Efficiency optimization of large-scale language models based on deep learning in natural language processing tasks
2405.11704
0
0
🛠️
Abstract
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.
Create account to get full access
Overview
- This paper analyzes the internal structure and operation of large-scale language models, with a focus on how Transformer and its derivative architectures can impact computing efficiency while capturing long-term dependencies.
- It delves into the efficiency bottlenecks during the training phase, evaluating the contributions of adaptive optimization algorithms, parallel computing techniques, and mixed precision training to accelerate convergence and reduce memory footprint.
- The paper also systematically reviews the latest advancements in model compression techniques, such as quantization, pruning, and knowledge distillation, to optimize model deployment and inference.
- Finally, it examines the limitations of current efficiency optimization methods and suggests future research directions.
Plain English Explanation
This paper takes a deep dive into the inner workings of large language models, which are the powerful AI systems that power many of the language-based technologies we use every day, like chatbots, translation tools, and text generation.
The researchers looked at how the core architecture of these models, called the Transformer, can impact their efficiency - that is, how much computing power and memory they require to train and run. They found that while the Transformer is great at capturing long-term relationships in language, it can also be resource-intensive.
To address this, the paper explores various techniques that can be used to make the training and deployment of these models more efficient. This includes using special optimization algorithms that can speed up the training process, leveraging parallel computing power to train the models faster, and using techniques like quantization and pruning to compress the models and make them smaller and faster to run.
The researchers also critically examine the limitations of these efficiency optimization methods, such as the risk of the models becoming too specialized and losing general capability, or the challenge of maintaining model accuracy after compression. They suggest ways that future research could address these issues and continue to improve the efficiency of large language models.
Technical Explanation
The paper begins by analyzing the internal structure and operation mechanisms of large-scale language models, with a particular focus on how Transformer and its derivative architectures can impact computing efficiency while still capturing long-term dependencies in language.
Moving to the training phase, the researchers dive deep into the efficiency bottlenecks, evaluating the contributions of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, the authors reveal how they can effectively improve training efficiency in practice.
For model deployment and inference optimization, the paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, the researchers demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy.
Critical Analysis
The paper acknowledges several limitations of the current efficiency optimization methods. One key issue is the increased risk of overfitting, where the models become too specialized and lose their general capabilities. The authors also note the challenge of controlling performance loss after compression, as well as the problem of algorithm generality - the fact that the techniques may not work equally well across different models and tasks.
Additionally, the paper could have delved deeper into the potential societal implications of these efficiency optimization techniques. For example, while making large language models more computationally efficient is important, there are also concerns around the environmental impact of training and deploying these models, as well as issues of bias and fairness that need to be carefully considered.
Overall, the paper provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models, but there is still room for further research to address the limitations and explore the broader implications of this work.
Conclusion
This study offers a thorough analysis of the internal structure and operation mechanisms of large-scale language models, with a focus on how Transformer and its derivatives can impact computing efficiency. By delving into the training phase, the paper evaluates the contributions of adaptive optimization algorithms, parallel computing techniques, and mixed precision training to improve efficiency.
The paper also provides a comprehensive review of the latest model compression techniques, demonstrating their ability to reduce model size and inference delay while maintaining accuracy. By critically examining the limitations of these efficiency optimization methods, the researchers offer valuable insights and suggest future research directions to address the challenges.
Overall, this study establishes a robust theoretical framework for understanding and advancing the efficiency of large-scale language models, with the potential to drive further advancements in this rapidly evolving field of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
0
0
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
4/9/2024
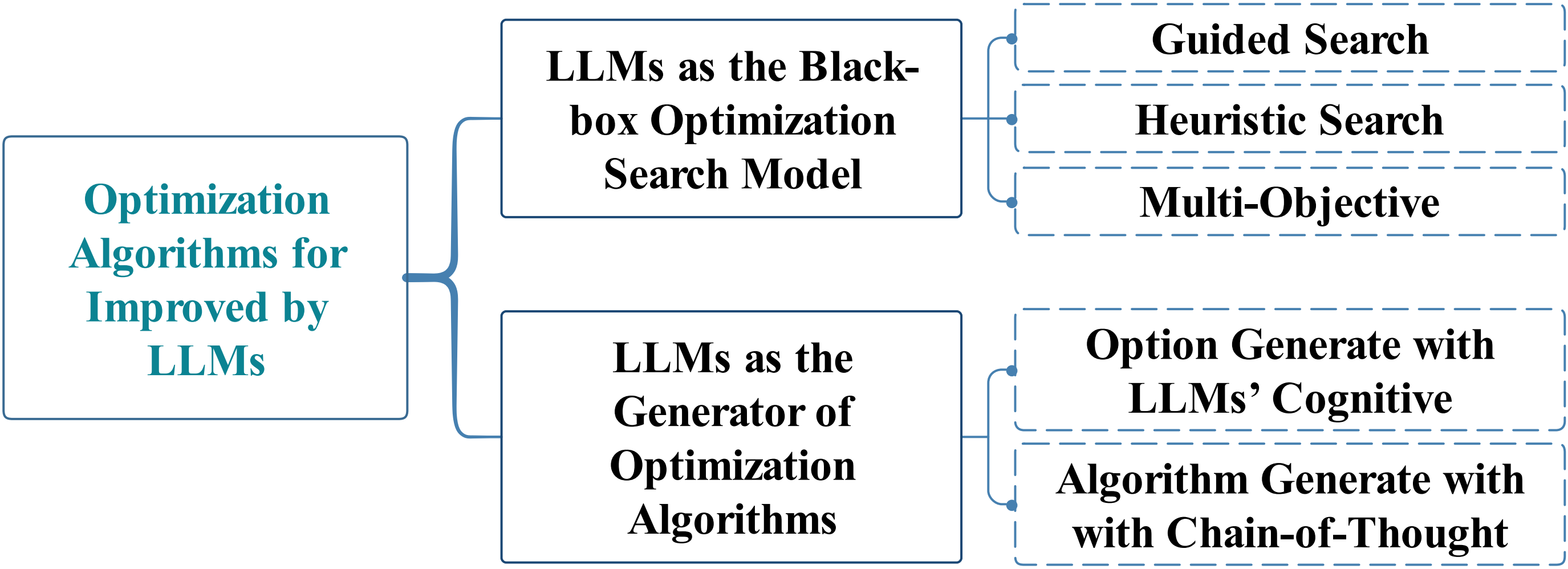
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
0
0
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
5/17/2024