Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning
2406.04413
0
0
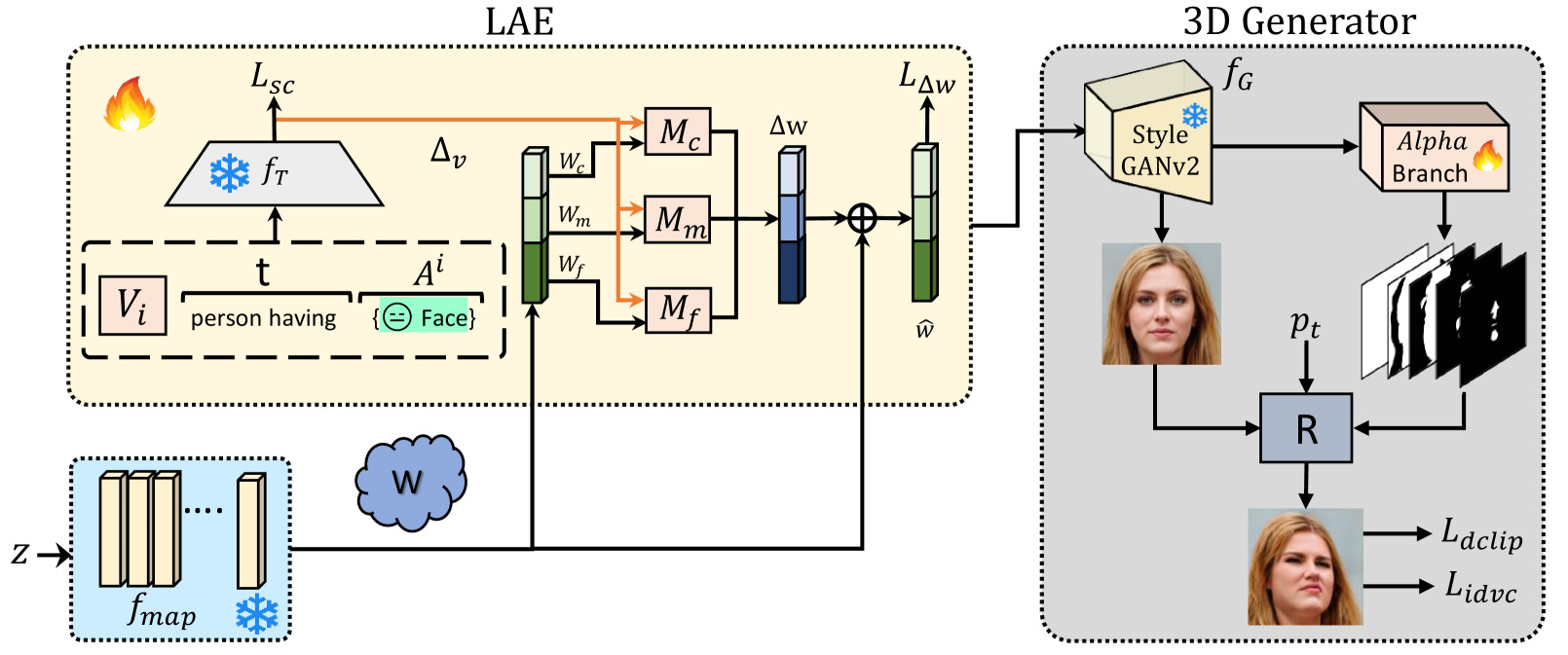
Abstract
Drawing upon StyleGAN's expressivity and disentangled latent space, existing 2D approaches employ textual prompting to edit facial images with different attributes. In contrast, 3D-aware approaches that generate faces at different target poses require attribute-specific classifiers, learning separate model weights for each attribute, and are not scalable for novel attributes. In this work, we propose an efficient, plug-and-play, 3D-aware face editing framework based on attribute-specific prompt learning, enabling the generation of facial images with controllable attributes across various target poses. To this end, we introduce a text-driven learnable style token-based latent attribute editor (LAE). The LAE harnesses a pre-trained vision-language model to find text-guided attribute-specific editing direction in the latent space of any pre-trained 3D-aware GAN. It utilizes learnable style tokens and style mappers to learn and transform this editing direction to 3D latent space. To train LAE with multiple attributes, we use directional contrastive loss and style token loss. Furthermore, to ensure view consistency and identity preservation across different poses and attributes, we employ several 3D-aware identity and pose preservation losses. Our experiments show that our proposed framework generates high-quality images with 3D awareness and view consistency while maintaining attribute-specific features. We demonstrate the effectiveness of our method on different facial attributes, including hair color and style, expression, and others. Code: https://github.com/VIROBO-15/Efficient-3D-Aware-Facial-Image-Editing.
Create account to get full access
Overview
- This paper presents a novel approach for efficient 3D-aware facial image editing using attribute-specific prompt learning.
- The method allows for intuitive and fine-grained control over various facial attributes, such as age, expression, and head pose, by leveraging pre-trained 3D face reconstruction and text-to-image generation models.
- The proposed technique outperforms state-of-the-art methods in terms of both editing quality and efficiency, making it a promising tool for interactive facial image editing applications.
Plain English Explanation
The research paper describes a new way to edit 3D facial images that is more efficient and gives you more control over specific facial features. It uses pre-existing models that can reconstruct 3D faces and generate images from text descriptions. By combining these, the method allows you to easily edit things like a person's age, expression, and head position in an image, without having to do a lot of complex 3D modeling work. This makes the editing process much faster and more intuitive for users, compared to previous techniques. The key innovation is the "attribute-specific prompt learning" approach, which helps the system understand how to make targeted changes to facial features based on text instructions. Overall, this new method represents an important advance in making 3D facial image editing more accessible and powerful for a wide range of applications.
Technical Explanation
The paper introduces a novel approach for Efficient 3D-Aware Facial Image Editing via Attribute-Specific Prompt Learning. The core idea is to leverage pre-trained 3D face reconstruction and text-to-image generation models to enable intuitive and fine-grained control over various facial attributes, such as age, expression, and head pose.
The method first uses a 3D face reconstruction model to extract a detailed 3D representation of the input facial image. It then applies an "attribute-specific prompt learning" technique, where the system learns how to generate text prompts that, when fed into a pre-trained text-to-image model, will produce the desired edits to the 3D face. This allows the user to simply provide high-level instructions, like "make the person look 10 years older," and the system will automatically generate the appropriate 3D edits and render the new image.
Experiments demonstrate that this approach outperforms state-of-the-art methods, such as Mitigating the Impact of Attribute Editing on Face Recognition, Real-Time 3D-Aware Portrait Editing from a Single Image, and MATE3D: Mask-Guided Text-Based 3D-Aware Image Editing, in terms of both editing quality and efficiency. The authors also show how the technique can be integrated with Generative Framework for Self-Supervised Facial Representation Learning and Fast Text-to-3D-Aware Face Generation to enable a wide range of interactive facial image editing applications.
Critical Analysis
The paper presents a compelling approach for efficient 3D-aware facial image editing, but it does acknowledge some limitations. For example, the method relies on the availability of pre-trained 3D face reconstruction and text-to-image generation models, which may not always be accessible or suitable for all use cases.
Additionally, while the experiments demonstrate improved editing quality and efficiency compared to prior methods, the authors note that there is still room for further refinement, particularly in ensuring consistent and realistic edits across a wide range of facial attributes and poses.
It would also be interesting to see the method evaluated on more diverse datasets, beyond the primarily Caucasian faces used in the current study, to assess its robustness and generalization capabilities.
Overall, the research represents an important step forward in making 3D-aware facial image editing more accessible and user-friendly, but continued efforts to address the remaining challenges could further enhance the practical applications of this technology.
Conclusion
This paper presents a novel approach for efficient 3D-aware facial image editing using attribute-specific prompt learning. By leveraging pre-trained 3D face reconstruction and text-to-image generation models, the method enables intuitive and fine-grained control over various facial attributes, such as age, expression, and head pose.
The proposed technique outperforms state-of-the-art methods in terms of both editing quality and efficiency, making it a promising tool for interactive facial image editing applications. While the approach has some limitations, it represents an important advancement in the field of 3D-aware facial image editing, with the potential to unlock new possibilities for personalized digital content creation and virtual communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mitigating the Impact of Attribute Editing on Face Recognition
Sudipta Banerjee, Sai Pranaswi Mullangi, Shruti Wagle, Chinmay Hegde, Nasir Memon
0
0
Through a large-scale study over diverse face images, we show that facial attribute editing using modern generative AI models can severely degrade automated face recognition systems. This degradation persists even with identity-preserving generative models. To mitigate this issue, we propose two novel techniques for local and global attribute editing. We empirically ablate twenty-six facial semantic, demographic and expression-based attributes that have been edited using state-of-the-art generative models, and evaluate them using ArcFace and AdaFace matchers on CelebA, CelebAMaskHQ and LFW datasets. Finally, we use LLaVA, an emerging visual question-answering framework for attribute prediction to validate our editing techniques. Our methods outperform the current state-of-the-art at facial editing (BLIP, InstantID) while improving identity retention by a significant extent.
4/11/2024

Real-time 3D-aware Portrait Editing from a Single Image
Qingyan Bai, Zifan Shi, Yinghao Xu, Hao Ouyang, Qiuyu Wang, Ceyuan Yang, Xuan Wang, Gordon Wetzstein, Yujun Shen, Qifeng Chen
0
0
This work presents 3DPE, a practical method that can efficiently edit a face image following given prompts, like reference images or text descriptions, in a 3D-aware manner. To this end, a lightweight module is distilled from a 3D portrait generator and a text-to-image model, which provide prior knowledge of face geometry and superior editing capability, respectively. Such a design brings two compelling advantages over existing approaches. First, our system achieves real-time editing with a feedforward network (i.e., ~0.04s per image), over 100x faster than the second competitor. Second, thanks to the powerful priors, our module could focus on the learning of editing-related variations, such that it manages to handle various types of editing simultaneously in the training phase and further supports fast adaptation to user-specified customized types of editing during inference (e.g., with ~5min fine-tuning per style). The code, the model, and the interface will be made publicly available to facilitate future research.
4/3/2024
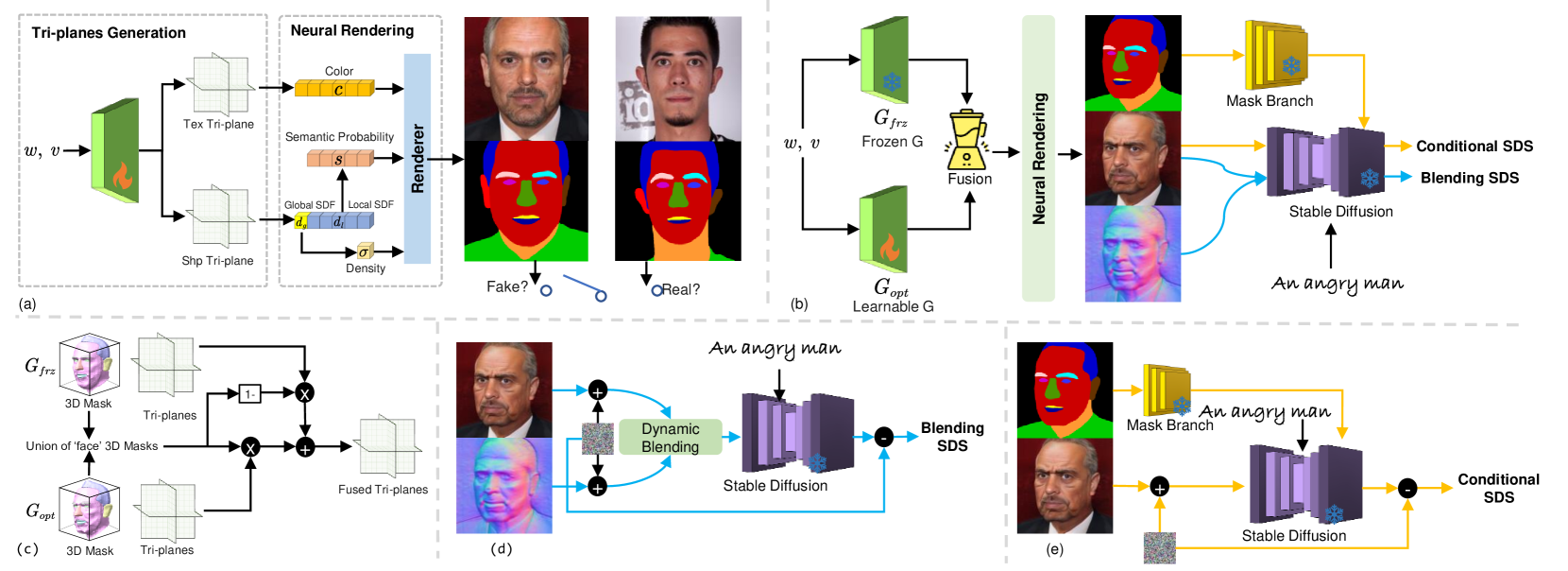
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Kangneng Zhou, Daiheng Gao, Xuan Wang, Jie Zhang, Peng Zhang, Xusen Sun, Longhao Zhang, Shiqi Yang, Bang Zhang, Liefeng Bo, Yaxing Wang, Ming-Ming Cheng
0
0
3D-aware portrait editing has a wide range of applications in multiple fields. However, current approaches are limited due that they can only perform mask-guided or text-based editing. Even by fusing the two procedures into a model, the editing quality and stability cannot be ensured. To address this limitation, we propose textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. In this framework, first, we introduce a new SDF-based 3D generator which learns local and global representations with proposed SDF and density consistency losses. This enhances masked-based editing in local areas; second, we present a novel distillation strategy: Conditional Distillation on Geometry and Texture (CDGT). Compared to exiting distillation strategies, it mitigates visual ambiguity and avoids mismatch between texture and geometry, thereby producing stable texture and convincing geometry while editing. Additionally, we create the CatMask-HQ dataset, a large-scale high-resolution cat face annotation for exploration of model generalization and expansion. We perform expensive experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the editing quality and stability of the proposed method. Our method faithfully generates a 3D-aware edited face image based on a modified mask and a text prompt. Our code and models will be publicly released.
5/6/2024
👀
A Generative Framework for Self-Supervised Facial Representation Learning
Ruian He, Zhen Xing, Weimin Tan, Bo Yan
0
0
Self-supervised representation learning has gained increasing attention for strong generalization ability without relying on paired datasets. However, it has not been explored sufficiently for facial representation. Self-supervised facial representation learning remains unsolved due to the coupling of facial identities, expressions, and external factors like pose and light. Prior methods primarily focus on contrastive learning and pixel-level consistency, leading to limited interpretability and suboptimal performance. In this paper, we propose LatentFace, a novel generative framework for self-supervised facial representations. We suggest that the disentangling problem can be also formulated as generative objectives in space and time, and propose the solution using a 3D-aware latent diffusion model. First, we introduce a 3D-aware autoencoder to encode face images into 3D latent embeddings. Second, we propose a novel representation diffusion model to disentangle 3D latent into facial identity and expression. Consequently, our method achieves state-of-the-art performance in facial expression recognition (FER) and face verification among self-supervised facial representation learning models. Our model achieves a 3.75% advantage in FER accuracy on RAF-DB and 3.35% on AffectNet compared to SOTA methods.
5/24/2024