A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed

0

Sign in to get full access
Overview
- This paper presents a single-step, non-autoregressive automatic speech recognition (ASR) architecture that achieves high accuracy and fast inference speed.
- The proposed model, called EfficientASR, uses a novel attention-based approach to jointly optimize streaming and non-streaming ASR performance.
- The authors demonstrate that their model outperforms existing non-autoregressive ASR approaches in terms of accuracy and inference speed on several benchmark datasets.
Plain English Explanation
The researchers have developed a new type of speech recognition system that can quickly and accurately transcribe audio into text. Traditional speech recognition models work by processing the audio in a step-by-step, sequential manner, which can be slow. In contrast, this new non-autoregressive model can recognize the entire transcript all at once, making it much faster.
The key innovation is the use of a special type of neural network architecture called an "attention-based" model. This allows the system to focus on the most important parts of the audio signal when generating the transcript, rather than having to process everything sequentially. The authors show that this approach outperforms other non-autoregressive speech recognition models in terms of both accuracy and speed.
This could have important applications in real-time speech-to-text systems, such as voice assistants, live captioning, and language translation. By being faster and more accurate, the new model could enable more natural and responsive interactions between humans and machines.
Technical Explanation
The EfficientASR model proposed in this paper uses a non-autoregressive, attention-based architecture to perform automatic speech recognition. The key elements of the architecture include:
- Encoder: A transformer-based encoder that processes the input audio features and generates a compact representation.
- Attention-based Decoder: A decoder that uses attention mechanisms to generate the output transcript in a single step, rather than sequentially.
- Joint Optimization: The encoder and decoder are jointly optimized for both streaming and non-streaming ASR performance, using a novel training objective.
The authors evaluate the EfficientASR model on several benchmark datasets, including LibriSpeech and Switchboard. They show that it outperforms previous non-autoregressive ASR approaches in terms of word error rate (WER) while also achieving significantly faster inference speed.
The paper also includes an ablation study to understand the contributions of different components of the architecture, such as the attention mechanism and the joint optimization strategy.
Critical Analysis
The authors have demonstrated the effectiveness of their non-autoregressive, attention-based approach for speech recognition, but there are a few potential limitations and areas for further research:
- The model was evaluated on relatively clean, high-quality speech datasets. It would be interesting to see how it performs on more challenging, real-world speech data with background noise, accents, and other variability.
- The paper does not provide much analysis of the types of errors the model makes or the specific situations where it struggles. A more detailed error analysis could help identify areas for improvement.
- The authors mention that the model is designed for both streaming and non-streaming ASR, but they do not provide a thorough evaluation of the streaming performance. This would be an important area to explore further.
- While the attention-based approach provides significant speed improvements, there may be opportunities to further optimize the model size and computational requirements, especially for deployment on resource-constrained devices.
Overall, the EfficientASR model represents an interesting and promising advancement in the field of speech recognition, but there is still room for further refinement and exploration.
Conclusion
This paper presents a novel, non-autoregressive speech recognition architecture that achieves high accuracy and fast inference speed. By using an attention-based approach to jointly optimize for streaming and non-streaming performance, the EfficientASR model outperforms previous non-autoregressive ASR systems.
The implications of this research could be significant, as faster and more accurate speech recognition could enable more natural and responsive voice-based interactions in a wide range of applications, from virtual assistants to real-time captioning. However, further work is needed to explore the model's performance on more challenging, real-world speech data and to optimize its computational efficiency for deployment on a variety of devices.
Overall, this paper represents an important step forward in the development of advanced speech recognition systems, and the EfficientASR architecture provides a promising foundation for future research and innovation in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Ziyang Zhuang, Chenfeng Miao, Kun Zou, Ming Fang, Tao Wei, Zijian Li, Ning Cheng, Wei Hu, Shaojun Wang, Jing Xiao
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. In this paper, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EffectiveASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EffectiveASR achieves competitive results on the AISHELL-1 and AISHELL-2 Mandarin benchmarks compared to the leading models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the AR Conformer with about 30x inference speedup.
Read more8/29/2024

0
CTC-based Non-autoregressive Textless Speech-to-Speech Translation
Qingkai Fang, Zhengrui Ma, Yan Zhou, Min Zhang, Yang Feng
Direct speech-to-speech translation (S2ST) has achieved impressive translation quality, but it often faces the challenge of slow decoding due to the considerable length of speech sequences. Recently, some research has turned to non-autoregressive (NAR) models to expedite decoding, yet the translation quality typically lags behind autoregressive (AR) models significantly. In this paper, we investigate the performance of CTC-based NAR models in S2ST, as these models have shown impressive results in machine translation. Experimental results demonstrate that by combining pretraining, knowledge distillation, and advanced NAR training techniques such as glancing training and non-monotonic latent alignments, CTC-based NAR models achieve translation quality comparable to the AR model, while preserving up to 26.81$times$ decoding speedup.
Read more6/12/2024
🗣️
0
Automatic Speech Recognition for Hindi
Anish Saha, A. G. Ramakrishnan
Automatic speech recognition (ASR) is a key area in computational linguistics, focusing on developing technologies that enable computers to convert spoken language into text. This field combines linguistics and machine learning. ASR models, which map speech audio to transcripts through supervised learning, require handling real and unrestricted text. Text-to-speech systems directly work with real text, while ASR systems rely on language models trained on large text corpora. High-quality transcribed data is essential for training predictive models. The research involved two main components: developing a web application and designing a web interface for speech recognition. The web application, created with JavaScript and Node.js, manages large volumes of audio files and their transcriptions, facilitating collaborative human correction of ASR transcripts. It operates in real-time using a client-server architecture. The web interface for speech recognition records 16 kHz mono audio from any device running the web app, performs voice activity detection (VAD), and sends the audio to the recognition engine. VAD detects human speech presence, aiding efficient speech processing and reducing unnecessary processing during non-speech intervals, thus saving computation and network bandwidth in VoIP applications. The final phase of the research tested a neural network for accurately aligning the speech signal to hidden Markov model (HMM) states. This included implementing a novel backpropagation method that utilizes prior statistics of node co-activations.
Read more6/27/2024
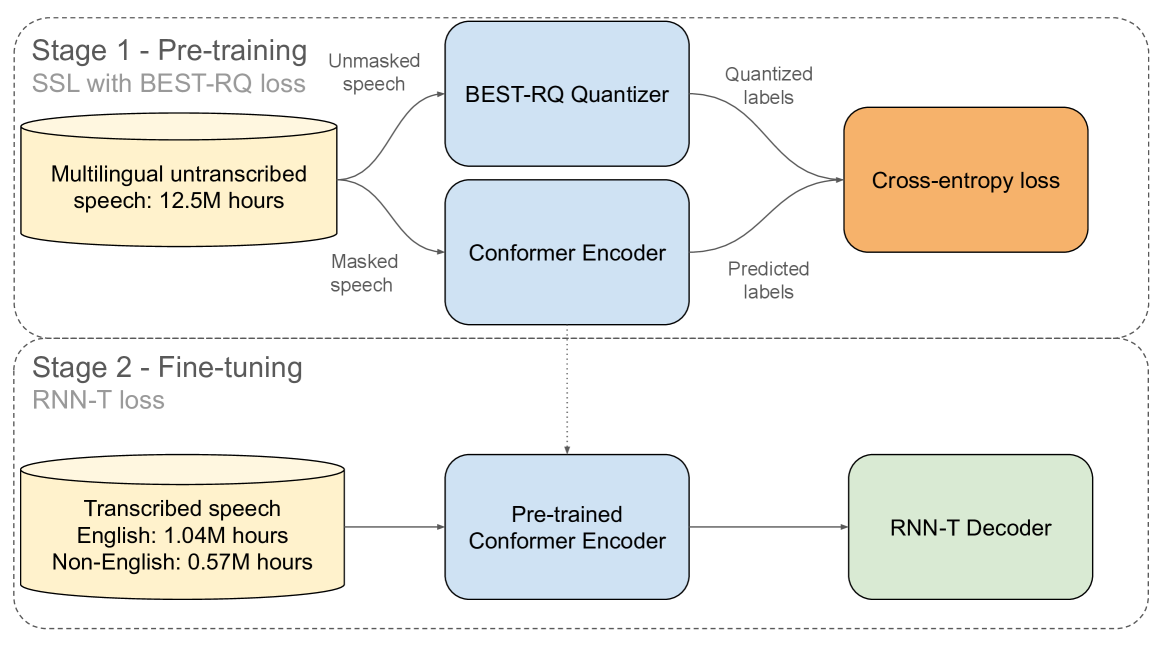
0
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Read more4/17/2024