Effectiveness of Tree-based Ensembles for Anomaly Discovery: Insights, Batch and Streaming Active Learning
1901.08930
0
0
❗
Abstract
In many real-world AD applications including computer security and fraud prevention, the anomaly detector must be configurable by the human analyst to minimize the effort on false positives. One important way to configure the detector is by providing true labels (nominal or anomaly) for a few instances. Recent work on active anomaly discovery has shown that greedily querying the top-scoring instance and tuning the weights of ensemble detectors based on label feedback allows us to quickly discover true anomalies. This paper makes four main contributions to improve the state-of-the-art in anomaly discovery using tree-based ensembles. First, we provide an important insight that explains the practical successes of unsupervised tree-based ensembles and active learning based on greedy query selection strategy. We also present empirical results on real-world data to support our insights and theoretical analysis to support active learning. Second, we develop a novel batch active learning algorithm to improve the diversity of discovered anomalies based on a formalism called compact description to describe the discovered anomalies. Third, we develop a novel active learning algorithm to handle streaming data setting. We present a data drift detection algorithm that not only detects the drift robustly, but also allows us to take corrective actions to adapt the anomaly detector in a principled manner. Fourth, we present extensive experiments to evaluate our insights and our tree-based active anomaly discovery algorithms in both batch and streaming data settings. Our results show that active learning allows us to discover significantly more anomalies than state-of-the-art unsupervised baselines, our batch active learning algorithm discovers diverse anomalies, and our algorithms under the streaming-data setup are competitive with the batch setup.
Create account to get full access
Overview
- This paper focuses on improving the state-of-the-art in anomaly discovery using tree-based ensemble models.
- The key contributions include:
- Providing insights to explain the practical successes of unsupervised tree-based ensembles and active learning.
- Developing a novel batch active learning algorithm to discover diverse anomalies.
- Developing a novel active learning algorithm for streaming data settings that can adapt to data drift.
- Extensive experiments evaluating the proposed approaches in both batch and streaming data settings.
Plain English Explanation
In many real-world applications like computer security and fraud detection, anomaly detectors need to be configurable by human analysts to minimize false positives. One way to configure the detector is by providing true labels (normal or anomaly) for a few instances. Recent work on active anomaly discovery has shown that querying the top-scoring instances and tuning the ensemble model based on the label feedback can quickly discover true anomalies.
This paper builds on this idea and makes several contributions to improve anomaly discovery using tree-based ensemble models. First, the authors provide an important insight that helps explain why unsupervised tree-based ensembles and active learning based on greedy query selection work well in practice. They also present empirical and theoretical analyses to support their insights.
Second, the authors develop a novel batch active learning algorithm that aims to discover a diverse set of anomalies. This is based on a concept called "compact description" to characterize the discovered anomalies.
Third, the authors develop a novel active learning algorithm for streaming data settings. This algorithm can detect data drift robustly and adapt the anomaly detector accordingly.
Finally, the authors present extensive experiments evaluating their approaches in both batch and streaming data settings. The results show that active learning can discover significantly more anomalies than unsupervised baselines, the batch active learning algorithm discovers diverse anomalies, and the streaming data algorithms are competitive with the batch setup.
Technical Explanation
The paper begins by highlighting the importance of configurable anomaly detectors in real-world applications like computer security and fraud prevention. One key way to configure the detector is by providing true labels (normal or anomaly) for a few instances, which can help tune the model and discover more anomalies.
The authors then review recent work on active anomaly discovery, which has shown that greedily querying the top-scoring instances and updating the ensemble model accordingly can quickly find true anomalies. Building on this, the paper makes four main contributions:
-
Insights on tree-based ensembles and active learning : The authors provide an important insight that helps explain the practical successes of unsupervised tree-based ensembles and active learning based on greedy query selection. They support this with both empirical results on real-world data and theoretical analysis. -
Batch active learning for diverse anomalies : The authors develop a novel batch active learning algorithm that aims to discover a diverse set of anomalies. This is based on a formalism called "compact description" to characterize the discovered anomalies. -
Active learning for streaming data : The authors develop a novel active learning algorithm for streaming data settings. This algorithm can robustly detect data drift and adapt the anomaly detector in a principled manner. -
Extensive experiments : The authors present extensive experiments evaluating their insights and tree-based active anomaly discovery algorithms in both batch and streaming data settings. The results show the advantages of active learning over unsupervised baselines.
Critical Analysis
The paper makes several valuable contributions to improving anomaly discovery using tree-based ensemble models. The insights provided on the practical successes of unsupervised tree-based ensembles and active learning are an important step towards better understanding these widely used techniques.
The novel batch active learning algorithm for discovering diverse anomalies is an interesting approach, though the authors acknowledge that the compact description formalism may have limitations in capturing all aspects of anomalies. Further research could explore alternative ways to encourage diversity in the discovered anomalies.
The active learning algorithm for streaming data settings is a useful addition, as many real-world applications involve continuously evolving data. The ability to detect and adapt to data drift is an important capability. However, the authors note that their approach assumes the data distribution changes gradually, and more abrupt drifts may require different strategies.
Overall, the paper presents a solid set of contributions to advance the state-of-the-art in anomaly discovery. The extensive experiments provide valuable empirical evidence to support the proposed techniques. Future work could explore ways to further improve the diversity and robustness of anomaly discovery, especially in challenging streaming data scenarios.
Conclusion
This paper makes several important contributions to improving anomaly discovery using tree-based ensemble models. The key insights, novel batch and streaming active learning algorithms, and extensive experimental evaluations collectively advance the state-of-the-art in this area.
The findings have practical implications for real-world applications like computer security and fraud detection, where configurable anomaly detectors that can quickly discover diverse and relevant anomalies are crucial. The authors' work provides a solid foundation for further research and development in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Classification Tree-based Active Learning: A Wrapper Approach
Ashna Jose, Emilie Devijver, Massih-Reza Amini, Noel Jakse, Roberta Poloni
0
0
Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
4/16/2024
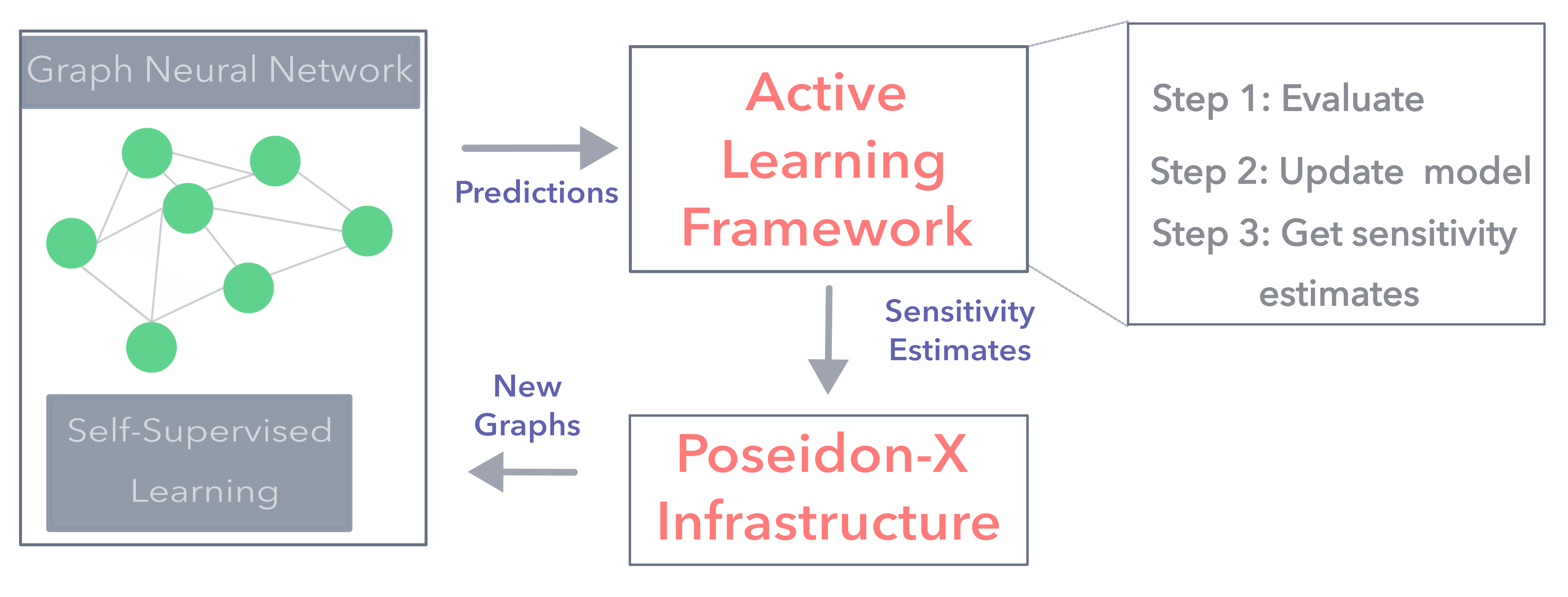
Advancing Anomaly Detection in Computational Workflows with Active Learning
Krishnan Raghavan, George Papadimitriou, Hongwei Jin, Anirban Mandal, Mariam Kiran, Prasanna Balaprakash, Ewa Deelman
0
0
A computational workflow, also known as workflow, consists of tasks that are executed in a certain order to attain a specific computational campaign. Computational workflows are commonly employed in science domains, such as physics, chemistry, genomics, to complete large-scale experiments in distributed and heterogeneous computing environments. However, running computations at such a large scale makes the workflow applications prone to failures and performance degradation, which can slowdown, stall, and ultimately lead to workflow failure. Learning how these workflows behave under normal and anomalous conditions can help us identify the causes of degraded performance and subsequently trigger appropriate actions to resolve them. However, learning in such circumstances is a challenging task because of the large volume of high-quality historical data needed to train accurate and reliable models. Generating such datasets not only takes a lot of time and effort but it also requires a lot of resources to be devoted to data generation for training purposes. Active learning is a promising approach to this problem. It is an approach where the data is generated as required by the machine learning model and thus it can potentially reduce the training data needed to derive accurate models. In this work, we present an active learning approach that is supported by an experimental framework, Poseidon-X, that utilizes a modern workflow management system and two cloud testbeds. We evaluate our approach using three computational workflows. For one workflow we run an end-to-end live active learning experiment, for the other two we evaluate our active learning algorithms using pre-captured data traces provided by the Flow-Bench benchmark. Our findings indicate that active learning not only saves resources, but it also improves the accuracy of the detection of anomalies.
5/13/2024
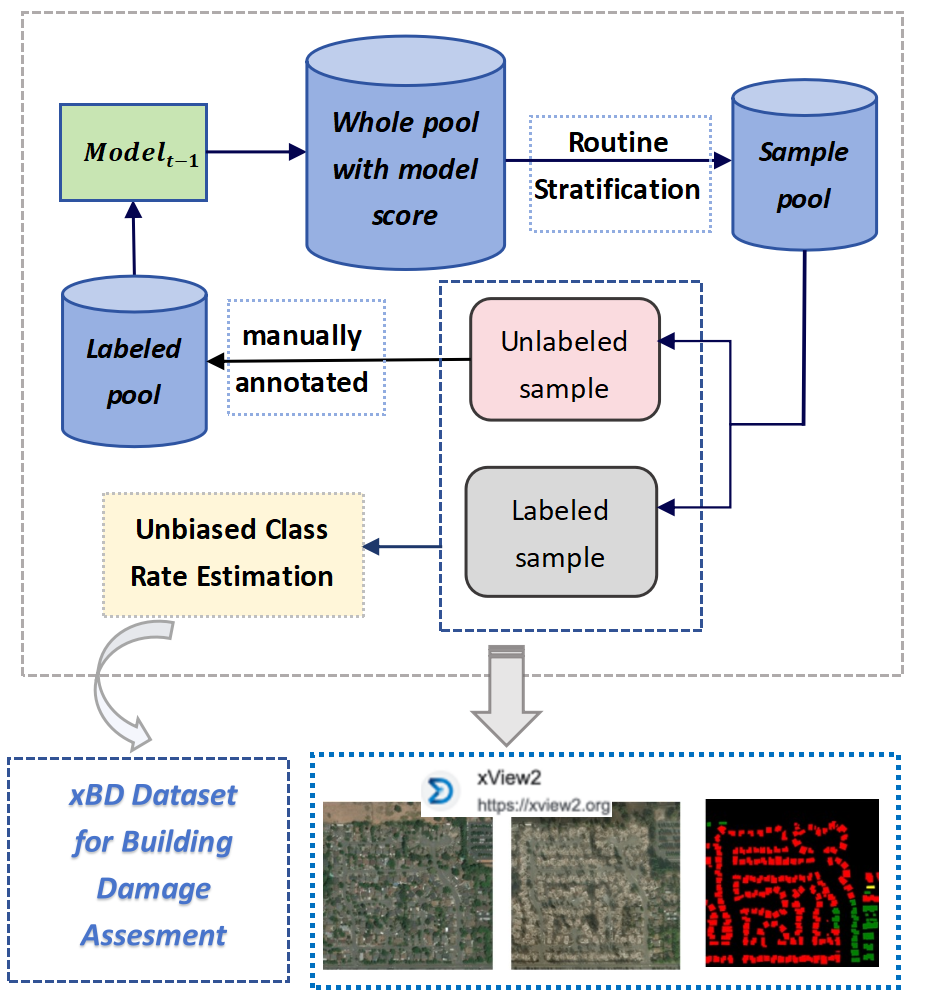
Towards Efficient Disaster Response via Cost-effective Unbiased Class Rate Estimation through Neyman Allocation Stratified Sampling Active Learning
Yanbing Bai, Xinyi Wu, Lai Xu, Jihan Pei, Erick Mas, Shunichi Koshimura
0
0
With the rapid development of earth observation technology, we have entered an era of massively available satellite remote-sensing data. However, a large amount of satellite remote sensing data lacks a label or the label cost is too high to hinder the potential of AI technology mining satellite data. Especially in such an emergency response scenario that uses satellite data to evaluate the degree of disaster damage. Disaster damage assessment encountered bottlenecks due to excessive focus on the damage of a certain building in a specific geographical space or a certain area on a larger scale. In fact, in the early days of disaster emergency response, government departments were more concerned about the overall damage rate of the disaster area instead of single-building damage, because this helps the government decide the level of emergency response. We present an innovative algorithm that constructs Neyman stratified random sampling trees for binary classification and extends this approach to multiclass problems. Through extensive experimentation on various datasets and model structures, our findings demonstrate that our method surpasses both passive and conventional active learning techniques in terms of class rate estimation and model enhancement with only 30%-60% of the annotation cost of simple sampling. It effectively addresses the 'sampling bias' challenge in traditional active learning strategies and mitigates the 'cold start' dilemma. The efficacy of our approach is further substantiated through application to disaster evaluation tasks using Xview2 Satellite imagery, showcasing its practical utility in real-world contexts.
5/29/2024
🌿
Transductive Active Learning: Theory and Applications
Jonas Hubotter, Bhavya Sukhija, Lenart Treven, Yarden As, Andreas Krause
0
0
We generalize active learning to address real-world settings with concrete prediction targets where sampling is restricted to an accessible region of the domain, while prediction targets may lie outside this region. We analyze a family of decision rules that sample adaptively to minimize uncertainty about prediction targets. We are the first to show, under general regularity assumptions, that such decision rules converge uniformly to the smallest possible uncertainty obtainable from the accessible data. We demonstrate their strong sample efficiency in two key applications: Active few-shot fine-tuning of large neural networks and safe Bayesian optimization, where they improve significantly upon the state-of-the-art.
5/24/2024