On the Effects of Fine-tuning Language Models for Text-Based Reinforcement Learning
2404.10174
0
0
Abstract
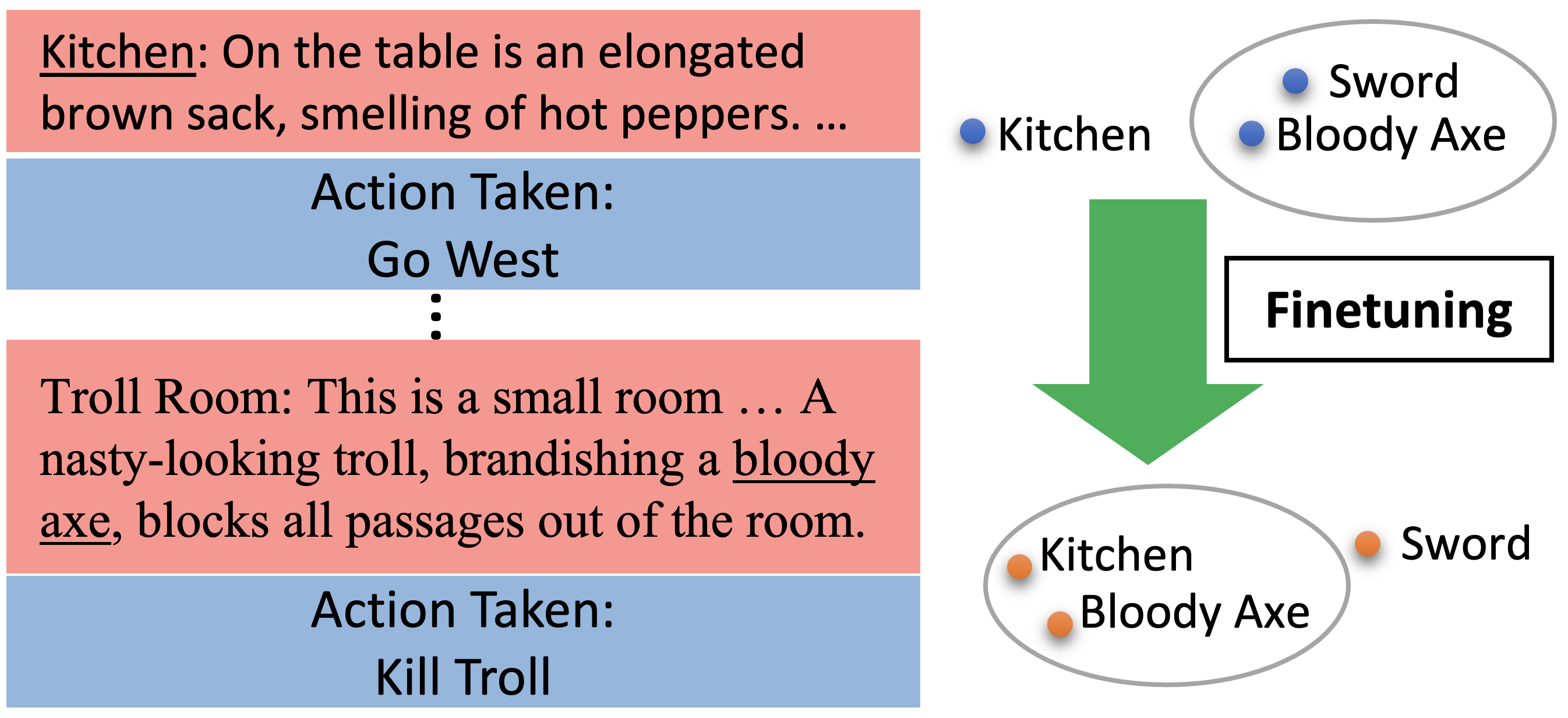
Text-based reinforcement learning involves an agent interacting with a fictional environment using observed text and admissible actions in natural language to complete a task. Previous works have shown that agents can succeed in text-based interactive environments even in the complete absence of semantic understanding or other linguistic capabilities. The success of these agents in playing such games suggests that semantic understanding may not be important for the task. This raises an important question about the benefits of LMs in guiding the agents through the game states. In this work, we show that rich semantic understanding leads to efficient training of text-based RL agents. Moreover, we describe the occurrence of semantic degeneration as a consequence of inappropriate fine-tuning of language models in text-based reinforcement learning (TBRL). Specifically, we describe the shift in the semantic representation of words in the LM, as well as how it affects the performance of the agent in tasks that are semantically similar to the training games. We believe these results may help develop better strategies to fine-tune agents in text-based RL scenarios.
Create account to get full access
Overview
- This paper investigates the effects of fine-tuning large language models for text-based reinforcement learning tasks.
- The researchers explore how fine-tuning impacts the model's performance, sample efficiency, and ability to transfer knowledge to new tasks.
- The findings have implications for the use of language models in interactive, goal-oriented applications.
Plain English Explanation
Large language models like GPT-3 have shown impressive capabilities in generating human-like text, but applying them to interactive, goal-oriented tasks like reinforcement learning can be challenging. <a href="https://aimodels.fyi/papers/arxiv/understanding-catastrophic-forgetting-language-models-via-implicit">This paper examines the effects of fine-tuning language models</a> for text-based reinforcement learning, where the model needs to understand language instructions and interact with an environment to achieve specific objectives.
The researchers find that fine-tuning the language model can improve its performance on these interactive tasks, making it more sample-efficient and able to transfer its skills to new environments. However, they also uncover potential downsides, such as the model forgetting some of its general language understanding capabilities. <a href="https://aimodels.fyi/papers/arxiv/learning-from-failure-integrating-negative-examples-when">This balancing act between specialization and generalization</a> is an important consideration when deploying language models for real-world, interactive applications.
Overall, the paper provides valuable insights into the tradeoffs involved in adapting large language models for text-based reinforcement learning. The findings can help guide the development of more capable and versatile AI agents that can fluently understand and interact with their environment through language.
Technical Explanation
The paper focuses on the effects of fine-tuning large language models, such as GPT-3, for text-based reinforcement learning tasks. In these tasks, the model must understand natural language instructions and interact with a simulated environment to achieve specific goals.
The researchers first establish a baseline by evaluating the performance of a pre-trained language model on a suite of text-based reinforcement learning environments. They then fine-tune the model on a subset of these environments and analyze how this impacts the model's performance, sample efficiency, and ability to transfer its skills to new tasks.
<a href="https://aimodels.fyi/papers/arxiv/knowledgeable-agents-by-offline-reinforcement-learning-from">The fine-tuning process involves training the language model to generate actions</a> that maximize the reward signal in the target environments, while still preserving its general language understanding capabilities.
The results show that fine-tuning can indeed improve the model's performance on the target tasks, making it more sample-efficient and better able to adapt to new environments. However, the researchers also observe a degree of "catastrophic forgetting," where the fine-tuned model loses some of its general language skills compared to the pre-trained version.
<a href="https://aimodels.fyi/papers/arxiv/curious-decline-linguistic-diversity-training-language-models">This tradeoff between specialization and generalization</a> is a key finding, as it highlights the challenges of adapting large language models for interactive, goal-oriented applications. The paper discusses potential solutions, such as more sophisticated fine-tuning techniques or architectural modifications, that could help address this issue.
Critical Analysis
The paper provides a thorough and well-designed study of the effects of fine-tuning language models for text-based reinforcement learning. The experimental setup is sound, and the researchers present a comprehensive set of results and analyses.
One potential limitation is the use of a single language model (GPT-3) and a specific set of text-based reinforcement learning environments. <a href="https://aimodels.fyi/papers/arxiv/automating-research-synthesis-domain-specific-large-language">It would be valuable to explore how the findings generalize to other language models and a wider range of interactive environments</a>, to better understand the broader implications of this work.
Additionally, the paper does not delve deeply into the underlying mechanisms and architectural factors that contribute to the observed tradeoffs between specialization and generalization. Further research exploring these mechanisms could provide more nuanced insights and potential solutions to the challenge of adapting language models for interactive applications.
Overall, the paper makes a valuable contribution to the understanding of language model fine-tuning for text-based reinforcement learning. The findings highlight important considerations for the development of more capable and versatile AI agents that can fluently interact with their environment through natural language.
Conclusion
This paper investigates the effects of fine-tuning large language models, such as GPT-3, for text-based reinforcement learning tasks. The researchers find that fine-tuning can improve the model's performance and sample efficiency on the target tasks, but also leads to a degree of "catastrophic forgetting" of the model's general language understanding capabilities.
This tradeoff between specialization and generalization is a key insight, with important implications for the deployment of language models in interactive, goal-oriented applications. The paper suggests that further research is needed to explore more sophisticated fine-tuning techniques and architectural modifications that could help address this challenge.
Overall, the findings contribute to a better understanding of the strengths and limitations of using large language models for interactive, text-based AI applications. This knowledge can inform the development of more capable and versatile AI agents that can fluently understand and interact with their environment through natural language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
0
0
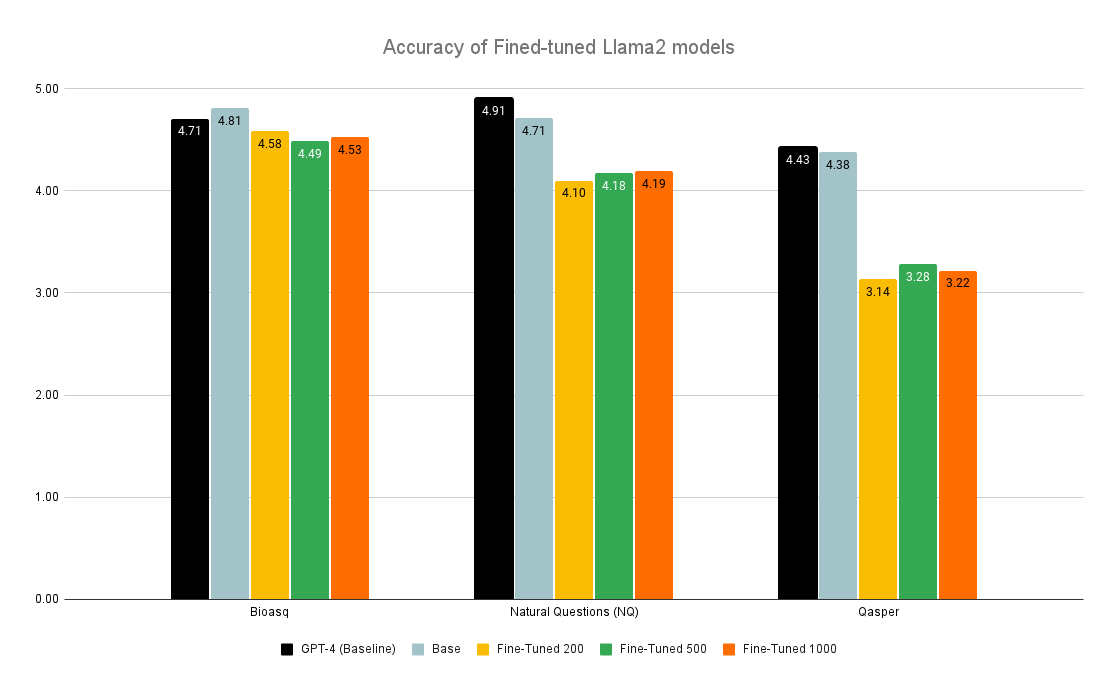
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
6/18/2024

Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
Yuexiang Zhai, Hao Bai, Zipeng Lin, Jiayi Pan, Shengbang Tong, Yifei Zhou, Alane Suhr, Saining Xie, Yann LeCun, Yi Ma, Sergey Levine
0
0
Large vision-language models (VLMs) fine-tuned on specialized visual instruction-following data have exhibited impressive language reasoning capabilities across various scenarios. However, this fine-tuning paradigm may not be able to efficiently learn optimal decision-making agents in multi-step goal-directed tasks from interactive environments. To address this challenge, we propose an algorithmic framework that fine-tunes VLMs with reinforcement learning (RL). Specifically, our framework provides a task description and then prompts the VLM to generate chain-of-thought (CoT) reasoning, enabling the VLM to efficiently explore intermediate reasoning steps that lead to the final text-based action. Next, the open-ended text output is parsed into an executable action to interact with the environment to obtain goal-directed task rewards. Finally, our framework uses these task rewards to fine-tune the entire VLM with RL. Empirically, we demonstrate that our proposed framework enhances the decision-making capabilities of VLM agents across various tasks, enabling 7b models to outperform commercial models such as GPT4-V or Gemini. Furthermore, we find that CoT reasoning is a crucial component for performance improvement, as removing the CoT reasoning results in a significant decrease in the overall performance of our method.
5/20/2024
Mental Modeling of Reinforcement Learning Agents by Language Models
Wenhao Lu, Xufeng Zhao, Josua Spisak, Jae Hee Lee, Stefan Wermter
0
0
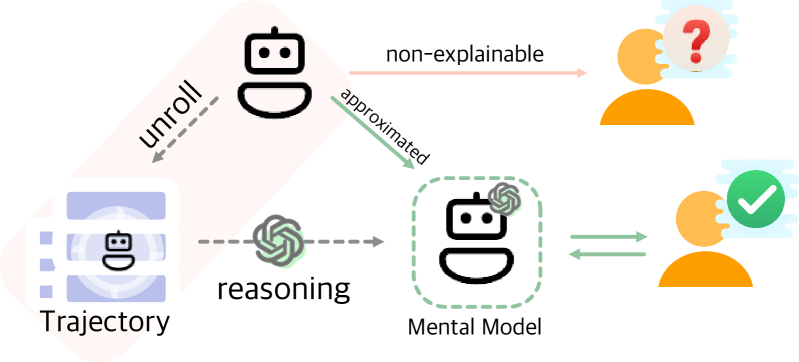
Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
6/27/2024

Towards Generalizable Agents in Text-Based Educational Environments: A Study of Integrating RL with LLMs
Bahar Radmehr, Adish Singla, Tanja Kaser
0
0
There has been a growing interest in developing learner models to enhance learning and teaching experiences in educational environments. However, existing works have primarily focused on structured environments relying on meticulously crafted representations of tasks, thereby limiting the agent's ability to generalize skills across tasks. In this paper, we aim to enhance the generalization capabilities of agents in open-ended text-based learning environments by integrating Reinforcement Learning (RL) with Large Language Models (LLMs). We investigate three types of agents: (i) RL-based agents that utilize natural language for state and action representations to find the best interaction strategy, (ii) LLM-based agents that leverage the model's general knowledge and reasoning through prompting, and (iii) hybrid LLM-assisted RL agents that combine these two strategies to improve agents' performance and generalization. To support the development and evaluation of these agents, we introduce PharmaSimText, a novel benchmark derived from the PharmaSim virtual pharmacy environment designed for practicing diagnostic conversations. Our results show that RL-based agents excel in task completion but lack in asking quality diagnostic questions. In contrast, LLM-based agents perform better in asking diagnostic questions but fall short of completing the task. Finally, hybrid LLM-assisted RL agents enable us to overcome these limitations, highlighting the potential of combining RL and LLMs to develop high-performing agents for open-ended learning environments.
5/1/2024