Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
2406.11201
0
0
Abstract
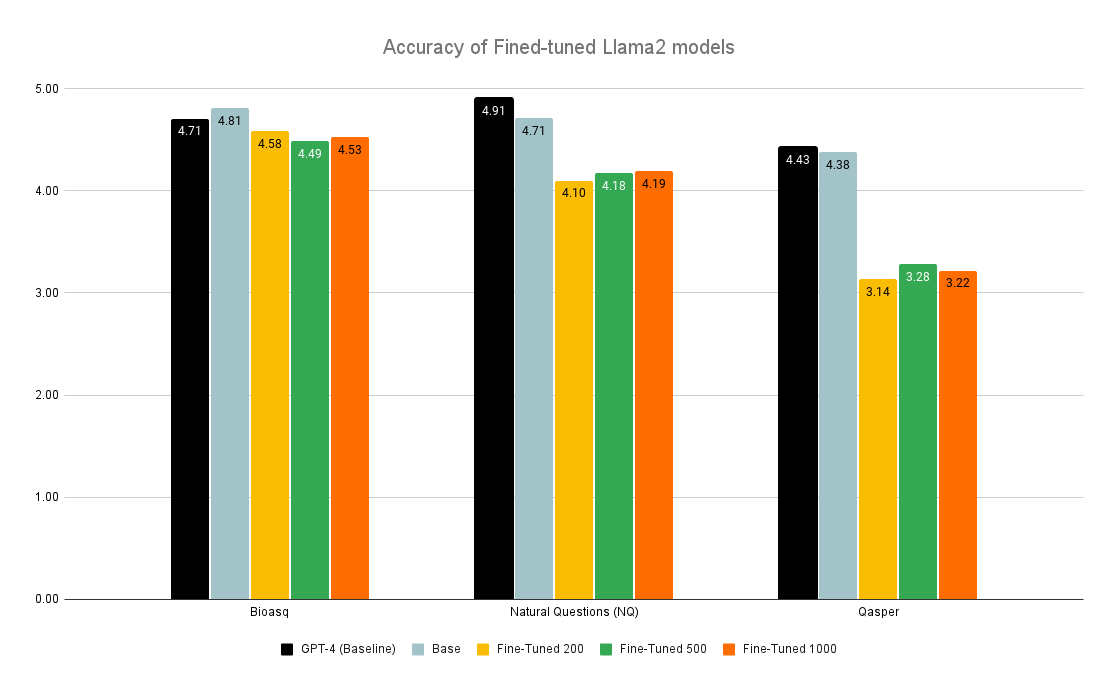
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
Create account to get full access
Overview
- This paper examines common myths and misconceptions about fine-tuning large language models (LLMs).
- The authors present empirical evidence to challenge the popular belief that fine-tuning LLMs always improves performance.
- They explore various fine-tuning approaches and their impacts on model performance across different tasks and datasets.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful and versatile tools for a wide range of natural language processing tasks. A common practice is to "fine-tune" these pre-trained models on specific datasets or tasks to further improve their performance.
However, this paper argues that the benefits of fine-tuning are often overstated. The authors present evidence that fine-tuning doesn't always lead to better results, and in some cases can even harm the model's performance. They explore different fine-tuning approaches and show that the outcomes can vary depending on the task, dataset, and other factors.
For example, the paper discusses how fine-tuning an LLM on a small dataset may result in the model "forgetting" some of the broader, more general knowledge it had learned during the initial pre-training. This can actually make the model perform worse on certain tasks compared to the original pre-trained version.
The key takeaway is that fine-tuning is a complex process that requires careful consideration. Simply assuming that fine-tuning will automatically improve an LLM's performance is a dangerous myth that this paper aims to debunk. Researchers and practitioners need to thoroughly evaluate the tradeoffs and potential pitfalls of fine-tuning before applying it to their specific use cases.
Technical Explanation
The paper begins by acknowledging the widespread belief that fine-tuning large language models (LLMs) is an effective way to boost their performance on specific tasks. However, the authors argue that this belief is not always supported by empirical evidence and that the nuances of fine-tuning are often overlooked.
To investigate this, the researchers conducted a series of experiments across a range of tasks and datasets, comparing the performance of pre-trained LLMs to their fine-tuned counterparts. The tasks included text classification, question answering, and language generation, using both in-domain and out-of-domain datasets.
The results reveal that fine-tuning does not always lead to improved performance, and in some cases can even result in a significant decline. The authors attribute this to several factors, including the size and quality of the fine-tuning dataset, the degree of domain shift between the pre-training and fine-tuning data, and the complexity of the fine-tuning task.
For example, the paper discusses how fine-tuning an LLM on a small dataset can cause the model to "overfit" and lose some of the broader, more general knowledge it had acquired during pre-training. This can negatively impact the model's performance on out-of-domain tasks or datasets.
The authors also explore the impact of different fine-tuning approaches, such as layer-wise fine-tuning and prompt-based fine-tuning. They find that these methods can have varying degrees of success, depending on the specific task and dataset.
Overall, the key technical insight from this paper is that the benefits of fine-tuning LLMs are not as straightforward as commonly believed. The researchers provide empirical evidence to challenge the assumption that fine-tuning will always improve model performance and highlight the importance of carefully considering the nuances of the fine-tuning process.
Critical Analysis
The paper presents a well-designed and thorough investigation of the fine-tuning process for large language models, challenging the widespread belief that it is a reliable way to boost performance. The authors' use of a diverse set of tasks and datasets to evaluate the impact of fine-tuning is commendable, as it provides a more comprehensive understanding of the nuances involved.
One potential limitation of the study is that it focuses mainly on the performance of fine-tuned models, without delving deeper into the underlying mechanisms or factors that contribute to the observed outcomes. For example, the paper could have explored how fine-tuning affects the model's internal representations or the distribution of its predictions, which could provide additional insights into the fine-tuning process.
Additionally, the paper does not address the potential benefits of fine-tuning in specific use cases or scenarios, where the gains may outweigh the risks. It would be valuable for future research to explore the conditions under which fine-tuning is most likely to be successful, rather than simply concluding that it is an unreliable approach.
Despite these minor caveats, the paper makes a significant contribution to the understanding of fine-tuning large language models. By challenging the prevailing narrative and providing empirical evidence, the authors encourage researchers and practitioners to approach fine-tuning with a more nuanced and critical mindset. This is an important step towards developing more robust and reliable language models that can be effectively deployed in real-world applications.
Conclusion
This paper presents a timely and important challenge to the common assumption that fine-tuning large language models (LLMs) is a reliable way to improve their performance. Through a series of carefully designed experiments, the authors demonstrate that fine-tuning does not always lead to better results, and in some cases can even be detrimental to the model's performance.
The key takeaway is that the benefits of fine-tuning are not as straightforward as often believed. Researchers and practitioners need to approach the fine-tuning process with a more critical and nuanced understanding, considering factors such as dataset size, domain shift, and the complexity of the task at hand.
By debunking the "fine-tuning is always better" myth, this paper encourages the AI community to think more deeply about the tradeoffs and potential pitfalls of fine-tuning LLMs. This is an important step towards developing more robust and reliable language models that can be effectively deployed in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

I Learn Better If You Speak My Language: Understanding the Superior Performance of Fine-Tuning Large Language Models with LLM-Generated Responses
Xuan Ren, Biao Wu, Lingqiao Liu
0
0
This paper explores an intriguing observation: fine-tuning a large language model (LLM) with responses generated by a LLM often yields better results than using responses generated by humans. We conduct an in-depth investigation to understand why this occurs. Contrary to the common belief that these instances is simply due to the more detailed nature of LLM-generated content, our study identifies another contributing factor: an LLM is inherently more familiar with LLM generated responses. This familiarity is evidenced by lower perplexity before fine-tuning. We design a series of experiments to understand the impact of the familiarity and our conclusion reveals that this familiarity significantly impacts learning performance. Training with LLM-generated responses not only enhances performance but also helps maintain the model's capabilities in other tasks after fine-tuning on a specific task.
6/4/2024
Should We Fine-Tune or RAG? Evaluating Different Techniques to Adapt LLMs for Dialogue
Simone Alghisi, Massimo Rizzoli, Gabriel Roccabruna, Seyed Mahed Mousavi, Giuseppe Riccardi
0
0
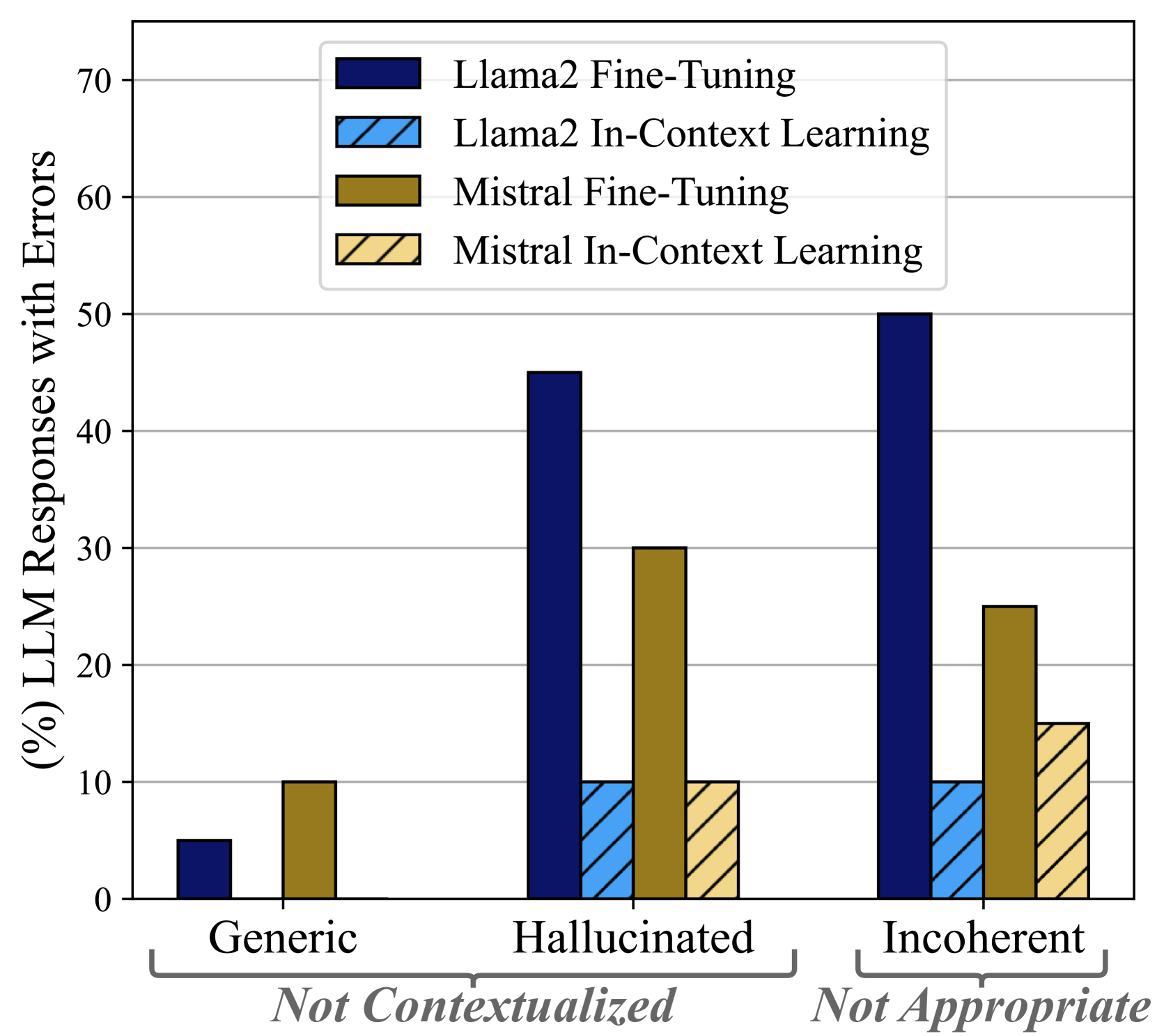
We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue types (e.g., Open-Domain). However, the evaluations of these techniques have been limited in terms of base LLMs, dialogue types and evaluation metrics. In this work, we extensively analyze different LLM adaptation techniques when applied to different dialogue types. We have selected two base LLMs, Llama-2 and Mistral, and four dialogue types Open-Domain, Knowledge-Grounded, Task-Oriented, and Question Answering. We evaluate the performance of in-context learning and fine-tuning techniques across datasets selected for each dialogue type. We assess the impact of incorporating external knowledge to ground the generation in both scenarios of Retrieval-Augmented Generation (RAG) and gold knowledge. We adopt consistent evaluation and explainability criteria for automatic metrics and human evaluation protocols. Our analysis shows that there is no universal best-technique for adapting large language models as the efficacy of each technique depends on both the base LLM and the specific type of dialogue. Last but not least, the assessment of the best adaptation technique should include human evaluation to avoid false expectations and outcomes derived from automatic metrics.
6/11/2024
The Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
David Stap, Eva Hasler, Bill Byrne, Christof Monz, Ke Tran
0
0
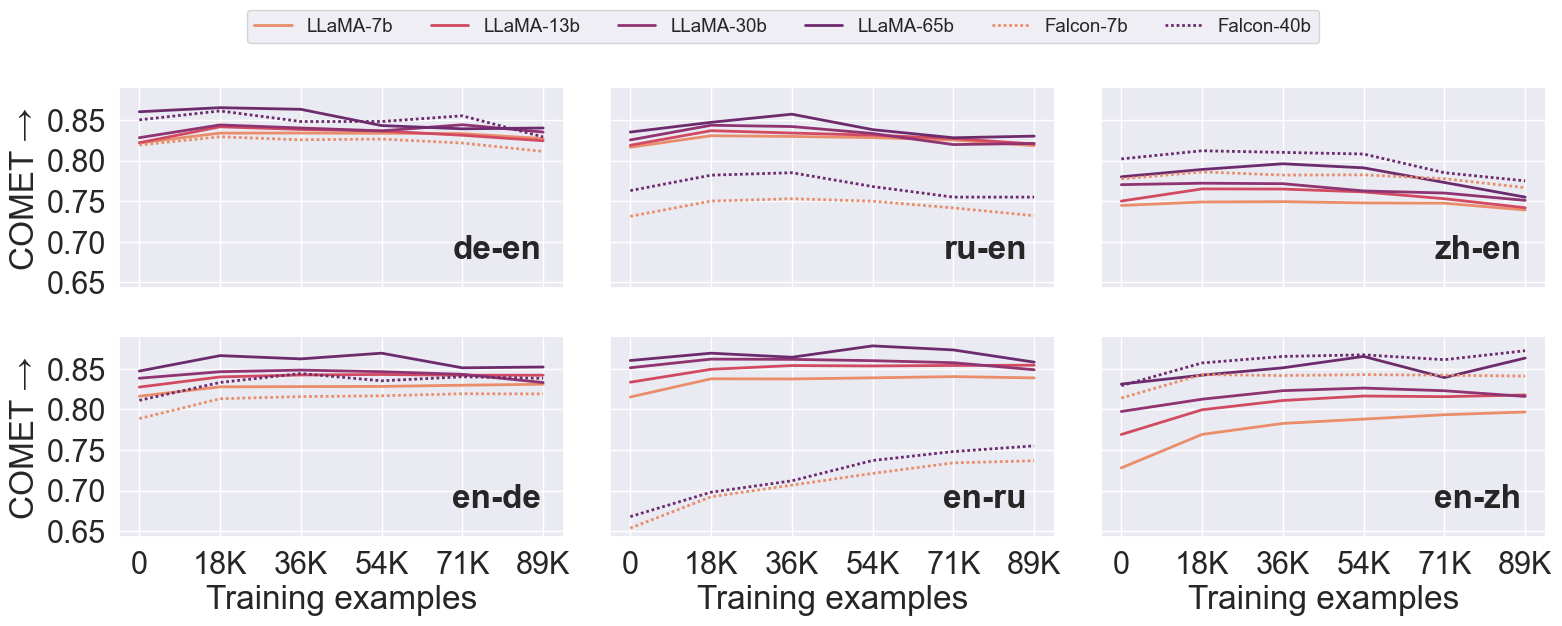
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
5/31/2024
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
0
0
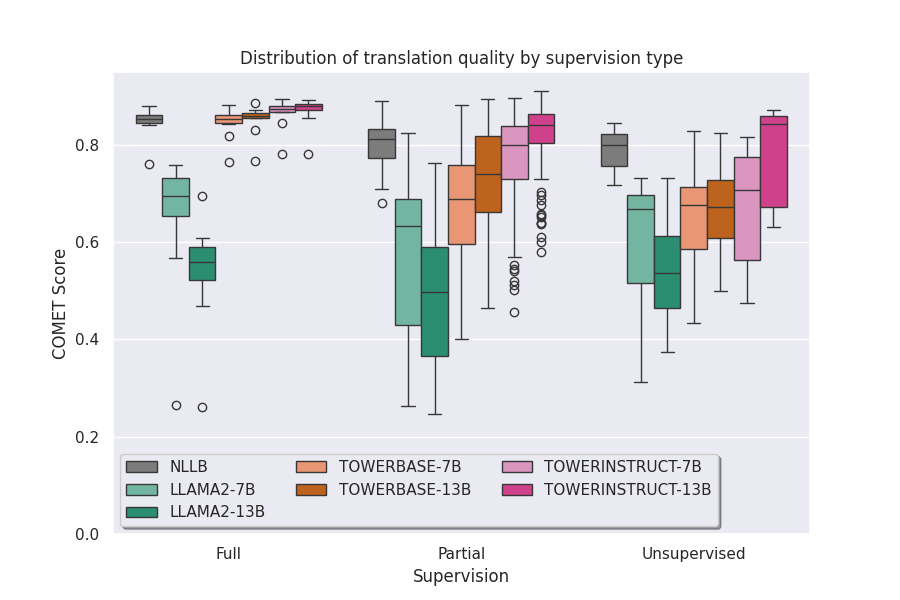
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
6/3/2024