Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
2404.05741
0
0
🤯
Abstract
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores optimization strategies and architectural innovations to enhance the inference efficiency of large language models (LLMs)
- Investigates techniques to improve the computational and energy efficiency of LLMs
- Aims to enable more widespread deployment of powerful LLMs, especially on edge devices with limited resources
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown remarkable capabilities in various natural language processing tasks. However, these models can be computationally and energy-intensive, making it challenging to deploy them on devices with limited resources, such as smartphones or edge computing devices. This research paper explores different strategies to make LLMs more efficient during the inference (or prediction) stage, when the models are used to generate outputs.
The researchers investigate optimization strategies and architectural innovations that can enhance the efficiency of LLMs without significantly compromising their performance. This includes techniques like model compression, architectural modifications, and knowledge distillation. By making LLMs more efficient, the researchers aim to enable their wider deployment, particularly on edge devices with limited computational resources.
The goal is to find ways to bring the powerful capabilities of LLMs to a broader range of applications and devices, while also making them more energy-efficient and environmentally friendly.
Technical Explanation
The paper explores various optimization strategies and architectural innovations to enhance the inference efficiency of large language models (LLMs). The researchers investigate techniques such as model compression, architectural modifications, and knowledge distillation to improve the computational and energy efficiency of LLMs.
The researchers conduct extensive experiments to evaluate the impact of these techniques on the performance and efficiency of LLMs. They explore different model compression approaches, including pruning and quantization, to reduce the model size and computational requirements. The paper also investigates architectural modifications, such as the use of Transformer-Lite modules, to streamline the model structure while maintaining the core functionality.
Additionally, the researchers explore knowledge distillation techniques, where a smaller and more efficient model (the "student") is trained to mimic the behavior of a larger, more powerful model (the "teacher"). This approach allows for the deployment of LLMs on devices with limited resources, as the distilled models are typically much smaller and more computationally efficient.
The findings of the paper provide insights into the trade-offs between model performance, computational efficiency, and energy consumption. The researchers discuss the implications of their work for the wider deployment of LLMs, particularly in edge computing applications, where power and resource constraints are critical.
Critical Analysis
The paper presents a comprehensive investigation into optimization strategies and architectural innovations for enhancing the inference efficiency of large language models (LLMs). The researchers have explored a range of techniques, including model compression, architectural modifications, and knowledge distillation, to address the computational and energy challenges associated with deploying LLMs on resource-constrained devices.
One potential limitation of the research is the extent to which the proposed techniques can be generalized across different LLM architectures and tasks. The paper focuses on specific model designs and optimization approaches, and it would be valuable to understand how these techniques perform when applied to a broader range of LLM models and applications.
Additionally, while the paper discusses the trade-offs between model performance, efficiency, and energy consumption, it would be insightful to delve deeper into the specific use cases and application scenarios where these optimized LLMs might be most beneficial. This could help guide future research and development efforts in this area.
Further exploration of the environmental impact of these optimized LLMs, particularly in terms of their carbon footprint and energy efficiency, could also be a valuable area of investigation. As the field of natural language processing continues to evolve, it will be crucial to consider the sustainability and scalability of these powerful models.
Overall, the research presented in this paper represents an important step towards enabling the wider deployment of LLMs, especially in edge computing and resource-constrained environments. The insights and techniques discussed can serve as a foundation for future work in this rapidly developing field.
Conclusion
This research paper investigates optimization strategies and architectural innovations to enhance the inference efficiency of large language models (LLMs). By exploring techniques such as model compression, architectural modifications, and knowledge distillation, the researchers aim to address the computational and energy challenges associated with deploying powerful LLMs on resource-constrained devices.
The findings of the paper provide valuable insights into the trade-offs between model performance, efficiency, and energy consumption, paving the way for more widespread deployment of LLMs, particularly in edge computing applications. As the field of natural language processing continues to evolve, this work represents an important step towards enabling the use of LLMs in a broader range of real-world scenarios, while also considering the environmental impact and sustainability of these models.
Related Papers
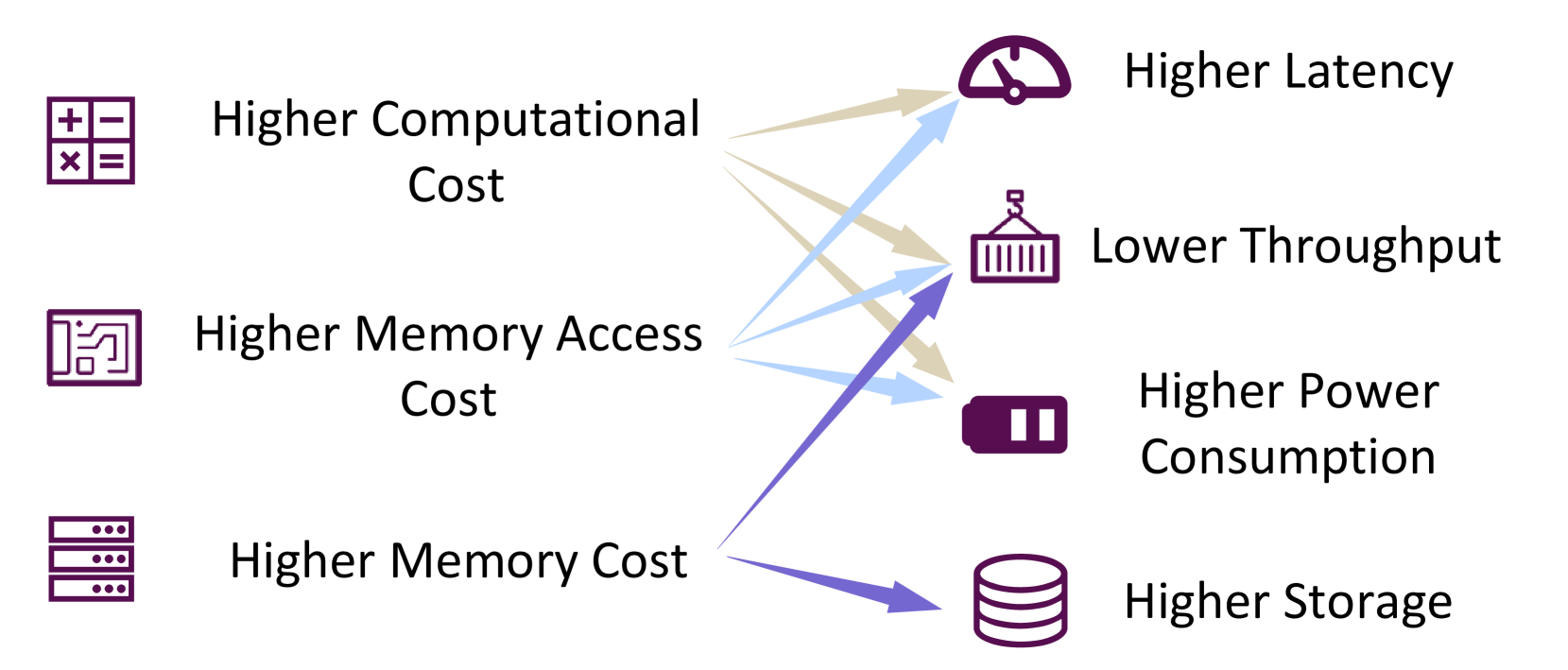
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
4/23/2024
✅
More Compute Is What You Need
Zhen Guo
0
0
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
5/3/2024
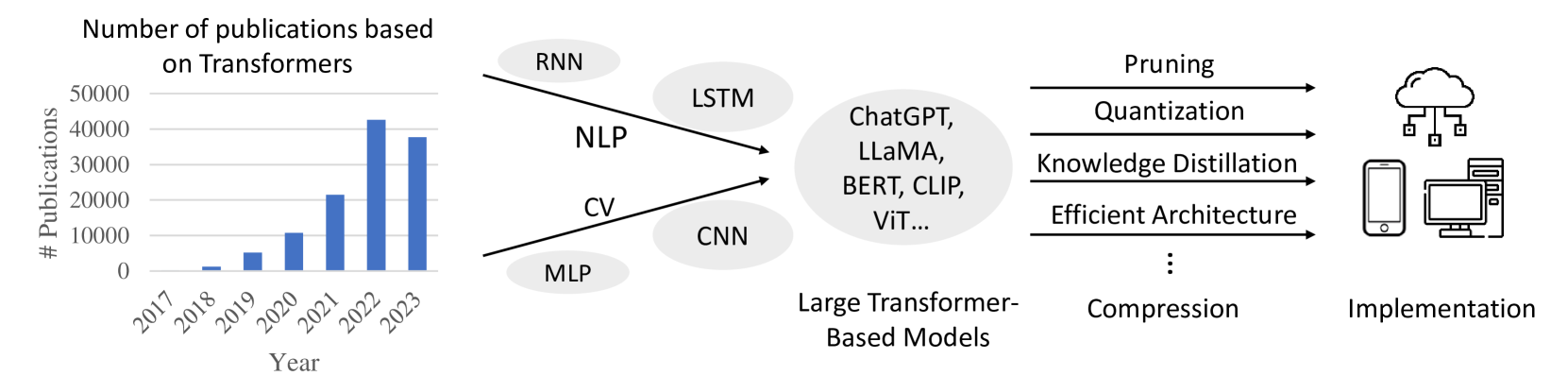
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
0
0
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
4/9/2024
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024