aware Fairness

0
Sign in to get full access
Overview
- This research paper presents a novel approach to hate speech detection that aims to be more fair and generalizable across different targets of hate.
- The key ideas include:
- Developing a "target-aware" model that can capture the nuances of how hate speech is expressed towards different demographic groups.
- Incorporating debiasing techniques to mitigate unwanted biases in the hate speech detection system.
- Evaluating the model's performance on diverse datasets to assess its generalization capabilities.
Plain English Explanation
Hate speech on online platforms is a serious problem, as it can target and harm people based on characteristics like their race, gender, or religion. Traditional hate speech detection systems may struggle to accurately identify hate speech that is directed at different groups. This research paper proposes a new approach that is more aware of the specific targets of hate speech and tries to be fairer in its detection.
The key idea is to train the hate speech detection model to be "target-aware" - that is, to understand how hate speech might be expressed differently towards different demographic groups. For example, hate speech directed at women may use different language and patterns compared to hate speech targeting ethnic minorities. By accounting for these nuances, the model can become more accurate and less biased in its predictions.
The researchers also incorporate debiasing techniques to further reduce unwanted biases in the system. This helps ensure that the model's hate speech detections are not unfairly skewed towards or against particular groups.
To evaluate their approach, the researchers tested the model's performance on a diverse set of hate speech datasets. This helps demonstrate the model's ability to generalize and perform well across a range of real-world scenarios, rather than just on a single, limited dataset.
The research builds on previous work on fairness-aware hate speech detection and subgraph-level analysis for detecting misinformation. It also aligns with efforts to develop more robust and generalizable approaches to hate speech classification and automatically identify fairness issues in generated content.
Technical Explanation
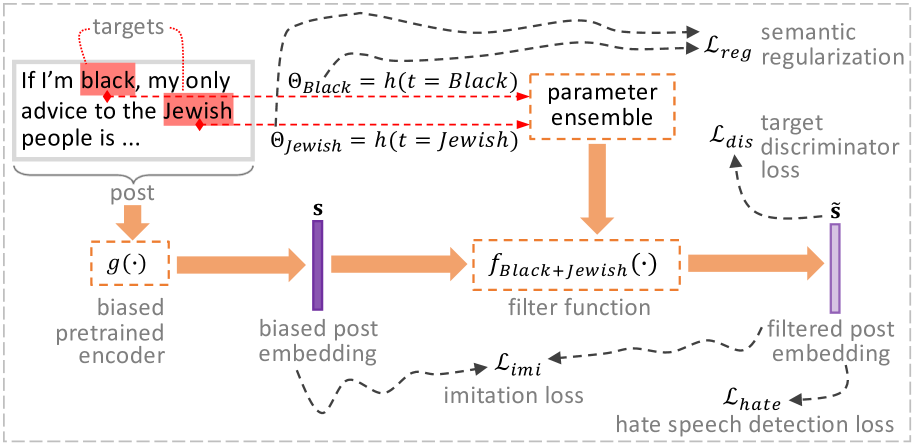
The researchers propose a "target-aware" hate speech detection model that aims to capture the nuanced ways in which hate speech is expressed towards different demographic groups. The model consists of a Transformer-based architecture that takes the text input and demographic information about the target as input, and outputs a prediction of whether the text contains hate speech.
To mitigate unwanted biases in the model, the researchers incorporate debiasing techniques, such as adversarial training and calibrated data augmentation. These techniques help ensure that the model's hate speech detections are not unfairly skewed towards or against particular groups.
The model's performance is evaluated on a diverse set of hate speech datasets, including those that focus on different target groups (e.g., race, gender, religion). This allows the researchers to assess the model's ability to generalize and perform well across a range of real-world scenarios, rather than just on a single, limited dataset.
The experimental results demonstrate that the proposed target-aware and debiased model outperforms previous state-of-the-art approaches in terms of overall hate speech detection accuracy and fairness metrics. The model is able to better capture the nuances of how hate speech is expressed towards different targets, leading to more accurate and equitable detections.
Critical Analysis
The researchers have made a commendable effort to address the important challenge of developing more fair and generalizable hate speech detection systems. By incorporating target-awareness and debiasing techniques, the model represents a step forward in the field of content moderation for online platforms.
However, it's important to note that hate speech detection remains a complex and challenging task, with inherent difficulties in defining and consistently annotating hate speech. While the proposed model shows promising results, it is likely that there are still some remaining biases or limitations that the researchers have not fully accounted for.
Additionally, the evaluation of the model's generalization abilities is limited to the specific datasets used in the study. It would be valuable to further test the model's performance on a wider range of real-world scenarios, including potentially emerging forms of hate speech and evolving social contexts.
Nonetheless, the research presents a thoughtful and innovative approach that could inspire further advancements in this important area of study. Continued efforts to develop more fair and robust hate speech detection systems are crucial for creating safer and more inclusive online environments.
Conclusion
This research paper introduces a novel approach to hate speech detection that aims to be more target-aware and fair. By incorporating mechanisms to capture the nuances of how hate speech is expressed towards different demographic groups and to mitigate unwanted biases, the proposed model demonstrates improved performance and generalization capabilities compared to previous state-of-the-art methods.
The work highlights the importance of developing content moderation systems that can accurately and equitably identify hate speech, rather than perpetuating or amplifying harmful biases. As online platforms continue to grapple with the challenge of moderating user-generated content at scale, this research contributes valuable insights and techniques that could inform the design of more effective and inclusive hate speech detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hate Speech Detection with Generalizable Target-aware Fairness
Tong Chen, Danny Wang, Xurong Liang, Marten Risius, Gianluca Demartini, Hongzhi Yin
To counter the side effect brought by the proliferation of social media platforms, hate speech detection (HSD) plays a vital role in halting the dissemination of toxic online posts at an early stage. However, given the ubiquitous topical communities on social media, a trained HSD classifier easily becomes biased towards specific targeted groups (e.g., female and black people), where a high rate of false positive/negative results can significantly impair public trust in the fairness of content moderation mechanisms, and eventually harm the diversity of online society. Although existing fairness-aware HSD methods can smooth out some discrepancies across targeted groups, they are mostly specific to a narrow selection of targets that are assumed to be known and fixed. This inevitably prevents those methods from generalizing to real-world use cases where new targeted groups constantly emerge over time. To tackle this defect, we propose Generalizable target-aware Fairness (GetFair), a new method for fairly classifying each post that contains diverse and even unseen targets during inference. To remove the HSD classifier's spurious dependence on target-related features, GetFair trains a series of filter functions in an adversarial pipeline, so as to deceive the discriminator that recovers the targeted group from filtered post embeddings. To maintain scalability and generalizability, we innovatively parameterize all filter functions via a hypernetwork that is regularized by the semantic affinity among targets. Taking a target's pretrained word embedding as input, the hypernetwork generates the weights used by each target-specific filter on-the-fly without storing dedicated filter parameters. Finally, comparative experiments on two HSD datasets have shown advantageous performance of GetFair on out-of-sample targets.
Read more6/12/2024

0
An Effective, Robust and Fairness-aware Hate Speech Detection Framework
Guanyi Mou, Kyumin Lee
With the widespread online social networks, hate speeches are spreading faster and causing more damage than ever before. Existing hate speech detection methods have limitations in several aspects, such as handling data insufficiency, estimating model uncertainty, improving robustness against malicious attacks, and handling unintended bias (i.e., fairness). There is an urgent need for accurate, robust, and fair hate speech classification in online social networks. To bridge the gap, we design a data-augmented, fairness addressed, and uncertainty estimated novel framework. As parts of the framework, we propose Bidirectional Quaternion-Quasi-LSTM layers to balance effectiveness and efficiency. To build a generalized model, we combine five datasets collected from three platforms. Experiment results show that our model outperforms eight state-of-the-art methods under both no attack scenario and various attack scenarios, indicating the effectiveness and robustness of our model. We share our code along with combined dataset for better future research
Read more9/27/2024

0
Trustworthy Hate Speech Detection Through Visual Augmentation
Ziyuan Yang, Ming Yan, Yingyu Chen, Hui Wang, Zexin Lu, Yi Zhang
The surge of hate speech on social media platforms poses a significant challenge, with hate speech detection~(HSD) becoming increasingly critical. Current HSD methods focus on enriching contextual information to enhance detection performance, but they overlook the inherent uncertainty of hate speech. We propose a novel HSD method, named trustworthy hate speech detection method through visual augmentation (TrusV-HSD), which enhances semantic information through integration with diffused visual images and mitigates uncertainty with trustworthy loss. TrusV-HSD learns semantic representations by effectively extracting trustworthy information through multi-modal connections without paired data. Our experiments on public HSD datasets demonstrate the effectiveness of TrusV-HSD, showing remarkable improvements over conventional methods.
Read more9/23/2024

0
Editable Fairness: Fine-Grained Bias Mitigation in Language Models
Ruizhe Chen, Yichen Li, Jianfei Yang, Joey Tianyi Zhou, Zuozhu Liu
Generating fair and accurate predictions plays a pivotal role in deploying large language models (LLMs) in the real world. However, existing debiasing methods inevitably generate unfair or incorrect predictions as they are designed and evaluated to achieve parity across different social groups but leave aside individual commonsense facts, resulting in modified knowledge that elicits unreasonable or undesired predictions. In this paper, we first establish a new bias mitigation benchmark, BiaScope, which systematically assesses performance by leveraging newly constructed datasets and metrics on knowledge retention and generalization. Then, we propose a novel debiasing approach, Fairness Stamp (FAST), which enables fine-grained calibration of individual social biases. FAST identifies the decisive layer responsible for storing social biases and then calibrates its outputs by integrating a small modular network, considering both bias mitigation and knowledge-preserving demands. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with superior debiasing performance while not compromising the overall model capability for knowledge retention and downstream predictions. This highlights the potential of fine-grained debiasing strategies to achieve fairness in LLMs. Code will be publicly available.
Read more8/23/2024